






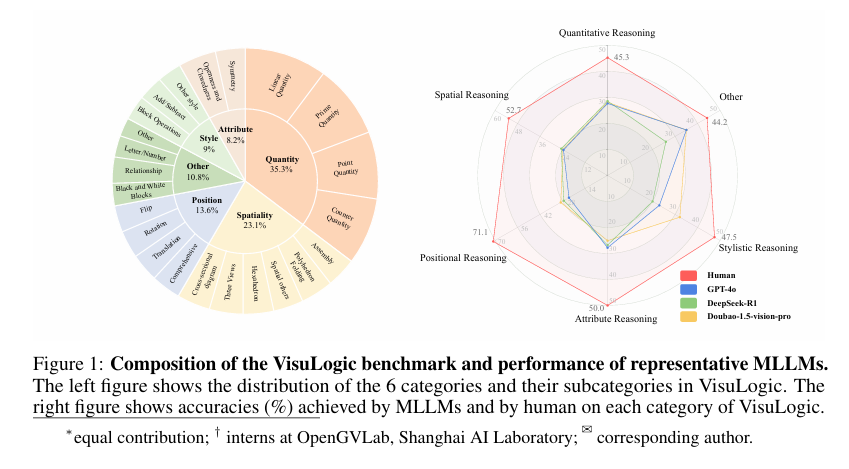
摘要:视觉推理是人类智能的核心组成部分,也是高级多模态模型的关键能力。 然而,目前对多模态大型语言模型(MLLM)的推理评估往往依赖于文本描述,并允许基于语言的推理捷径,无法衡量真正的以视觉为中心的推理。 为了解决这个问题,我们引入了VisuLogic:一个包含六个类别(例如,定量变化、空间关系、属性比较)的1000个人工验证问题的基准。 可以评估这些不同类型的问题,以从多个角度评估MLLM的视觉推理能力。 我们在这个基准上评估了领先的MLLM,并分析了它们的结果,以识别常见的故障模式。 大多数模型的准确率得分低于30%,仅略高于25%的随机基线,远低于人类达到的51.4%的准确率,这表明视觉推理存在重大差距。 此外,我们提供了一个补充训练数据集和一个强化学习基线,以支持进一步的进展。Huggingface链接:Paper page,论文链接:2504.15279
研究背景和目的
研究背景
随着人工智能和自然语言处理技术的飞速发展,多模态大型语言模型(MLLM)在理解和生成文本、图像、音频等多种模态数据方面取得了显著进展。然而,尽管这些模型在多个领域展示了强大的能力,但在视觉推理方面仍存在显著挑战。视觉推理,作为人类智能的核心组成部分,涉及对视觉信息进行深入理解和分析,进而做出逻辑推断。这对于高级多模态模型而言,是评估其是否具备真正智能的关键指标之一。
当前对MLLM的视觉推理能力评估往往依赖于文本描述,这种方法允许模型通过语言捷径来回答问题,而非真正的视觉推理。具体来说,模型可能仅根据问题中的文本线索,而非图像内容本身,来做出判断。这种方法无法准确衡量模型以视觉为中心的推理能力,从而限制了模型在需要深入理解视觉信息的任务中的应用。
研究目的
为了填补这一空白,本研究旨在引入一个全新的基准测试集——VisuLogic,以全面评估MLLM的视觉推理能力。VisuLogic包含1000个人工验证的问题,这些问题跨越六个不同类别,如定量变化、空间关系、属性比较等。通过这些问题的评估,可以从多个角度深入了解MLLM在视觉推理方面的表现,并识别其常见的故障模式。
此外,本研究还希望通过提供补充训练数据集和强化学习基线,为进一步提高MLLM的视觉推理能力提供支持和指导。通过不断优化模型架构和训练策略,推动MLLM在视觉推理领域的发展,最终实现更加智能和高效的多模态信息处理。
研究方法
数据集构建
VisuLogic数据集的构建经历了数据收集、质量控制和详细分类三个阶段。数据收集阶段主要通过自动化脚本从公开在线资源中抓取问题和答案对,并进行初步清洗和结构化处理。质量控制阶段则通过图像验证、重复项移除和人工检查三个步骤来确保数据集的可靠性和有效性。最终,数据被详细分类为六个主要类别,每个类别下的问题都经过专家人工标注和验证。
模型评估
本研究评估了包括开源和闭源在内的多种MLLM在VisuLogic基准上的表现。对于纯文本语言模型(LLM),研究首先使用GPT-4o生成图像描述,然后将该描述与问题一起输入模型进行评估。对于MLLM,则直接输入图像和问题进行评估。此外,研究还采用了三种不同的提示范式(非CoT提示、CoT提示和提示引导)来探索模型推理能力的差异。
强化学习基线
为了进一步提高MLLM的视觉推理能力,本研究还探索了强化学习(RL)方法的应用。具体来说,研究在补充训练数据集上训练了两个RL基线模型,并与全监督微调(SFT)模型进行了比较。通过RL训练,模型学会了如何根据视觉信息进行逐步推理,并不断优化其推理过程以提高准确性。
