






目录
3.采用堆叠回归(Stacking Regression)模型
3.2堆叠回归(Stacking Regression)模型
1.项目介绍
1.1问题描述
货币价格预测器是一项极具前瞻性和实用性的项目。在这个数字化时代,区块链技术的不断发展推动着加密货币市场的蓬勃发展。随着越来越多的数字货币涌现,并且市场波动性增加,对货币价格的准确预测变得至关重要。
1.2预期解决方案
通过参考英特尔的类似实现方案,预测比特币价格趋势的可靠性和准确性,以及预测模型的推理速度,可以为全球数字货币市场的安全性和可持续性提供有力支持。这里,我们将分类准确度和推理时间作为评估比特币价格预测器的主要依据。
1.3数据集展示
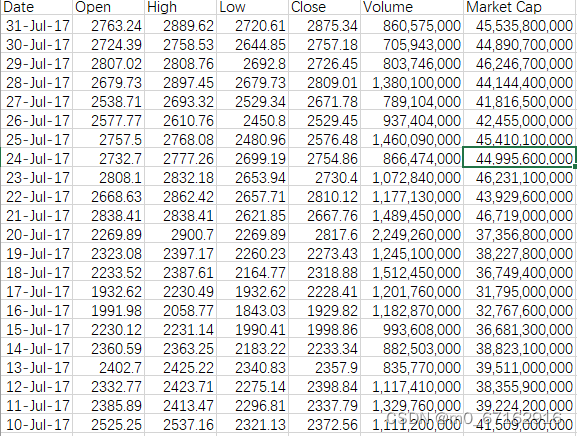
1.3.1 train数据集
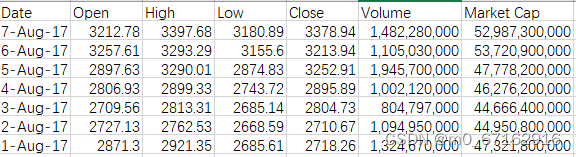
1.3.2 test数据集
2.数据相关处理
2.1加载数据
# 加载数据集
train_df = pd.read_csv('bitcoin_price_Training - Training.csv')
test_df = pd.read_csv('bitcoin_price_1week_Test - Test.csv')
# 数据清洗
train_df.replace('-', np.nan, inplace=True)
test_df.replace('-', np.nan, inplace=True)
train_df.dropna(inplace=True)
test_df.dropna(inplace=True)2.2将数据集中的日期格式进行转换
# 转换日期格式并排序
train_df['Date'] = pd.to_datetime(train_df['Date'])
test_df['Date'] = pd.to_datetime(test_df['Date'])
train_df.sort_values('Date', inplace=True)
test_df.sort_values('Date', inplace=True)2.3准备用于机器学习模型的训练和测试数据
# 准备训练和测试数据
X_train = train_df[['Open', 'High', 'Low', 'Volume', 'Market Cap']].replace('[\,,]', '', regex=True).astype(float)
y_train = train_df['Close'].replace('[\,,]', '', regex=True).astype(float)
X_test = test_df[['Open', 'High', 'Low', 'Volume', 'Market Cap']].replace('[\,,]', '', regex=True).astype(float)
y_test = test_df['Close'].replace('[\,,]', '', regex=True).astype(float)
# 确保训练和测试数据使用相同的特征名称
X_train.columns = ['Open', 'High', 'Low', 'Volume', 'Market Cap']
X_test.columns = ['Open', 'High', 'Low', 'Volume', 'Market Cap']-
数据选择:从
train_df和test_df数据帧中选择特定的列('Open', 'High', 'Low', 'Volume', 'Market Cap')作为特征(X),以及'Close'列作为目标变量(y)。这些列分别代表了股票或金融资产的开盘价、最高价、最低价、交易量和市值,以及收盘价。 -
数据清洗:使用
