






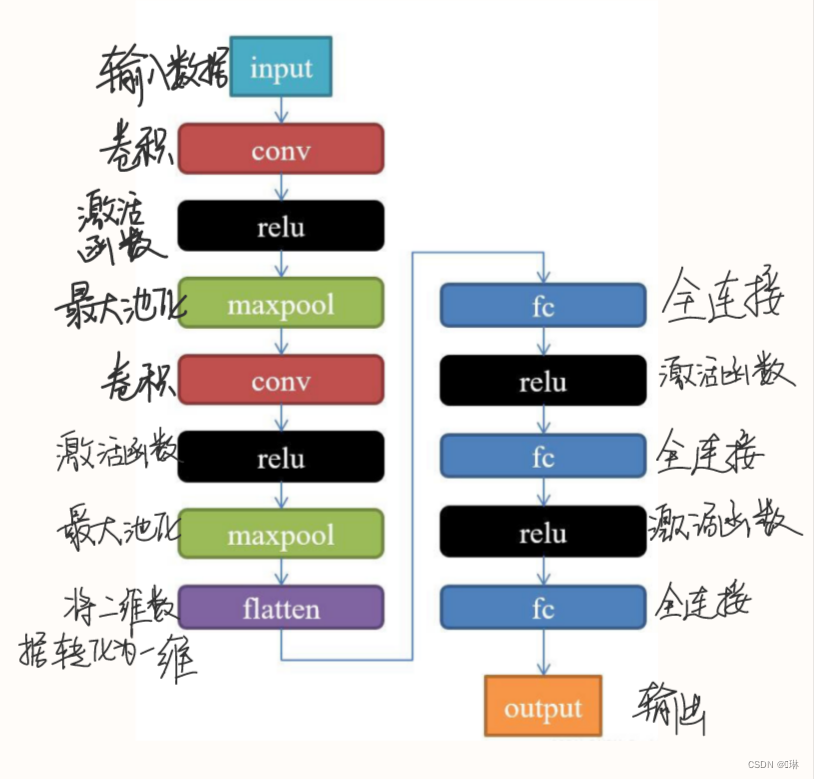
一、用自己的语言解释以下概念
1、局部感知、权值共享
局部感知:在神经网络中,局部感知是指网络中的神经元只关注输入数据的一小部分,即它们只接收输入数据的一小部分作为输入。这种局部感知结构可以减少网络的计算复杂度,同时也可以使网络更加专注于局部特征的提取。
局部连接表示神经元之间只连接局部,就像我们只关注图片的一部分信息。这样做的话,下一层的神经元只能知道上一层的部分信息。看起来我们好像失去了一些信息,但实际上不是这样的。这种局部连接方式让神经网络更高效,减少了要学习的参数和冗余信息。想象一下,如果我们的网络接收一张图片作为输入,每个神经元都只关注图片的一个小部分。通过几层这样的处理后,我们可以把每个小部分的信息综合起来,得到关于图片的整体理解。这种方式不仅让神经网络更简单、参数更少,也让训练时的计算量更小。
权值共享:在一个神经网络中,同一个神经元或者同一层的所有神经元共享相同的权重。这种策略可以减少网络的参数数量,提高网络的泛化能力,同时也可以降低网络的计算复杂度。

权值共享就是说,给一张输入图片,用一个卷积核去扫这张图,卷积核里面的数就叫权重,这张图每个位置是被同样的卷积核扫的,所以权重是一样的,也就是共享。
2、池化(子采样、降采样、汇聚)。会带来哪些好处和坏处?
池化:一种对神经网络中某一层的输出进行压缩的方法,它可以减少网络的参数数量和计算复杂度,同时也可以提高网络的泛化能力。池化操作通常会丢失一些信息,因此可能会对网络的性能产生一定的影响。但是,如果池化操作能够合理地进行,它所带来的好处是可以提高网络的泛化能力和计算效率。
在图像处理中,由于图像中存在很多冗余信息,我们可以通过一个区域内的统计信息(比如最大值或平均值等)来描述这个区域的整体情况,而不需要对这个区域中的每一个像素点都进行处理。简单来说,池化就是用一个更小的、代表性的数值来代替原来区域内的所有数值,从而减少处理时间和计算量。
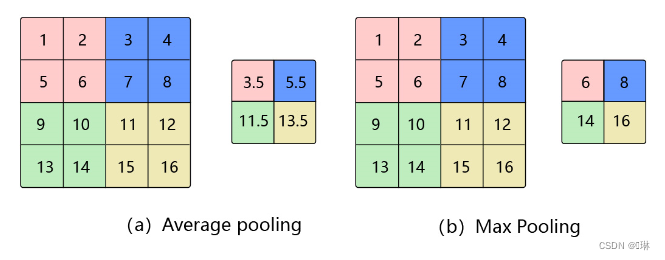
池化的几种常见方法包括:平均池化、最大池化、K-max池化。
平均池化: 计算区域子块所包含所有像素点的均值,将均值作为平均池化结果。
最大池化: 从输入特征图的某个区域子块中选择值最大的像素点作为最大池化结果。
K-max池化: 对输入特征图的区域子块中像素点取前K个最大值,常用于自然语言处理中的文本特征提取。
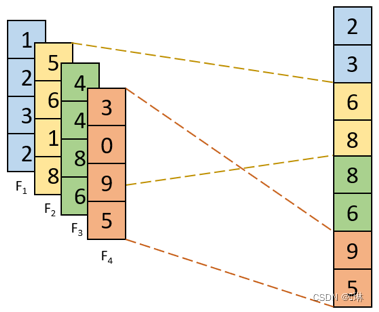
3、全卷积网络( 课上讲的这个概念不准确,同学们查资料纠正一下)
全卷积网络是一种特殊的卷积神经网络,它只包含卷积层和池化层,不包含全连接层。这种网络结构可以有效地减少网络的参数数量和计算复杂度,同时也可以更好地处理图像数据。
4、低级特征、中极特征、高级特征
视觉特征:点和边这样的低级特征,平面和斑点这样的中级特征,以及语义标记的对象这样的高级特征
低级特征来源于浅层网络,富含空间信息,空间信息的特征分辨率比较高,常指的是图像的基本元素,如边缘、角点等。
中级特征则来源于浅层网络与深层网络之间,与低级特征相比,其空间属性更加丰富,但空间信息的特征分辨率较低,通常指的是图像的局部特征,如纹理、形状等。
高级特征来源于深层网络,富含语义信息,语义信息的特征分辨率比较高,通常指的是图像的全局特征,如物体的类别、语义等。
5、多通道。N输入,M输出是如何实现的?