研究结果
模型性能评估
研究结果显示,当前领先的MLLM在VisuLogic基准上的表现普遍不佳。大多数模型的准确率得分低于30%,仅略高于25%的随机基线,远低于人类达到的51.4%的准确率。这表明MLLM在视觉推理方面仍存在显著差距,需要进一步优化和改进。
错误分析
通过详细分析模型的错误输出,研究识别了多种常见的故障模式。例如,LLM在回答依赖于图像细节的问题时往往表现不佳,因为它们无法从文本描述中提取足够的视觉信息。而MLLM虽然能够处理图像内容,但在处理复杂视觉关系和模式时仍显得力不从心。特别是在空间推理和风格推理类别中,MLLM的错误率甚至超过了随机猜测的水平。
强化学习效果
研究还发现,通过RL训练可以显著提高MLLM的视觉推理能力。具体来说,RL基线模型在VisuLogic基准上的准确率得分显著高于SFT基线模型,表明RL方法在优化模型推理过程方面具有显著优势。此外,RL训练还使模型学会了如何根据提示进行逐步推理,并不断优化其推理路径以提高准确性。
研究局限
尽管本研究在评估MLLM的视觉推理能力方面取得了显著进展,但仍存在一些局限性。首先,VisuLogic基准虽然包含六个不同类别的问题,但可能无法全面覆盖所有可能的视觉推理场景。因此,未来研究需要进一步扩展和完善基准测试集,以更全面地评估MLLM的视觉推理能力。
其次,本研究主要关注了MLLM在单模态视觉推理任务中的表现,而未涉及多模态融合推理。在实际应用中,MLLM往往需要同时处理文本、图像、音频等多种模态的数据,并进行跨模态融合推理。因此,未来研究需要进一步探索MLLM在多模态融合推理方面的表现和优化方法。
此外,本研究采用的RL方法虽然在一定程度上提高了模型的视觉推理能力,但仍存在训练效率低、收敛速度慢等问题。未来研究需要进一步优化RL算法和训练策略,以提高训练效率和模型性能。
未来研究方向
针对上述研究局限,未来研究可以从以下几个方面展开:
-
扩展和完善基准测试集:进一步扩展VisuLogic基准测试集的问题类别和数量,以更全面地覆盖所有可能的视觉推理场景。同时,引入更多样化的图像和问题类型,以提高基准测试集的代表性和挑战性。
-
探索多模态融合推理:研究MLLM在多模态融合推理方面的表现和优化方法。通过引入跨模态注意力机制、多模态融合层等技术手段,实现文本、图像、音频等多种模态数据的有效融合和推理。
-
优化强化学习算法:针对当前RL方法存在的问题,进一步优化算法设计和训练策略。例如,引入更高效的样本选择策略、更稳定的训练过程控制方法以及更先进的模型架构等,以提高RL训练效率和模型性能。
-
结合人类反馈进行模型优化:研究如何结合人类反馈来进一步优化MLLM的视觉推理能力。通过引入人类专家对模型输出的评估和反馈机制,指导模型进行有针对性的改进和优化。同时,探索如何将人类知识有效地融入到模型训练中,以提高模型的泛化能力和鲁棒性。
-
推动模型在实际应用中的落地:最后,未来研究还需要关注如何将优化后的MLLM应用于实际场景中。通过与实际应用的紧密结合和不断迭代优化,推动MLLM在智能医疗、智能交通、智能安防等领域的应用和发展。同时,研究如何保障模型的安全性和隐私性也是未来研究的重要方向之一。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









