






目录
2.2创建一个数据集对象。它主要用于加载狗和猫的图像数据集,并根据数据集的不同模式(train 或 test)来初始化数据集对象。
4.1实现了一个自定义的数据转换函数,用于将NumPy数组转换为PIL图像对象。
5.2使用Intel Extension for PyTorch进行优化
6.总结
1.1项目介绍
1.1问题描述:
使用深度学习进行图像分类,具体来说,是区分图像中是猫还是狗。这个任务在计算机视觉领域是一个经典的问题,通常作为深度学习模型在图像识别方面能力的一个基准测试。这个脚本利用了深度神经网络(在这里是VGG16模型的变种)来自动从图像中提取特征,并进行分类。
1.2预期解决方案
-
数据预处理
- 目标:准备和标准化图像数据以供模型训练和测试使用。
- 方法:使用
DogsVSCatsDataset类来加载图像数据,调整图像尺寸至224x224像素,并进行归一化处理。
-
模型构建
- 目标:构建一个能够有效区分猫和狗图像的深度学习模型。
- 方法:利用改良的VGG16模型(
VGGNet),该模型通过更换最后一层来适应猫狗分类任务。
-
训练和验证
- 目标:训练模型以高准确度分类猫和狗的图像。
- 方法:采用数据增强、合适的损失函数和优化器,进行多次迭代训练,并使用验证数据集来监控模型性能。
-
性能评估
- 目标:评估和验证模型的分类效果。
- 方法:使用测试数据集来评估模型的准确率、召回率等性能指标。
-
优化和调整
- 目标:进一步提高模型性能,减少过拟合。
- 方法:可能包括调整网络结构、增加正则化、改变学习率等策略。
1.3数据及图像展示
test数据集

train数据集
2.数据相关处理
2.1数据转换
# 更新图像尺寸为 224x224
IMAGE_H = 224
IMAGE_W = 224
# 定义一个转换关系,用于将图像数据转换成PyTorch的Tensor形式,并进行标准化处理
data_transform = transforms.Compose([
transforms.Resize((IMAGE_H, IMAGE_W)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])2.2创建一个数据集对象。它主要用于加载狗和猫的图像数据集,并根据数据集的不同模式(train 或 test)来初始化数据集对象。
class DogsVSCatsDataset(data.Dataset):
def __init__(self, mode, dir):
self.mode = mode
self.list_img = []
self.list_label = []
self.data_size = 0
self.transform = data_transform
if self.mode == 'train':
dir = dir + '/train/'
for file in os.listdir(dir):
self.list_img.append(dir + file)
self.data_size += 1
name = file.split(sep='.')
if name[0] == 'cat':
self.list_label.append(0)
else:
self.list_label.append(1)
elif self.mode == 'test1':
dir = dir + '/test1/'
for file in os.listdir(dir):
self.list_img.append(dir + file)
self.data_size += 1
name = file.split(sep='.')