多通道;允许多个输入通道同时传递信息到网络中,并产生多个输出通道以提供更丰富的信息。比如在图像处理中,每个输入通道可以代表图像的一个颜色通道(如红色、绿色、蓝色通道),而每个输出通道可以代表图像的一个特征检测器(如边缘、角点等)。


6、1×1的卷积核有什么作用
1.增加网络深度(增加非线性映射次数)
1x1的卷积核虽然尺寸小,但仍然是一个卷积核。在网络中添加一层卷积,会相应地增加网络的深度。1x1的卷积核可以在保持特征图尺度不变的情况下,大幅增加网络的非线性特性。这意味着,通过使用1x1卷积核,我们可以在不损失分辨率的情况下,增加网络的复杂性和表达能力。
2.升维/降维
当我们仅仅只是想要改变通道数的情况下,1x1卷积核是最小的选择,因为大于1x1的卷积核无疑会增加计算的参数量,内存也会随之增大,所以只想单纯的去提升或者降低特征图的通道,选用1x1卷积核最为合适, 1x1卷积核会使用更少的权重参数数量。
3.跨通道的信息交互
1x1的卷积核虽然只有一个参数,但当它作用于多通道的特征图时,它实际上是对不同通道上的信息进行了一个线性组合。这个线性组合可以看作是各个通道上的信息的加权求和,其中这个权重就是一个系数。
通过这样的操作,输出的特征图就整合了多个通道的信息。这意味着,使用1x1卷积核可以丰富网络提取的特征。它让网络在处理信息时,不仅仅依赖于单个通道的特征,而是能够综合利用多个通道的信息。
4.减少卷积核参数(简化模型)
二、使用CNN进行XO识别
1.复现参考资料中的代码
读取数据集
将xo数据集分为两部分,训练集和测试集,训练集600个,测试集400个。(在训练模型时发现了问题)
###读取数据集并可视化前五个
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
data_train = datasets.ImageFolder('train_data', transforms)
data_test = datasets.ImageFolder('test_data', transforms)
train_loader = DataLoader(data_train, batch_size=64, shuffle=True)
test_loader = DataLoader(data_test, batch_size=64, shuffle=True)
for i, data in enumerate(train_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
for i, data in enumerate(test_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
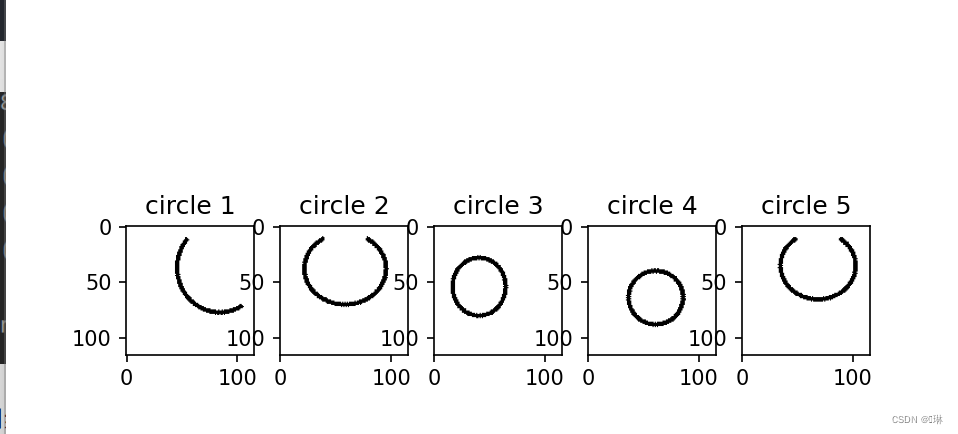
#可视化前五个标签是0的(圆)
a = 0
plt.figure()
index = 0
for i in labels:
if i == 0 and a < 5:
plt.subplot(151 + a)
plt.imshow(images[index].data.squeeze().numpy(), cmap='gray')
plt.title('circle ' + str(a + 1))
a += 1
if a == 5:
break
index += 1
plt.show()
#可视化前五个标签是1的(叉)
a = 0
plt.figure()
index = 0
for i in labels:
if i == 1 and a < 5:
plt.subplot(151 + a)
plt.imshow(images[index].data.squeeze().numpy(), cmap='gray')
plt.title('crosses ' + str(a + 1))
a += 1
if a == 5:
break
index += 1
plt.show()


构建模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3)
self.maxpool = nn.MaxPool2d(2, 2) # 2x2的最大池化层
self.conv2 = nn.Conv2d(9, 5, 3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200)
self.fc2 = nn.Linear(1200, 64)
self.fc3 = nn.Linear(64, 2)
def forward(self, x):
x = self.maxpool(self.relu(self.conv1(x)))
x = self.maxpool(self.relu(self.conv2(x)))
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
构建模型时,查到了两种写法: CNN(nn.Module)和Net(nn.Moudle),那么这两个有什么区别呢?
