






摘要:大型推理模型(LRM)已经具备长链推理的潜在能力。 先前的工作表明,基于结果的强化学习(RL)可以偶然引发高级推理行为,如自我纠正、回溯和验证现象,这些现象通常被称为模型的“顿悟时刻”。 然而,这些涌现行为的时间和一致性仍然不可预测和不可控,限制了LRM推理能力的可扩展性和可靠性。 为了解决这些局限性,我们不再依赖提示和偶然的“顿悟时刻”。 相反,我们使用自动生成的可自我验证的任务,将模型与三种元能力(演绎、归纳和溯因)明确地结合起来。 我们的三阶段流水线个体对齐、参数空间合并和特定领域强化学习,相对于指令调整的基线,性能提高了10%以上。 此外,对齐检查点的特定领域强化学习在数学、编码和科学基准测试中的性能上限平均提高了2%,这表明显式元能力对齐为推理提供了可扩展且可靠的基础。 代码可以在以下网址获得:GitHub。Huggingface链接:Paper page,论文链接:2505.10554
研究背景和目的
研究背景
随着人工智能技术的飞速发展,大型推理模型(Large Reasoning Models, LRMs)如OpenAI的o1、o3,DeepSeek的R1,以及Grok 3.5等,已经展现出卓越的长链推理能力。这些模型在处理复杂任务时,能够生成详尽的思维链(Chain-of-Thought, CoT)响应,并表现出类似反思的高级推理行为。特别是,基于结果的强化学习(RL)技术在某些模型中意外地激发了自我纠正、回溯和验证等高级推理行为,这些现象被形象地称为模型的“顿悟时刻”(“aha moment”)。然而,这些涌现行为的时间和一致性难以预测和控制,限制了LRMs推理能力的可扩展性和可靠性。
具体而言,现有的LRMs虽然能够在特定任务上表现出色,但其推理能力的提升往往依赖于偶然的“顿悟时刻”,而非系统性的能力训练。这种不可控性使得模型在不同任务和场景下的表现差异较大,难以保证稳定性和可靠性。此外,传统的基于提示(prompt)的微调方法虽然能够提升模型在特定任务上的性能,但同样缺乏对模型底层推理能力的系统性训练和提升。
研究目的
为了克服上述局限性,本研究旨在通过明确地将LRMs与三种元能力(演绎、归纳和溯因)对齐,来提升模型的推理能力。具体而言,研究目的包括:
- 系统化提升推理能力:通过设计特定的任务和训练方法,使模型能够系统地学习和掌握演绎、归纳和溯因这三种元能力,从而提升其整体推理能力。
- 提高可预测性和可控性:通过明确的任务设计和训练流程,使模型的推理行为更加可预测和可控,减少对偶然“顿悟时刻”的依赖。
- 验证元能力对齐的有效性:通过实验验证,明确元能力对齐是否能够显著提升模型在数学、编码和科学等领域的性能,并评估其可扩展性和可靠性。
研究方法
任务设计
为了实现元能力对齐,研究设计了三种推理任务,分别对应演绎、归纳和溯因这三种元能力:
- 演绎推理任务:采用命题可满足性任务,模型需要验证给定的逻辑规则和假设是否能够推导出特定的观察结果。这种任务要求模型具备严格的预测和验证能力。
- 归纳推理任务:采用掩码序列补全任务,模型需要从部分输入中抽象出潜在的生成规则,并正确补全序列。这种任务旨在提升模型的抽象和泛化能力。
- 溯因推理任务:采用反向规则图搜索任务,模型需要从观察结果出发,通过规则图反向推导出最可能的解释。这种任务促进模型的创造性和逆向推理能力。
所有任务均通过自动化生成和验证,确保大规模、自我检查的训练数据无需人工标注。
训练流程
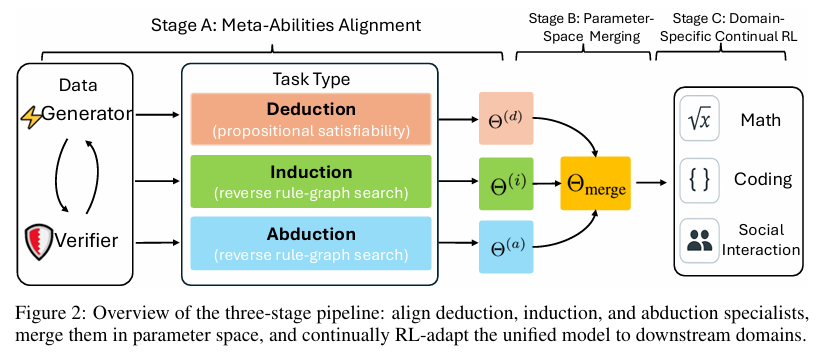
研究提出了一个三阶段的训练流程:
- 元能力对齐阶段:分别在三种合成诊断数据集上训练演绎、归纳和溯因专家模型。采用无批评者的REINFORCE++损失函数,并结合格式奖励和答案奖励进行优化。