if name[0] == 'cat':
self.list_label.append(0)
else:
self.list_label.append(1)
else:
return print('Undefined Dataset!')2.3实现数据集的索引和长度功能
def __getitem__(self, item):
# 从文件路径中读取图像
img = Image.open(self.list_img[item]).convert('RGB') # 转换为RGB格式
img = data_transform(img) # 应用转换
label = self.list_label[item]
return img, torch.LongTensor([label])
def __len__(self):
return self.data_size3.深度神经网络结构分析和修改
3.1传统CNN
优点:
-
局部特征学习: CNN 通过卷积操作可以有效地捕获图像中的局部特征,这使得它们在识别物体、纹理和形状等方面表现出色。卷积层能够自动学习和提取图像的特征,而不需要手工设计特征。
-
参数共享: CNN 中的权重参数共享使得网络具有较小的参数量。这个特性有助于减少过拟合的风险,并且允许训练更深的网络,从而提高了模型的性能。
-
空间层级表示: CNN 通过多层卷积和池化层逐渐构建出图像的空间层级表示。这意味着底层捕获局部特征,而高层则捕获更抽象的特征,使网络能够理解图像的不同抽象层次。
-
平移不变性: CNN 具有平移不变性,这意味着它们对于物体在图像中的位置变化不敏感。这使得它们适用于对象识别等任务,因为物体的位置可能会发生变化。
-
预训练模型: 通过在大规模数据集上进行预训练,可以将预训练的 CNN 模型迁移到新任务上,从而提高了模型的泛化能力。这种迁移学习方法被广泛应用于各种计算机视觉任务。
缺点:
-
计算和内存开销: CNN 模型通常需要大量的计算资源和内存,特别是在深层网络中。这限制了它们在嵌入式设备和资源有限的环境中的应用。
-
过拟合: 尽管参数共享可以降低过拟合风险,但在小数据集上,仍然可能发生过拟合。解决这个问题的方法包括数据增强和正则化技术。
-
对输入大小敏感: 传统CNN 对于输入图像的大小通常是固定的,这意味着需要在训练和推理时确保输入的大小一致,这可能不太方便。
-
需要大量数据: CNN 在训练中通常需要大量的标记数据,这对于一些任务来说可能难以获得。
3.2 深度神经网络
优点:
-
学习复杂特征表示: 深度神经网络可以学习多层次的特征表示,这有助于捕获输入数据中的更高级别、更抽象的特征。这使得它们在处理复杂任务时表现出色,如图像识别、语音识别和自然语言处理。
-
自动特征提取: DNNs 能够自动地从原始数据中学习到特征,不需要手工设计特征提取器。这简化了模型的构建过程,并允许模型更好地适应不同类型的数据。
-
表现能力强: 深度神经网络有着强大的表现能力,可以逼近各种复杂的函数。这使得它们在各种任务中具有很高的灵活性和性能潜力。
-
大规模数据的泛化: 当有足够大规模的数据进行训练时,深度神经网络通常能够很好地泛化到新的数据,这使得它们在实际应用中表现良好。
-
迁移学习: DNNs 的预训练模型可以用于迁移学习,即在一个任务上训练好的模型可以迁移到另一个相关任务上,从而加速训练和提高性能。
缺点:
-
计算和内存需求: 深度神经网络通常需要大量的计算资源和内存来训练和推理。深层网络可能需要更多的时间来训练,特别是在没有GPU支持的情况下。
-
过拟合: 深度神经网络在小数据集上容易过拟合,这需要采取正则化和数据增强等技术来缓解。
-
超参数选择: 选择适当的深度、层次结构和超参数是一项挑战性的任务,需要进行实验和调整。
-
黑盒性: 深度神经网络通常被认为是黑盒模型,难以理解和解释其内部工作原理,这可能在某些应用中是一个问题。
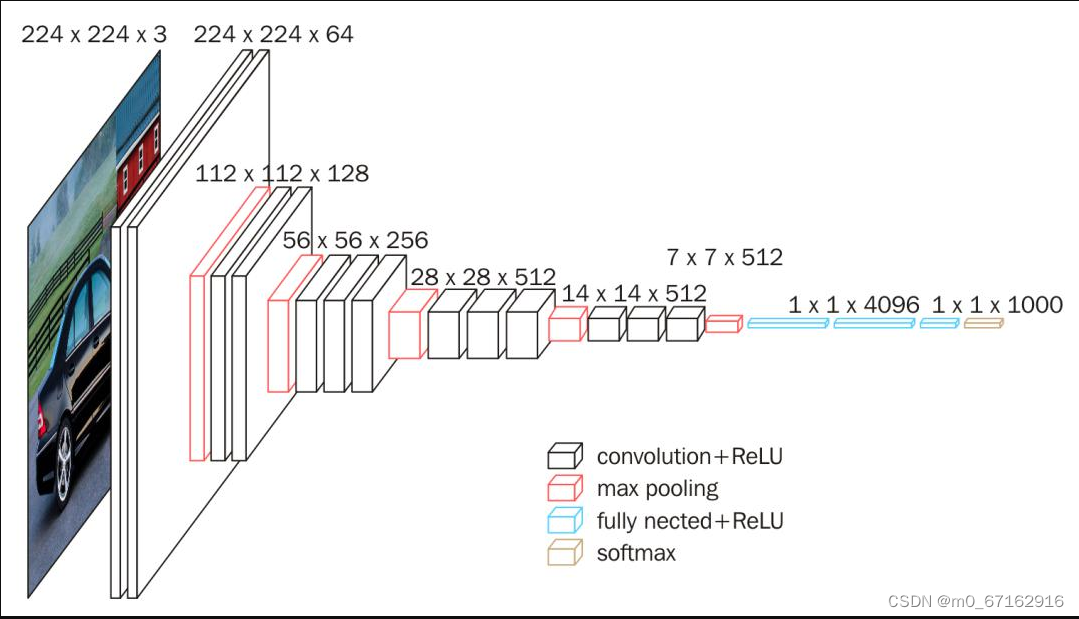
3.3VGG16架构
-
深度: VGG16有16层卷积和全连接层,其中包括13个卷积层和3个全连接层。这是一个相对较深的模型,相对于当时的其他模型来说,层数较多。
-
小卷积核: VGG16主要使用3x3大小的卷积核和1x1大小的卷积核,这些小的卷积核有助于捕获图像中的局部特征,并且通过多层卷积来建立更复杂的特征。
-
池化层: VGG16使用最大池化层来减小特征图的空间维度,帮助提取更高级别的特征并减少计算量。
-
全连接层: 在卷积层之后,VGG16包括3个全连接层,用于进行最终的分类决策。
-