Net(nn.Moudle) :创建一个一般的神经网络模型
CNN(nn.Module) :创建一个卷积神经网络模型
卷积神经网络是一种特殊的神经网络,它主要用于处理图像数据。卷积神经网络的特点是使用卷积层来捕捉图像中的空间结构,并通过共享权重和偏置项来减少模型的参数数量。这种类型的网络通常用于图像识别、目标检测和图像分割等任务。
相比之下,一般的神经网络模型可能没有卷积层,并且可以用于处理其他类型的数据。这种模型通常包括全连接层、激活函数和损失函数等组件,可以用于各种不同的机器学习任务。
训练模型
一开始我把数据集按3:2分为了训练集和测试集,但是在训练模型时发现,这种划分会导致模型在训练集上学习到的信息量相对较少,从而影响模型的泛化能力,也会导致数据集的利用率较低,影响模型的训练效果。
因此我将数据集重新分配,分为850个训练集和150个测试集。
为什么要将数据集分为850个训练集和150个测试集,这主要是为了满足机器学习算法的效率和准确性的需求。具体来说:
- 训练集的数量(850个)远大于测试集的数量(150个),这有助于算法在训练过程中获得更多的信息,从而更好地学习和理解数据的特征和规律。如果训练集的数量过少,可能会导致模型无法充分学习数据的特征,影响模型的准确性和泛化能力。
- 训练集和测试集的比例(约5:1)是一个常见的选择,但这个比例并不是固定的,可以根据具体的数据情况和任务需求进行调整。在这个比例下,模型在训练集上训练后,可以在测试集上表现得更好,这说明模型具有较好的泛化能力。
# 模型训练
model = CNN()
loss = nn.CrossEntropyLoss()
opti = torch.optim.SGD(model.parameters(), lr=0.1)
epochs = 10
for epoch in range(epochs):
total_loss = 0
for i, data in enumerate(train_loader):
images, labels = data
out = model(images)
one_loss = loss(out, labels)
opti.zero_grad()
one_loss.backward() # 损失函数对模型参数的偏导数。这些梯度会存储在每个参数的.grad属性中。
# 从输出节点开始,依次向输入节点回溯,对于每一个节点,它会计算这个节点的梯度(对于损失的偏导数),并将结果存储在每个参数的.grad属性中。
opti.step() # 使用前面计算的梯度来更新模型的权重。
total_loss += one_loss
if (i + 1) % 10 == 0:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, total_loss / 100))