replace('[\,,]', '', regex=True)方法去除特征和目标列中的逗号,这通常是为了将数值从字符串格式转换为浮点数格式。逗号在数字中通常用作千位分隔符,移除它们是为了确保数据能被正确解析为数值类型。 -
类型转换:通过
astype(float)将清洗后的字符串转换为浮点数类型,以便于在后续的数学计算和模型训练中使用。 -
确保一致性:通过显式设置
X_train和X_test的列名,确保训练集和测试集使用相同的特征名称。这一步骤是很重要的,因为在机器学习模型的训练和测试过程中,特征的顺序和名称必须保持一致。
3.采用堆叠回归(Stacking Regression)模型
3.1 XGBoost模型
XGBoost(eXtreme Gradient Boosting)是一种高效且灵活的梯度提升库,广泛用于机器学习竞赛和实际应用中。XGBoost在处理分类、回归、排序等多种类型的机器学习问题时展现出了卓越的性能。下面列出XGBoost的主要优势和劣势:
优势
-
性能高效:XGBoost在算法的设计上进行了优化,包括使用了高效的数据结构和算法实现(如树的构建和特征分裂算法),使得其在处理大规模数据时更加高效。
-
模型精度高:XGBoost通过梯度提升算法结合多个决策树模型,通常能够提供非常高的预测精度。
-
正则化:XGBoost在目标函数中加入了正则项,有助于控制模型的复杂度,从而减少过拟合。
-
灵活性:XGBoost支持用户自定义优化目标和评价准则,这为处理各种不同的机器学习问题提供了很大的灵活性。
-
处理缺失值:XGBoost能够自动处理内部缺失数据,无需进行复杂的数据预处理。
-
剪枝:XGBoost使用的是后剪枝方法,与其他梯度提升方法相比,它可以更有效地减少模型的复杂性和提高模型的效率。
-
内置交叉验证:XGBoost可以在每一轮迭代过程中使用内置的交叉验证方法来评估模型的性能,便于找到最优的模型参数。
-
易于并行:虽然树的构建本身是序列过程,但XGBoost在特征分裂时采用了近似算法,可以进行并行处理,从而加快模型的训练速度。
劣势
-
资源消耗:由于XGBoost是基于树的算法,训练大型模型时可能会消耗大量内存和计算资源。
-
调参复杂:XGBoost有许多的超参数,如树的深度、学习率、正则化系数等,这些参数的调整对模型性能有显著影响,但同时也增加了模型调优的难度。
-
模型解释性:虽然XGBoost提供了特征重要性等指标以帮助解释模型,但是当模型包含大量树时,模型的解释性仍然是一个挑战。
-
对小规模数据集过拟合的风险:在数据量较小的情况下,XGBoost模型可能会过拟合,尤其是在没有适当正则化和参数调整的情况下。
3.2堆叠回归(Stacking Regression)模型
堆叠回归(Stacking Regression)模型相比于其他单一模型或一些基础的集成方法(如Bagging和Boosting)具有一些显著优势:
-
性能提升:堆叠回归通过结合多个不同的基模型和一个元模型,能够学习并利用每个基模型在预测任务上的独特强项,通常能提供比任何单一模型更准确的预测结果。这种方法可以有效地减少模型的偏差和方差,提高整体性能。
-
模型多样性:堆叠允许使用不同种类的模型作为基模型,如线性模型、决策树模型、支持向量机等。这种多样性使得堆叠模型能够捕捉到数据中的复杂非线性关系和模式,从而提高模型的泛化能力。
-
灵活性和定制化:堆叠模型的结构提供了高度的灵活性,允许研究人员根据具体问题的需求选择不同的基模型和元模型。这种定制化的方法使得堆叠模型可以针对特定数据集或任务进行优化。
-
减少过拟合风险:通过组合多个模型的预测结果,堆叠可以减少过拟合的风险。基模型的多样性意味着每个模型可能会在不同的数据子集上过拟合,但当这些预测被元模型综合时,过拟合的影响可以被相互抵消。
-
提高鲁棒性:堆叠模型通过综合多个模型的预测,可以提高对新数据或未见数据的鲁棒性。即使某些基模型在特定情况下表现不佳,其他模型的表现可以补偿这一不足,确保整体预测的稳定性。
