






摘要:由于语言的形态丰富,阿拉伯语文本的变音符号仍然是自然语言处理中一个持续的挑战。 在本文中,我们介绍了一种基于微调解码器语言模型的新方法Sadeed,该方法改编自Kuwain 1.5B Hennara等人[2025]的模型,该模型最初是在不同的阿拉伯语语料库上训练的紧凑模型。 Sadeed 经过精心策划的高质量变音数据集的微调,这些数据集是通过严格的数据清理和规范化管道构建的。 尽管使用了适度的计算资源,但与专有的大型语言模型相比,Sadeed取得了具有竞争力的结果,并且优于在类似领域训练的传统模型。 此外,我们强调了当前阿拉伯语变音基准测试实践中的主要局限性。 为了解决这些问题,我们引入了SadeedDiac-25,这是一个新的基准,旨在在不同的文本类型和复杂程度之间进行更公平、更全面的评估。 Sadeed和SadeedDiac-25共同为推进阿拉伯语NLP应用提供了坚实的基础,包括机器翻译、文本到语音和语言学习工具。Huggingface链接:Paper page,论文链接:2504.21635
研究背景和目的
研究背景
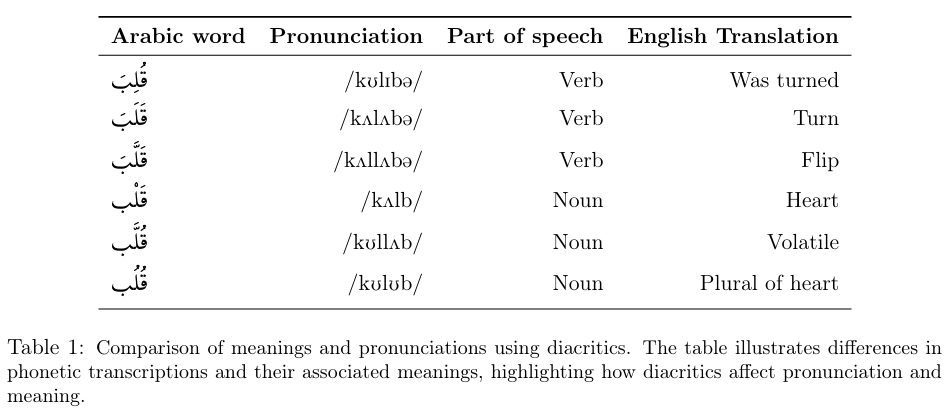
阿拉伯语作为一种形态丰富的语言,其文本变音符号(Diacritization)在自然语言处理(NLP)领域一直是一个持续的挑战。变音符号在阿拉伯语中起着至关重要的作用,它们不仅用于区分具有相同辅音结构但意义和发音不同的单词,还是文本消歧、提高机器翻译、文本到语音(TTS)合成、词性标注等NLP任务准确性的关键。然而,由于现代阿拉伯语书写中经常省略变音符号以节省时间和空间,导致带变音符号的标注数据稀缺,这增加了阿拉伯语变音符号自动标注的难度。
此外,阿拉伯语文本存在古典阿拉伯语(CA)和现代标准阿拉伯语(MSA)两种主要书写风格,大多数现有的变音符号数据集集中在古典阿拉伯语上,而基于这些数据训练的模型在现代标准阿拉伯语上的表现往往不佳。同时,准确的变音符号标注往往需要理解整个句子的上下文,这也是现有模型中经常被忽视的因素。
研究目的
本研究的主要目的是通过引入一种基于小型语言模型(SLM)的新方法Sadeed,来推进阿拉伯语变音符号的自动标注。Sadeed模型基于Kuwain 1.5B Hennara等人[2025]的预训练模型,经过微调以适应阿拉伯语变音符号标注任务。此外,本研究还旨在解决当前阿拉伯语变音符号基准测试中的局限性,通过提出一个新的基准SadeedDiac-25,以实现更公平、更全面的评估。
研究方法
数据集构建
为了训练Sadeed模型,研究者们利用了Tashkeela语料库和阿拉伯树库(ATB-3)等公开数据集。然而,这些数据集存在质量问题,如文本质量差、变音符号不一致等。因此,研究者们实施了一个严格的数据预处理管道,包括文本清理、标准化和文本分块等步骤,以确保数据的一致性和可靠性。
- 文本清理:通过应用与Kuwain模型预训练相同的严格清理函数,并添加额外的标准化步骤来确保变音符号的一致性。
- 文本分块:将语料库分割成50-60个单词的连贯块,同时尽量保持句法依赖关系。
- 数据集过滤:排除包含两个以上未标注变音符号单词的示例,确保训练样本的变音符号完整性。
最终得到的数据集包含约104万个示例,总计约5300万个单词,并被公开发布以支持模型训练和评估。
模型训练
Sadeed模型是基于Kuwain 1.5B Hennara等人[2025]的预训练模型进行微调的。微调过程被仔细设计以优化模型在阿拉伯语变音符号标注任务上的性能。具体来说,研究者们将变音符号标注任务重新表述为一个问答(QA)任务,利用模型的生成能力进行更聚焦和高效的训练。在整个训练数据集上应用了一致的模板转换,以适应专门的变音符号标注任务。