total_loss = 0.0
print('finished train')
# 保存模型
torch.save(model, 'model.pth') # 保存的是模型, 不止是w和b权重值
torch.save(model.state_dict(), 'model_name1.pth') # 保存的是w和b权重值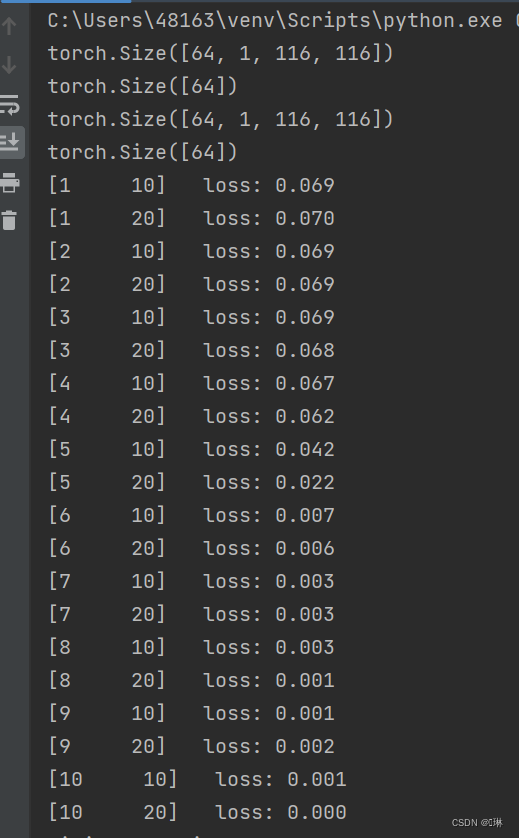
测试模型
print("labels[0] truth:\t", labels[0])
x = images
print(x.shape)
predicted = torch.max(model(x), 1)
print("labels[0] predict:\t", predicted.indices[0])
img = images[0].data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.show()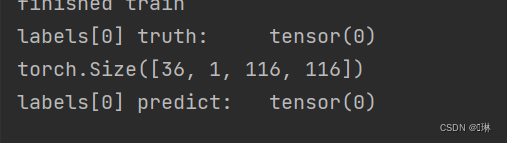

计算模型的准确率
# 计算模型的准确率
model_load = torch.load('model.pth')
correct = 0
total = 0
with torch.no_grad(): # 进行评测的时候网络不更新梯度
for data in test_loader: # 读取测试集
images, labels = data
outputs = model_load(images)
_, predicted = torch.max(outputs.data, 1) # 取出 最大值的索引 作为 分类结果
total += labels.size(0) # labels 的长度
correct += (predicted == labels).sum().item() # 预测正确的数目
print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))

查看训练好的模型的特征图
import torch
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
# 定义图像预处理过程(要与网络模型训练过程中的预处理过程一致)
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'train_data'
data_train = datasets.ImageFolder(path, transform=transforms)
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