-
促进模型解释性:尽管堆叠模型的复杂性可能会影响到模型的直接解释性,但通过分析各个基模型在堆叠过程中的贡献度,可以提供关于数据和模型行为的洞察,从而增强模型的间接解释性。
4.1定义基模型和元模型
# 定义基模型
base_models = [
('random_forest', RandomForestRegressor(n_estimators=4000, random_state=42)),
('gradient_boosting', GradientBoostingRegressor(n_estimators=4000, random_state=42)),
('linear_regression', LinearRegression())
]
# 定义元模型
meta_model = LinearRegression()4.2采用网格搜索,找出最佳参数
# 定义网格搜索参数
param_grid_rf = {
'n_estimators': [100, 500, 1000],
'max_depth': [None, 10, 20, 30]
}
param_grid_gb = {
'n_estimators': [100, 500, 1000],
'learning_rate': [0.01, 0.1, 0.2],
'max_depth': [3, 5, 7]
}
# 执行网格搜索
grid_search_rf = GridSearchCV(RandomForestRegressor(random_state=42), param_grid=param_grid_rf, cv=5, n_jobs=-1, verbose=2)
grid_search_gb = GridSearchCV(GradientBoostingRegressor(random_state=42), param_grid=param_grid_gb, cv=5, n_jobs=-1, verbose=2)
grid_search_rf.fit(X_train, y_train)
grid_search_gb.fit(X_train, y_train)
# 打印最佳参数
print("Best parameters for RandomForestRegressor:", grid_search_rf.best_params_)
print("Best parameters for GradientBoostingRegressor:", grid_search_gb.best_params_)
# 更新基模型列表为使用最佳参数
base_models = [
('random_forest', RandomForestRegressor(**grid_search_rf.best_params_, random_state=42)),
('gradient_boosting', GradientBoostingRegressor(**grid_search_gb.best_params_, random_state=42)),
('linear_regression', LinearRegression())
]
4.2使用堆叠模型进行预测
# 定义堆叠回归器
stacking_regressor = StackingRegressor(estimators=base_models, final_estimator=meta_model, n_jobs=-1)
# 拟合堆叠回归器模型
stacking_regressor.fit(X_train, y_train)
# 开始计时
start_time = time.time()
# 使用堆叠模型进行预测
predictions_stacking = stacking_regressor.predict(X_test)5.训练及预测结果可视化