训练过程中使用了标准的下一标记预测方法,并监控验证损失以防止过拟合。最佳检查点根据训练过程中获得的最低验证损失进行选择。
基准测试
为了评估Sadeed模型的性能,研究者们在多个基准测试集上进行了实验,包括Fadel基准测试集、WikiNews基准测试集以及新提出的SadeedDiac-25基准测试集。SadeedDiac-25基准测试集旨在提供一个更公平、更全面的评估框架,它结合了古典阿拉伯语和现代标准阿拉伯语文本,并经过专家仔细审查以确保准确性和可靠性。
研究结果
在Fadel基准测试集上的表现
在Fadel基准测试集上,Sadeed模型在词错误率(WER)和变音符号错误率(DER)方面取得了具有竞争力的结果。特别是在排除未标注变音符号字符的情况下,Sadeed在WER方面达到了最先进的性能。这表明Sadeed模型在处理阿拉伯语变音符号标注任务时具有很高的准确性和鲁棒性。
在WikiNews基准测试集上的表现
在WikiNews基准测试集上,Sadeed模型也取得了具有竞争力的性能,尽管没有超过某些专门针对现代标准阿拉伯语训练的模型。这表明Sadeed模型在处理现代标准阿拉伯语文本时仍有一定的提升空间。
在SadeedDiac-25基准测试集上的表现
在SadeedDiac-25基准测试集上,Sadeed模型与领先的专有大型语言模型(如Claude3.7Sonnet、GPT-4等)以及开源阿拉伯语模型进行了比较。结果显示,Claude3.7Sonnet在所有评估指标上均表现最佳,而Sadeed模型在开源模型中表现最强,甚至与某些专有模型相比也具有竞争力。然而,Sadeed模型的主要局限性在于其幻觉率较高,这可能是由于模型规模相对较小所致。
研究局限
模型幻觉
Sadeed模型在生成变音符号标注文本时存在一定的幻觉问题,即生成与输入文本不完全匹配的输出。这可能是由于模型规模较小或训练数据有限所致。为了解决这个问题,研究者们使用了Needleman-Wunsch对齐算法来自动纠正结构差异,同时保留模型生成的变音符号。
现代标准阿拉伯语数据不足
尽管Sadeed模型在古典阿拉伯语变音符号标注任务上表现出色,但在现代标准阿拉伯语上的表现仍有待提高。这主要是由于现代标准阿拉伯语标注数据的稀缺性所致。为了解决这个问题,研究者们计划扩展数据集,增加经过仔细标注的现代标准阿拉伯语文本。
基准测试局限性
当前阿拉伯语变音符号基准测试中存在一些局限性,如数据集之间的重叠、标注错误以及领域多样性不足等。这些问题可能导致模型性能评估的不准确和误导性结论。为了解决这些问题,研究者们提出了SadeedDiac-25基准测试集,旨在提供一个更公平、更全面的评估框架。
未来研究方向
扩大模型规模
为了减少模型幻觉并提高性能,未来可以考虑扩大Sadeed模型的规模。通过增加模型参数和训练数据量,可以期望模型在生成变音符号标注文本时更加准确和可靠。然而,这也将带来计算资源和效率方面的挑战。
增加现代标准阿拉伯语数据
为了解决现代标准阿拉伯语数据不足的问题,未来可以致力于收集和标注更多的现代标准阿拉伯语文本。这可以通过与语言学家和领域专家合作来实现,以确保标注数据的准确性和可靠性。
改进基准测试
为了进一步提高阿拉伯语变音符号标注模型的评估准确性,未来可以致力于改进基准测试方法。这包括开发新的基准测试集、采用更严格的评估指标以及实施更全面的数据集审查流程。通过这些措施,可以期望为阿拉伯语变音符号标注模型的研究和开发提供更坚实的基础。
探索新的模型架构和技术
除了扩大模型规模和增加训练数据外,未来还可以探索新的模型架构和技术来提高阿拉伯语变音符号标注的性能。例如,可以尝试将注意力机制、自监督学习或迁移学习等技术应用于阿拉伯语变音符号标注任务中,以期望获得更好的性能表现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