for i, data in enumerate(data_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
outputs = []
x = self.conv1(x)
outputs.append(x)
x = self.relu(x)
outputs.append(x)
x = self.maxpool(x)
outputs.append(x)
x = self.conv2(x)
x = self.relu(x)
x = self.maxpool(x)
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return outputs
# create model
model1 = Net()
# load model weights加载预训练权重
# model_weight_path ="./AlexNet.pth"
model_weight_path = "model_name1.pth"
model1.load_state_dict(torch.load(model_weight_path))
# 打印出模型的结构
print(model1)
x = images[0]
# forward正向传播过程
out_put = model1(x)
for feature_map in out_put:
# [N, C, H, W] -> [C, H, W] 维度变换
im = np.squeeze(feature_map.detach().numpy())
# [C, H, W] -> [H, W, C]
im = np.transpose(im, [1, 2, 0])
print(im.shape)
# show 9 feature maps
plt.figure()
for i in range(9):
ax = plt.subplot(3, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
# [H, W, C]
# 特征矩阵每一个channel对应的是一个二维的特征矩阵,就像灰度图像一样,channel=1
# plt.imshow(im[:, :, i])
plt.imshow(im[:, :, i], cmap='gray')
plt.show()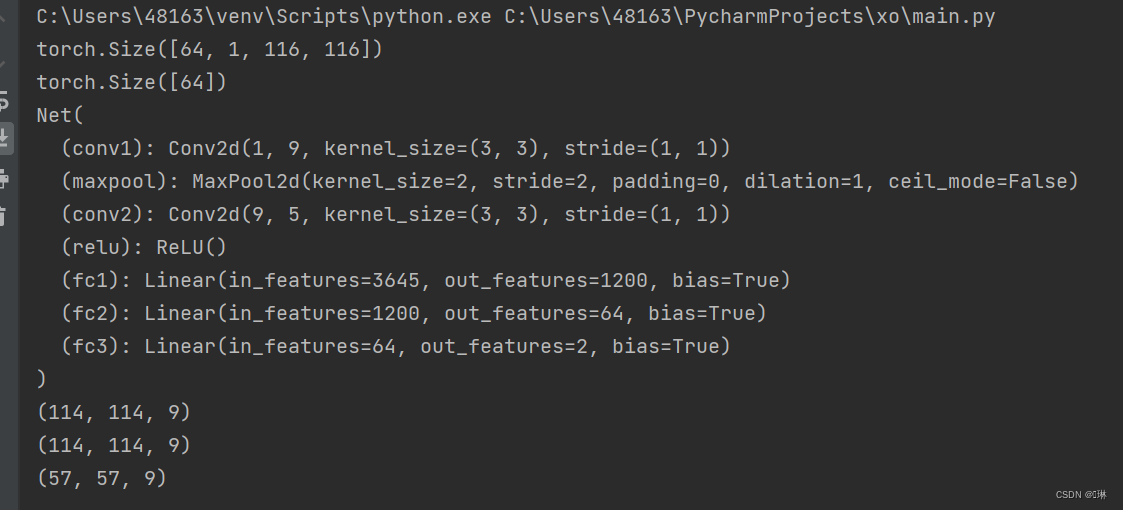
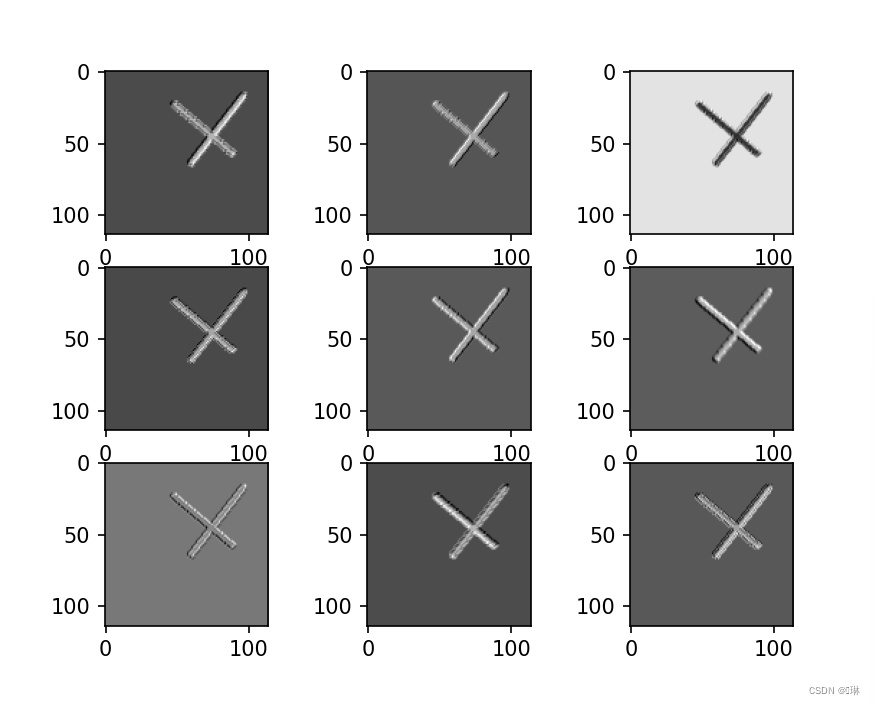
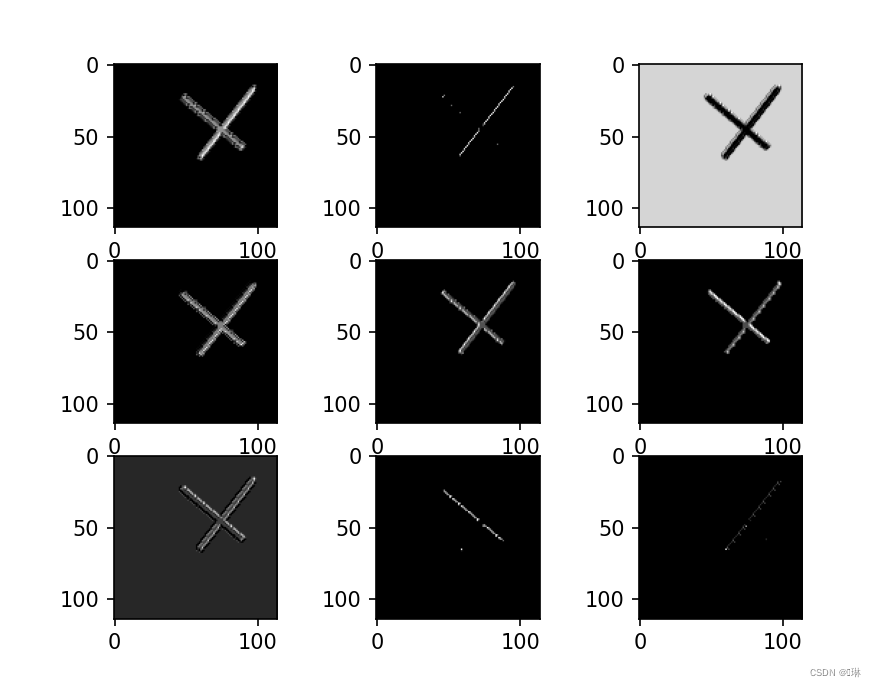
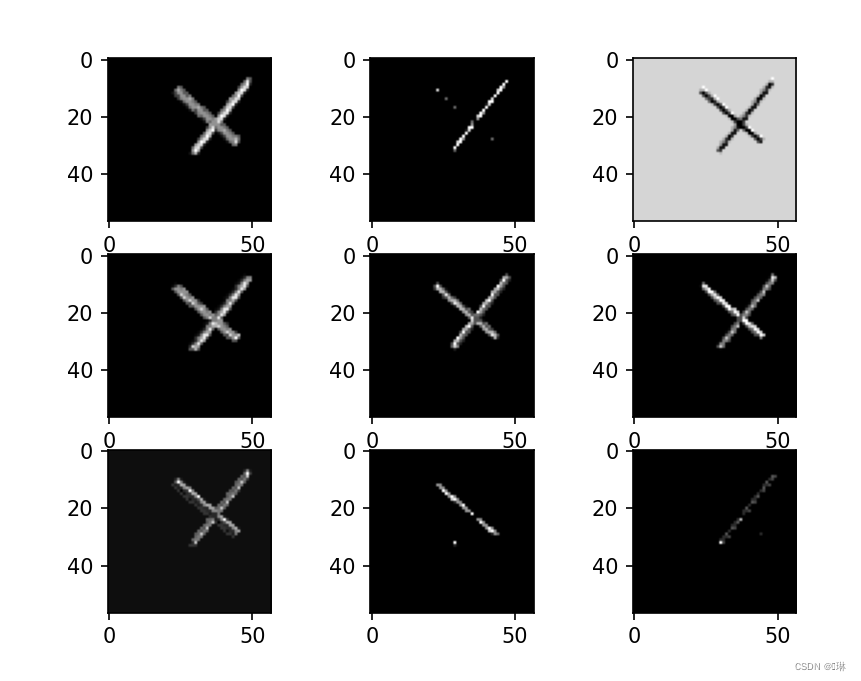
查看训练好的模型的卷积核
