






摘要:数据混合策略成功地降低了训练语言模型的成本。 虽然有希望,但这种方法有两个缺陷。 首先,它们依赖于预先确定的数据域(例如数据源、任务类型),这可能无法捕捉关键的语义细微差别,从而影响性能。 其次,这些方法会随着计算中域的数量而扩展,这是不可行的。 我们通过R&B来应对这些挑战,R&B是一个基于语义相似性(Regroup)重新划分训练数据的框架,以创建更细粒度的域,并通过利用在整个训练过程中获得的域梯度诱导的Gram矩阵来有效地优化数据组合(Balance)。 与先前的工作不同,它消除了对额外计算的需求,以获得损失或梯度等评估信息。 我们在标准规则条件下分析了这种技术,并提供了理论见解,证明了R&B与非自适应混合方法相比的有效性。 从经验上讲,我们证明了R&B在五个不同数据集上的有效性,这些数据集从自然语言到推理和多模态任务。 只需0.01%的额外计算开销,R&B就能达到或超过最先进的数据混合策略的性能。Huggingface链接:Paper page,论文链接:2505.00358
研究背景和目的
研究背景
随着大型语言模型(LLMs)的兴起,基础模型(Foundation Models)的训练对数据的需求急剧增加。这些模型依赖于庞大且多样化的数据集,但通用基础模型的发展带来了一个根本性的不平衡:潜在的训练数据量远远超过了可用的计算资源。这种不平衡促使了数据高效策略的发展,旨在最大化性能的同时最小化计算成本。数据混合(Data Mixing)策略作为一种有前景的方法,通过优化训练数据的组成而非单纯增加其数量,实现了在显著减少计算资源的情况下达到可比或更优的性能。
然而,现有的数据混合方法存在两个主要缺陷。首先,它们依赖于预先确定的数据域(如数据源、任务类型),这些域可能无法捕捉到关键的语义细微差别,从而限制了模型性能的提升。其次,随着域数量的增加,这些方法的计算成本变得难以承受。因此,如何设计一种既高效又能捕捉数据语义结构的数据混合策略,成为了当前研究的重要课题。
研究目的
本研究旨在通过提出一种名为R&B(Regroup & Balance)的框架,解决现有数据混合策略中的上述问题。R&B框架通过两个阶段来优化数据混合:首先,基于语义相似性重新划分训练数据,创建更细粒度的域(Regroup);其次,利用训练过程中获得的域梯度诱导的Gram矩阵,高效地优化数据组成(Balance)。研究的主要目的包括:
- 提高数据混合策略的效率:通过消除对额外计算的需求来获取评估信息(如损失或梯度),R&B旨在显著降低数据混合过程中的计算开销。
- 捕捉数据中的语义结构:通过基于语义相似性重新划分数据域,R&B旨在捕捉到更精细的语义结构,从而提升模型性能。
- 验证R&B框架的有效性:通过在多个不同数据集上的实验,验证R&B在自然语言处理、推理和多模态任务中的性能表现。
研究方法
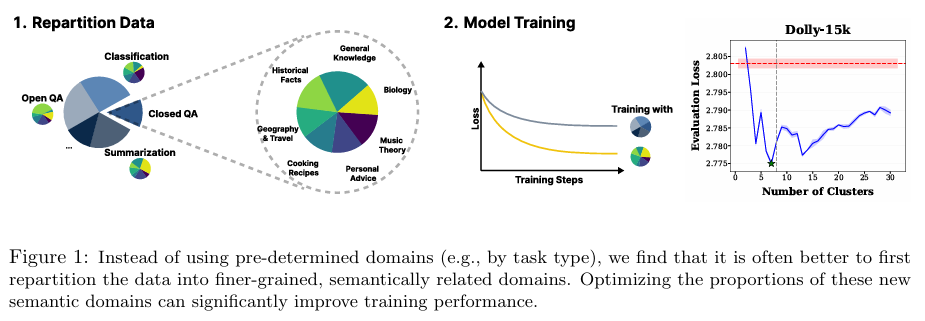
数据预处理与域划分(Regroup)
R&B框架的第一步是基于语义相似性重新划分训练数据。具体而言,研究采用了以下步骤:
- 数据嵌入:使用现代BERT嵌入模型(ModernBERT-embed)对训练数据进行嵌入,生成高维向量表示。
- 聚类分析:利用k-means聚类算法对嵌入后的数据进行聚类,生成多个细粒度的数据域。聚类数量(k)的选择通过实验确定,以找到最佳的性能平衡点。
- 域标签分配:根据聚类结果,为每个数据点分配域标签,形成新的数据域划分。
数据组成优化(Balance)
R&B框架的第二步是利用训练过程中获得的域梯度诱导的Gram矩阵,高效地优化数据组成。具体而言,研究采用了以下方法:
- 梯度积累:在训练过程中,对每个数据域的梯度进行积累,形成域梯度向量。
- Gram矩阵构建:利用积累的域梯度向量,构建Gram矩阵,该矩阵反映了不同域梯度之间的相似性。
- 采样分布更新:基于Gram矩阵和预定义的评估比例,通过softmax操作更新采样分布,使模型在训练过程中更关注于贡献最大的数据域。
实验设计
为了验证R&B框架的有效性,研究在五个不同数据集上进行了实验,包括自然语言处理、推理和多模态任务。实验设计包括以下几个方面:
- 基线方法:选择了四种基线方法进行比较,包括分层抽样(Stratified Sampling)、Skill-It、Aioli和DGA。
- 模型选择:在自然语言处理任务中,使用了125M的GPT-Neo模型;在推理任务中,使用了Qwen2-0.5B模型;在多模态任务中,训练了CLIP模型。