ReLU激活函数: 在每个卷积层和全连接层之后,VGG16使用ReLU(Rectified Linear Unit)激活函数来引入非线性性质。
-
大尺寸输入: VGG16的输入通常是224x224像素大小的图像,这是因为它最初是为ILSVRC(ImageNet Large Scale Visual Recognition Challenge)图像分类竞赛而设计的,其中的图像尺寸是固定的。
-
预训练模型: 由于VGG16在ImageNet数据集上进行了大规模训练,因此可以用作迁移学习的基础模型,即在其他图像任务中,可以利用VGG16的权重来加速训练和提高性能。
4.在GPU上训练
4.1实现了一个自定义的数据转换函数,用于将NumPy数组转换为PIL图像对象。
class ToPILImage(object):
def __call__(self, ndarray):
return Image.fromarray(ndarray)4.2设置数据增强以及定义一些训练相关的超参数和路径
# 设置数据增强
train_transforms = transforms.Compose([
ToPILImage(),
transforms.Resize((224, 224)), # 调整图像大小以适配 VGG
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # 归一化处理
])
dataset_dir = './data/'
model_cp = './model/'
workers = 10
batch_size = 16
lr = 0.0001
epochs = 2 # 训练轮数
4.3训练深度神经网络模型
def train():
# 使用数据增强
train_data = DVCD('train', dataset_dir)
train_data.transform = train_transforms
dataloader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=workers)
model = VGGNet().cuda()
model.train()
optimizer = optim.Adam(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
best_loss = float('inf')
for epoch in range(epochs):
running_loss = 0.0
for img, label in dataloader:
img, label = Variable(img).cuda(), Variable(label).cuda()
optimizer.zero_grad()
out = model(img)
loss = criterion(out, label.squeeze())
loss.backward()
optimizer.step()
running_loss += loss.item()
epoch_loss = running_loss / len(dataloader)
print(f'Epoch {epoch+1}, Loss: {epoch_loss}')
# 早停机制
if epoch_loss < best_loss:
best_loss = epoch_loss
torch.save(model.state_dict(), '{0}/model.pth'.format(model_cp))
else:
print("Early stopping triggered")
break
if __name__ == '__main__':
train()
4.4模型训练后的model过程
4.5使用模型进行推理测试

4.6在test上进行验证
from getdata import DogsVSCatsDataset as DVCD
from network import VGGNet
import torch
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
dataset_dir = './data/' # 数据集路径
model_file = './model/model.pth' # 模型保存路径
def test():
model = VGGNet() # 使用VGGNet模型
model = model.cuda() # 送入GPU,利用GPU计算
model.load_state_dict(torch.load(model_file)) # 加载训练好的模型参数