model = torch.load('model.pth')
print(model)
x = images[0].unsqueeze(0)
# forward正向传播过程
out_put = model(x)
weights_keys = model.state_dict().keys()
for key in weights_keys:
print("key :", key)
# 卷积核通道排列顺序 [kernel_number, kernel_channel, kernel_height, kernel_width]
if key == "conv1.weight":
weight_t = model.state_dict()[key].numpy()
print("weight_t.shape", weight_t.shape)
k = weight_t[:, 0, :, :] # 获取第一个卷积核的信息参数
# show 9 kernel ,1 channel
plt.figure()
for i in range(9):
ax = plt.subplot(3, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
plt.imshow(k[i, :, :], cmap='gray')
title_name = 'kernel' + str(i) + ',channel1'
plt.title(title_name)
plt.show()
if key == "conv2.weight":
weight_t = model.state_dict()[key].numpy()
print("weight_t.shape", weight_t.shape)
k = weight_t[:, :, :, :] # 获取第一个卷积核的信息参数
print(k.shape)
print(k)
plt.figure()
for c in range(9):
channel = k[:, c, :, :]
for i in range(5):
ax = plt.subplot(2, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
plt.imshow(channel[i, :, :], cmap='gray')
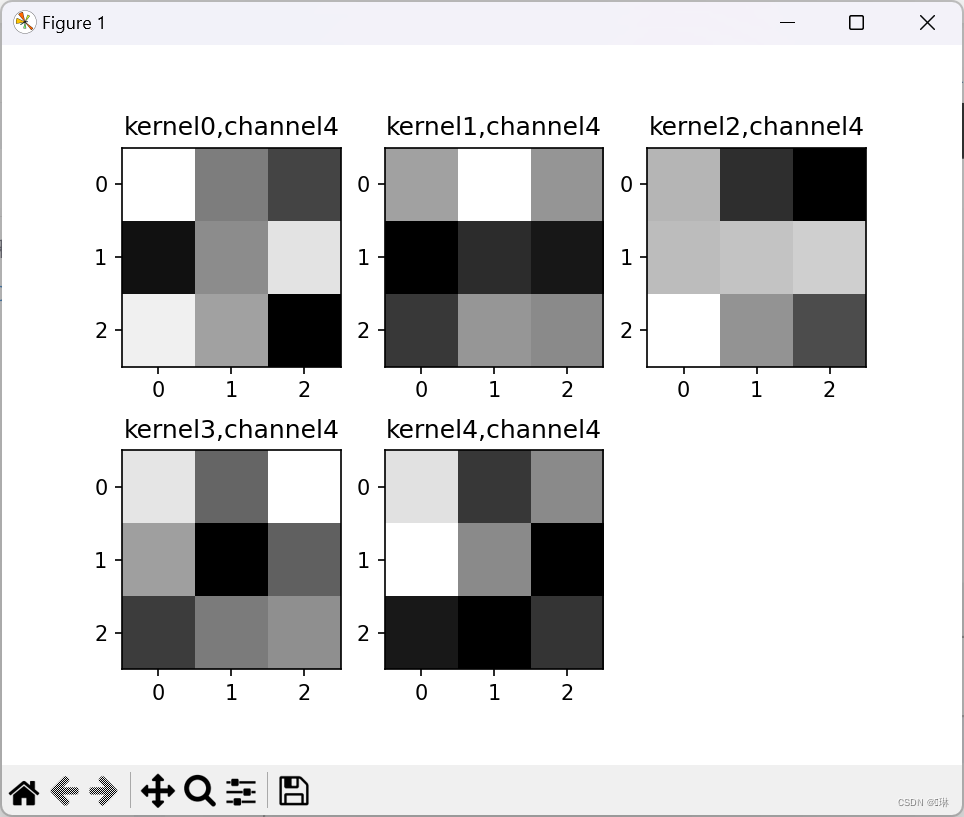
title_name = 'kernel' + str(i) + ',channel' + str(c)
plt.title(title_name)
plt.show()第一张图里面一共九个小图,第一个卷积层里是9组卷积核。
第二组一共9个大图,5个小图,9对应着卷积核的厚度,5对应着卷积核的组数。