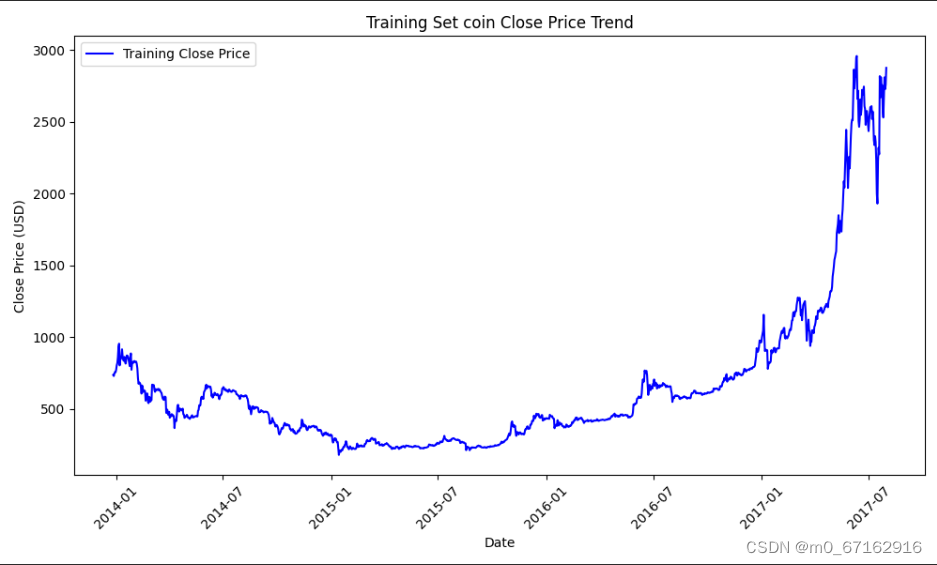
5.1训练集上的价格走势
5.2Test数据集上的真实价格及预测价格
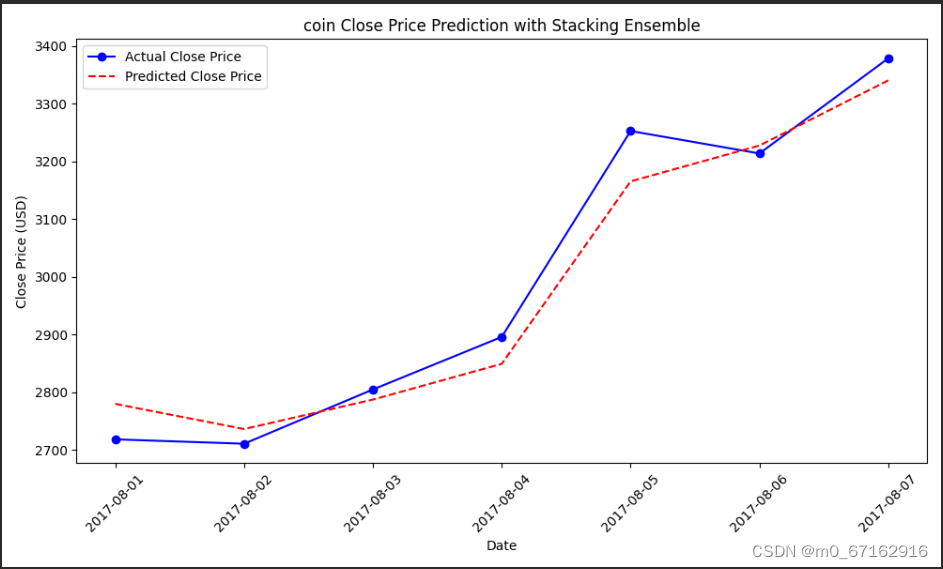
-
跟踪趋势:模型预测的趋势(虚线)跟随了实际收盘价(实线)的趋势。这表明模型能够捕捉到价格随时间变化的一般模式。
-
预测准确性:在大部分数据点上,预测的价格和实际价格相当接近,说明模型具有相对较好的预测准确性。
6.使用英特尔® ONEAPI AI分析工具包
# 定义基模型
base_models = [
('random_forest', RandomForestRegressor(n_estimators=4000, random_state=42)),
('gradient_boosting', GradientBoostingRegressor(n_estimators=4000, random_state=42)),
('linear_regression', LinearRegression())
]
# 定义元模型
meta_model = LinearRegression()
patch_sklearn()
# 定义堆叠回归器
stacking_regressor = StackingRegressor(estimators=base_models, final_estimator=meta_model, n_jobs=-1)
# 拟合堆叠回归器模型
stacking_regressor.fit(X_train, y_train)6.1工具的作用:
-
加速 Scikit-learn 算法:通过使用
patch_sklearn(),代码在执行 Scikit-learn 算法时(如RandomForestRegressor,GradientBoostingRegressor,和LinearRegression)会自动使用经过优化的版本,这些版本针对英特尔® 处理器进行了优化,可以显著提高数据处理和模型训练的速度。 -
提高效率:对于大规模数据集和复杂模型,这种加速可以大幅度减少训练和预测所需的时间。
7.模型评价
7.1 RMSE(均方根误差)
在统计和机器学习领域,"RMSE"代表"Root Mean Squared Error"(均方根误差),是评估模型预测性能的一种常用指标。它衡量的是模型预测值与实际观测值之间的差异。
7.2 RMSE的特点:
- 非负值:RMSE的值总是非负的,因为它是平方差的平均值的平方根。RMSE的值越小,表示模型的预测结果与实际值越接近,模型的性能越好。
- 量纲一致:RMSE的量纲与所预测的目标变量的量纲相同,这使得其易于解释和理解。
- 对离群值敏感:由于在计算过程中对差异进行了平方,因此RMSE对离群值(异常值)比较敏感。这意味着预测结果中的大误差会在RMSE中得到更加显著的体现。
RMSE是评价回归模型性能的一种重要工具,广泛应用于各种预测任务中,如天气预测、股价预测、房价预测等领域。
7.3模型对此问题的RMSE

RMSE: 41.281945018973474
7.4模型所需要的推理时间

模型拟合和预测所需时间: 0.011088132858276367 秒
8.总结
完成此次价格预测项目,我深刻体会到了在这个数字化快速发展的时代,如何利用先进的英特尔® ONEAPI AI分析工具包来应对加密货币市场的高波动性和预测挑战。通过实践,我不仅提高了数据清洗、特征工程和模型优化的技能,还学会了如何使用统计指标精确评估模型性能,尤其是在准确度和推理速度上的权衡。项目的完成增强了我的问题解决能力,让我对机器学习在金融科技领域的应用有了更深刻的理解,同时也意识到了数据科学在风险管理和市场分析中的重要作用。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