- 参数空间合并阶段:通过线性插值将三个专家模型的参数合并为一个统一的模型,保留它们的互补优势。合并后的模型在后续训练中作为初始化点。
- 特定领域强化学习阶段:在合并后的模型基础上,采用特定领域的数据进行强化学习训练,进一步提升模型在数学、编码和科学等领域的性能。
研究结果
性能提升
实验结果表明,元能力对齐显著提升了模型在多个领域的性能。具体而言:
- 诊断任务性能:在专为元能力设计的诊断任务上,对齐后的模型性能相较于指令调优基线提升了超过10%。
- 跨领域泛化能力:对齐后的模型在七个未见过的基准测试上表现出色,包括数学、编码和科学领域。特别是,合并后的模型在整体平均分上相较于基线提升了2.5%(7B模型)和3.5%(32B模型)。
- 特定领域强化学习效果:从对齐检查点开始的特定领域强化学习,相较于从指令调优模型开始的相同流程,进一步提升了性能上限。在数学、编码和科学基准测试上,平均性能提升了约2%。
具体数据表现
- 7B模型:在数学任务上,合并后的模型相较于基线提升了2.2个百分点;在编码任务上提升了1.5个百分点;在科学任务上提升了1.1个百分点。整体平均分提升了2.5个百分点。
- 32B模型:在数学任务上,合并后的模型相较于基线提升了4.4个百分点;在编码任务上提升了4.8个百分点;在科学任务上提升了2.8个百分点。整体平均分提升了3.5个百分点。
此外,从对齐检查点开始的特定领域强化学习在数学任务上为7B模型带来了额外的1.8个百分点提升,为32B模型带来了额外的2个百分点提升。
研究局限
尽管本研究取得了显著成果,但仍存在一些局限性:
- 任务设计的局限性:虽然研究设计了三种元能力对应的任务,但这些任务可能无法完全覆盖所有复杂的推理场景。未来需要设计更多样化的任务来进一步验证元能力对齐的有效性。
- 模型容量的限制:研究主要在7B和32B参数规模的模型上进行了实验。对于更大规模的模型,元能力对齐的效果可能有所不同。未来需要在更大规模的模型上进行实验,以验证方法的可扩展性。
- 融合策略的不足:研究采用了线性插值的方式进行参数空间合并,但这种方法可能不是最优的。未来需要探索更丰富的融合策略,以进一步提升模型的性能。
- 多模态设置的缺失:研究主要集中在文本领域的推理任务上,未涉及多模态设置。未来需要将元能力对齐方法扩展到多模态领域,以验证其在更广泛场景下的有效性。
未来研究方向
基于本研究的成果和局限性,未来可以从以下几个方面展开深入研究:
- 丰富任务设计:设计更多样化、更具挑战性的推理任务,以全面验证元能力对齐的有效性。这些任务可以涵盖更广泛的推理场景和领域,如自然语言理解、图像识别、语音识别等。
- 探索更大规模的模型:在更大规模的模型上进行实验,以验证元能力对齐方法的可扩展性和性能提升效果。特别是,可以关注模型容量与元能力对齐效果之间的关系,为未来模型的设计提供指导。
- 优化融合策略:探索更丰富的融合策略,以进一步提升合并后模型的性能。例如,可以采用注意力机制、门控机制等方法来动态调整不同元能力在推理过程中的贡献。
- 扩展到多模态领域:将元能力对齐方法扩展到多模态领域,以验证其在更广泛场景下的有效性。这需要设计多模态的推理任务和数据集,并开发相应的训练方法和评估指标。
- 提升可解释性和安全性:研究如何通过元能力控制来提升大型推理模型的可解释性和安全性。例如,可以开发可视化工具来展示模型在推理过程中的元能力使用情况;或者设计安全机制来防止模型在特定场景下产生不安全的推理结果。
综上所述,本研究通过明确地将大型推理模型与演绎、归纳和溯因这三种元能力对齐,显著提升了模型的推理能力和跨领域泛化能力。未来的研究可以进一步丰富任务设计、探索更大规模的模型、优化融合策略、扩展到多模态领域以及提升可解释性和安全性等方面展开深入探索。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