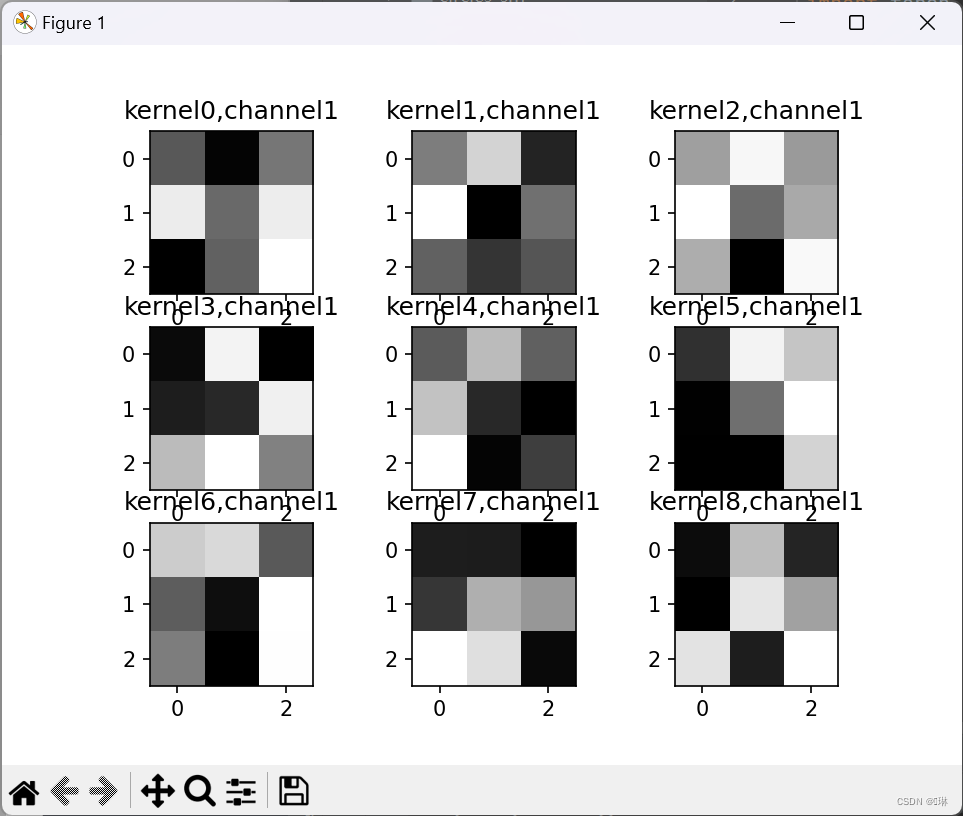
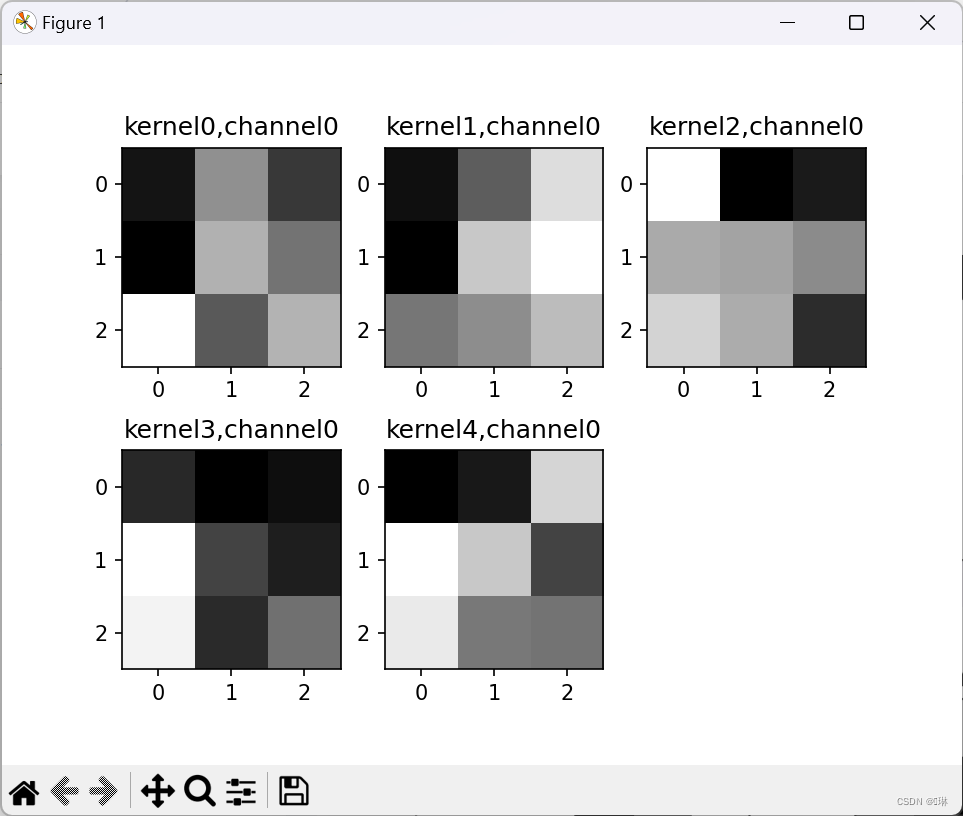
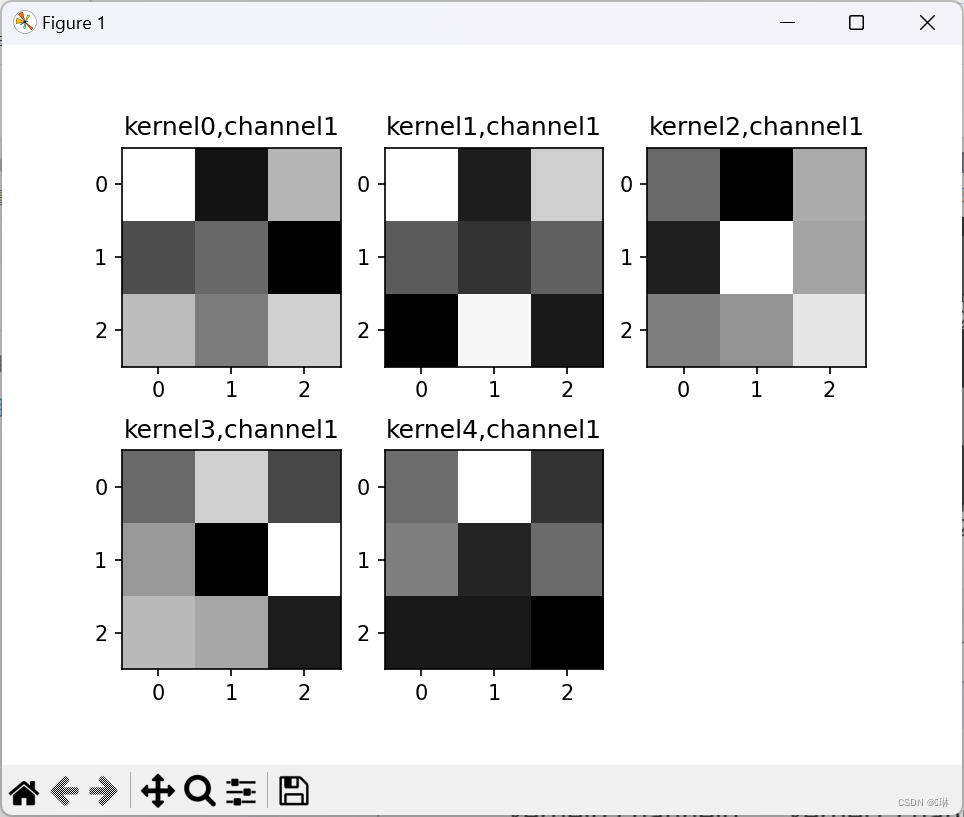
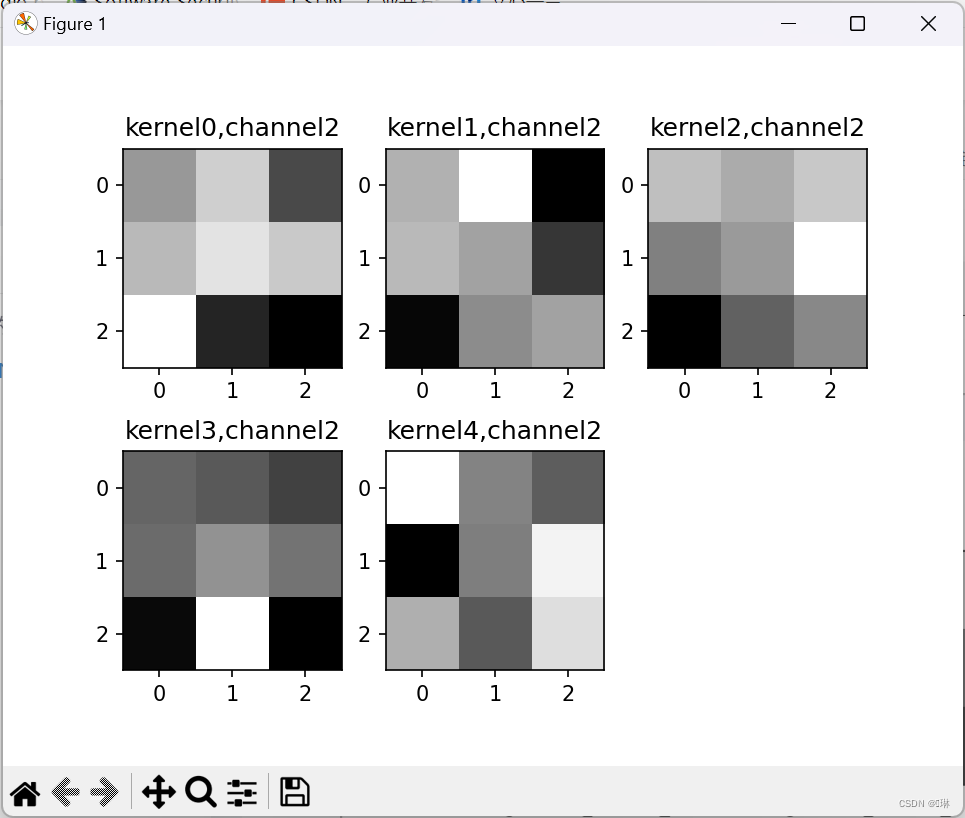
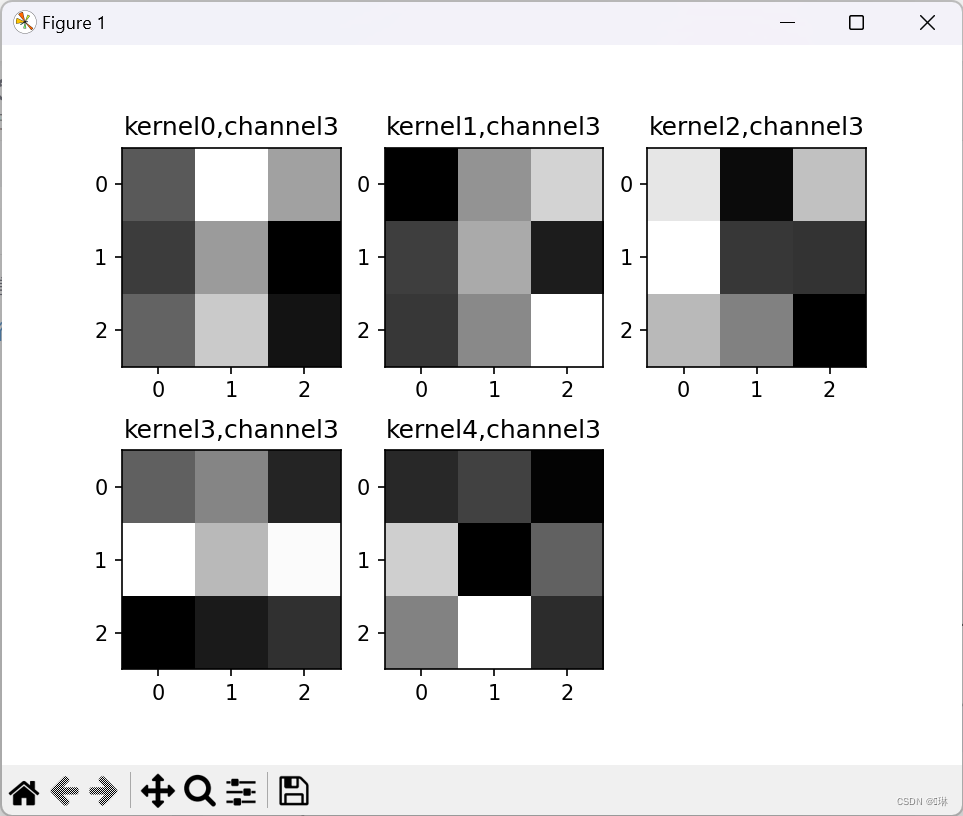






2.重新设计网络结构
至少增加一个卷积层,卷积层达到三层以上

class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # 修改为2D卷积层
self.maxpool = nn.MaxPool2d(2, 2) # 2x2的最大池化层
self.conv2 = nn.Conv2d(9, 5, 3) # 修改为2D卷积层
self.conv3 = nn.Conv2d(5, 5, 3) # 修改为2D卷积层
self.relu = nn.ReLU()
self.fc1 = nn.Linear(12 * 12 * 5, 480)
self.fc2 = nn.Linear(480, 320)
self.fc3 = nn.Linear(320, 2)
def forward(self, x):
x = self.maxpool(self.relu(self.conv1(x)))
x = self.maxpool(self.relu(self.conv2(x)))
x = self.maxpool(self.relu(self.conv3(x)))
x = x.view(-1, 12 * 12 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
通过对比,新的结构和之前的结构基本没变化
去掉池化层,对比“有无池化”的效果
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3)
self.conv2 = nn.Conv2d(9, 5, 3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(112 * 112 * 5, 4000)
self.fc2 = nn.Linear(4000, 2400)
self.fc3 = nn.Linear(2400, 2)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = x.view(-1, 112 * 112 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x 
很明显的感受到,没有池化的训练速度很慢,训练等待的时间真的很长!!