- 评估指标:主要评估指标为评估损失(Evaluation Loss),并计算了相对于标准训练的额外计算开销(Compute Overhead)。
研究结果
自然语言处理任务
在自然语言处理任务中,R&B框架在三个数据集(Dolly-15k、Sup-NatInst和Sup-NatInst Test)上均取得了显著的性能提升。具体而言:
- 评估损失降低:在所有数据集上,R&B均实现了最低的评估损失,表明其能够更有效地利用训练数据。
- 计算开销降低:与基线方法相比,R&B的计算开销显著降低。例如,在Sup-NatInst数据集上,R&B的计算开销仅为0.009%,而Skill-It和Aioli的计算开销则高达数百倍。
- 域划分效果:通过聚类分析重新划分的数据域显著优于原始数据域,表明基于语义相似性的域划分能够捕捉到更关键的语义结构。
推理任务
在推理任务中,R&B框架在S1-59K数据集上取得了与分层抽样相当的性能,但在数据域重新划分后,性能有所提升。这表明,虽然推理任务的数据特性与自然语言处理任务有所不同,但R&B框架仍然能够有效地优化数据组成。
多模态任务
在多模态任务中,R&B框架在CLIP模型的训练中表现出了显著的优势。特别是在数据域数量超过10个时,R&B的性能提升更为明显。这表明,R&B框架能够有效地处理多模态数据中的复杂语义关系,并通过优化数据组成来提升模型性能。
研究局限
尽管R&B框架在多个数据集上均取得了显著的性能提升,但本研究仍存在一些局限性:
- 域划分方法的局限性:虽然k-means聚类算法在实验中表现出了良好的性能,但其他聚类算法(如层次聚类、DBSCAN等)可能具有不同的优势。未来研究可以探索更多种类的聚类算法,以找到最适合特定任务的域划分方法。
- 梯度计算的复杂性:虽然R&B框架通过利用训练过程中获得的域梯度来优化数据组成,但梯度计算本身可能具有一定的复杂性。特别是在大规模数据集和复杂模型上,梯度计算可能成为性能瓶颈。未来研究可以探索更高效的梯度计算方法,以进一步提升R&B框架的性能。
- 评估指标的单一性:本研究主要使用评估损失作为评估指标,但模型性能可能受到多种因素的影响。未来研究可以考虑引入更多评估指标(如准确率、召回率、F1分数等),以更全面地评估模型性能。
未来研究方向
基于本研究的结果和局限性,未来研究可以从以下几个方面展开:
-
探索更多种类的聚类算法:未来研究可以探索更多种类的聚类算法(如层次聚类、DBSCAN、谱聚类等),以找到最适合特定任务的域划分方法。通过比较不同聚类算法的性能,可以进一步优化R&B框架的域划分阶段。
-
提升梯度计算的效率:针对梯度计算的复杂性,未来研究可以探索更高效的梯度计算方法。例如,可以利用分布式计算、并行计算等技术来加速梯度计算过程。此外,还可以研究如何利用模型剪枝、量化等技术来减少梯度计算量,从而进一步提升R&B框架的性能。
-
引入更多评估指标:为了更全面地评估模型性能,未来研究可以引入更多评估指标。例如,在自然语言处理任务中,可以考虑引入准确率、召回率、F1分数等指标;在多模态任务中,可以考虑引入图像质量评估、文本相似度评估等指标。通过综合考虑多个评估指标,可以更准确地评估R&B框架在不同任务上的性能表现。
-
扩展R&B框架的应用范围:目前,R&B框架主要在自然语言处理、推理和多模态任务上进行了验证。未来研究可以探索将R&B框架应用于其他领域,如计算机视觉、语音识别等。通过扩展R&B框架的应用范围,可以进一步验证其通用性和有效性。
-
研究R&B框架与其他优化技术的结合:未来研究可以探索将R&B框架与其他优化技术(如课程学习、强化学习等)相结合的可能性。通过结合多种优化技术,可以进一步提升模型性能,并探索更多潜在的应用场景。
-
深入理解R&B框架的工作原理:尽管本研究通过实验验证了R&B框架的有效性,但对其工作原理的深入理解仍然有限。未来研究可以通过理论分析、可视化技术等手段,深入探索R&B框架在不同任务上的工作原理,从而为其进一步优化提供理论支持。
综上所述,本研究提出的R&B框架在数据混合策略中展现出了显著的优势,通过重新划分数据域和优化数据组成,实现了在显著降低计算开销的同时提升模型性能的目标。未来研究可以进一步探索R&B框架的潜力,通过优化域划分方法、提升梯度计算效率、引入更多评估指标等手段,进一步推动数据混合策略的发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