修改“通道数”等超参数,观察变化
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 18, 3)
self.maxpool = nn.MaxPool2d(2, 2)#2x2的最大池化层
self.conv2 = nn.Conv2d(18, 5, 3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200)
self.fc2 = nn.Linear(1200, 64)
self.fc3 = nn.Linear(64, 2)
def forward(self, x):
x = self.maxpool(self.relu(self.conv1(x)))
x = self.maxpool(self.relu(self.conv2(x)))
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x 
将通道变大,看起来没有多大的区别
3.可视化
选择自己的最优模型,可视化部分卷积核和特征图,探索低级特征、中级特征、高级特征
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from PIL import Image
# 加载图片并转为灰度图
img = Image.open('cat.JPG').convert('L')
# 定义转换器
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# 对图片进行转换
img_tensor = transform(img)
# 定义模型
model = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(8, 16, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 提取初级特征
with torch.no_grad():
x = img_tensor.unsqueeze(0)
x = model[:4](x)
x = x.squeeze(0)
for i in range(8):
plt.subplot(2, 4, i + 1)
plt.imshow(x[i], cmap='gray')
plt.axis('off')
plt.show()
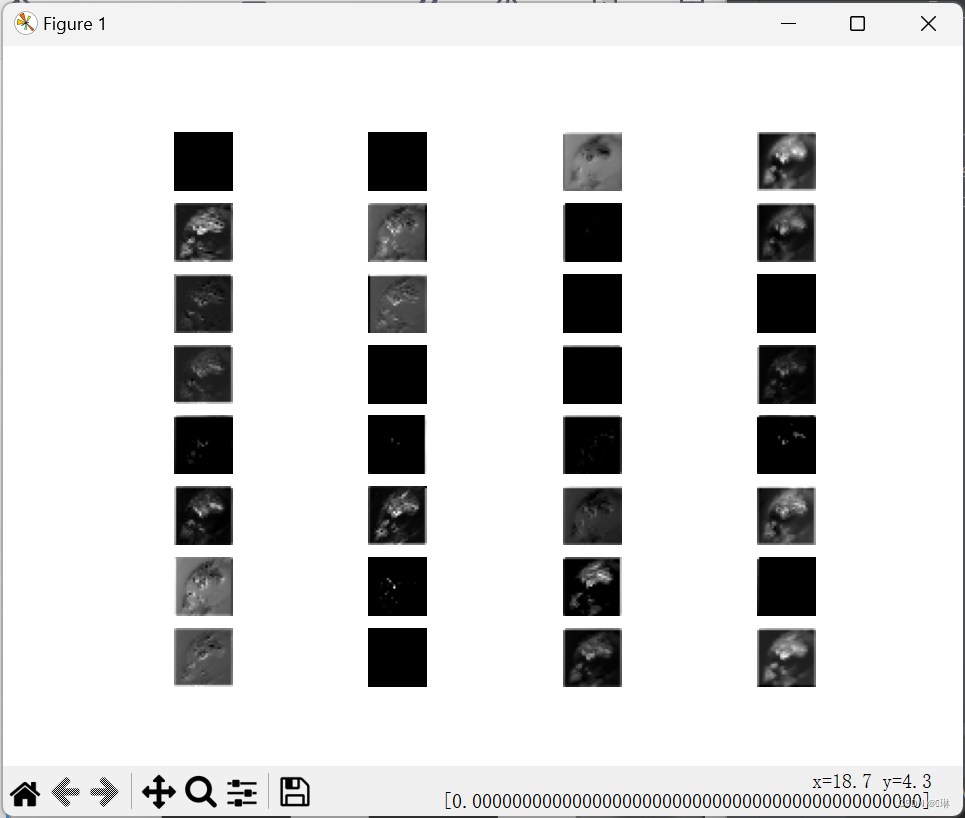
# 提取中级特征
with torch.no_grad():
x = img_tensor.unsqueeze(0)
x = model[:8](x)
x = x.squeeze(0)
for i in range(16):
plt.subplot(4, 4, i + 1)
plt.imshow(x[i], cmap='gray')
plt.axis('off')
plt.show()
# 提取高级特征
with torch.no_grad():
x = img_tensor.unsqueeze(0)
x = model[:12](x)
x = x.squeeze(0)
for i in range(32):
plt.subplot(8, 4, i + 1)
plt.imshow(x[i], cmap='gray')
plt.axis('off')
plt.show() 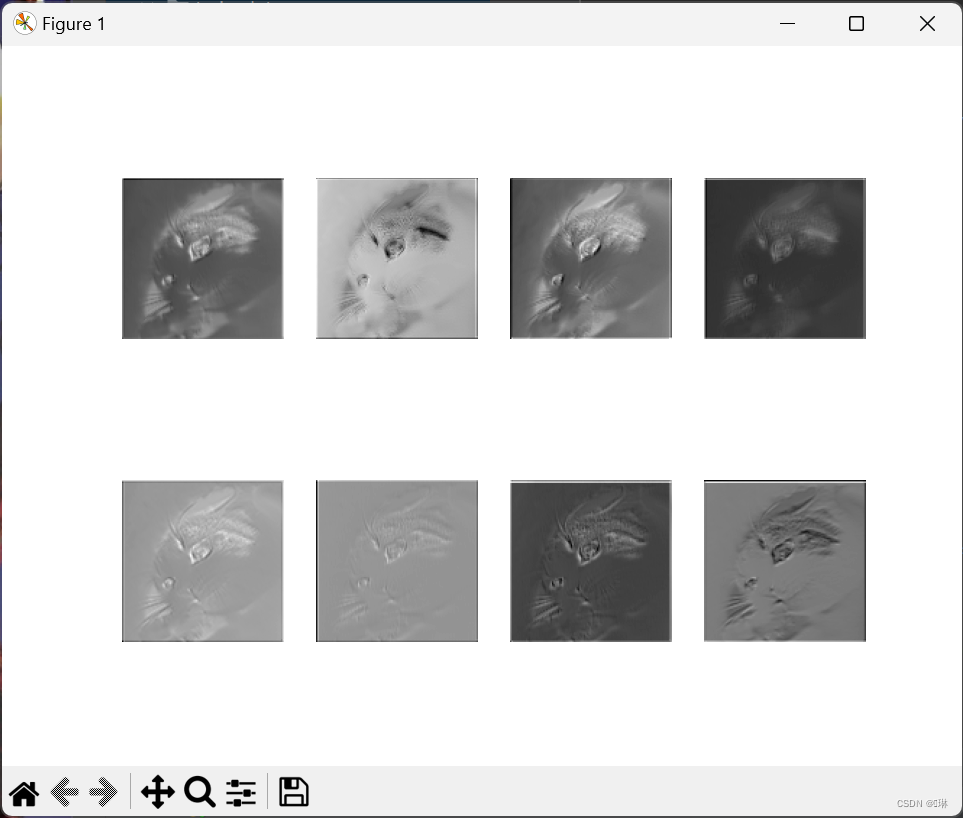


参考链接:局部感知与权值共享_局部感受野和权值共享_Le0v1n的博客-CSDN博客
【精选】深度学习基础学习-1x1卷积核的作用(CNN中)_1*1卷积核的作用-CSDN博客















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