model.eval() # 设定为评估模式
datafile = DVCD('test1', dataset_dir) # 实例化一个数据集
print('Dataset loaded! length of test set is {0}'.format(len(datafile)))
true_labels = [] # 真实标签列表
predicted_labels = [] # 预测标签列表
for index in range(len(datafile)): # 遍历数据集
img, true_label = datafile[index] # 获取一个图像及其真实标签
img = img.unsqueeze(0)
img = img.cuda()
out = model(img) # 网络前向计算
predicted_label = 1 if out[0, 1] > out[0, 0] else 0
true_labels.append(true_label.item()) # 从tensor转换为python数字
predicted_labels.append(predicted_label)
# 计算精确率和召回率
tp = sum(1 for true, pred in zip(true_labels, predicted_labels) if true == pred == 1)
fp = sum(1 for true, pred in zip(true_labels, predicted_labels) if true == 0 and pred == 1)
fn = sum(1 for true, pred in zip(true_labels, predicted_labels) if true == 1 and pred == 0)
precision = tp / (tp + fp) if (tp + fp) > 0 else 0
recall = tp / (tp + fn) if (tp + fn) > 0 else 0
# 计算F1分数
f1_score = 2 * precision * recall / (precision + recall) if (precision + recall) > 0 else 0
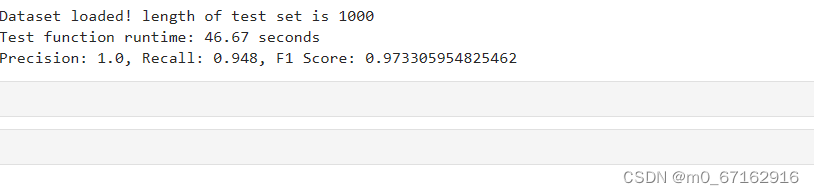
print('Precision:', precision)
print('Recall:', recall)
print('F1 Score:', f1_score)
if __name__ == '__main__':
test()
4.7test.py结果输出

5.在CPU上验证
5.1 在CPU测试训练好的深度神经网络模型的函数
def test():
model = VGGNet() # 加载模型
model.load_state_dict(torch.load(model_file, map_location='cpu')) # 加载权重
model.eval() # 设置为评估模式
model = model.to(memory_format=torch.channels_last) # 转换内存格式
model = ipex.optimize(model) # 应用 IPEX 优化
datafile = DVCD('test1', dataset_dir) # 实例化一个数据集
test_loader = DataLoader(datafile, batch_size=batch_size, shuffle=False)
print('Dataset loaded! length of test set is {0}'.format(len(datafile)))
true_labels = [] # 真实标签列表
predicted_labels = [] # 预测标签列表
start_time = time.time()5.2使用Intel Extension for PyTorch进行优化
优化前
优化后

6.总结
在这个项目中,我们关注的是使用深度学习技术,特别是卷积神经网络(CNN),来解决一个基础但具有挑战性的计算机视觉任务:区分图像中的猫和狗。这个任务不仅在学术上具有重要意义,作为理解深度学习在图像识别应用中的入门案例,也在实际应用中展示了深度学习技术的强大能力。通过DogsVSCatsDataset类,成功处理和标准化了图像数据,以适配神经网络。随后,利用改良后的VGG16模型,即VGGNet,构建了一个强大的模型来进行图像分类。在训练过程中,采用了数据增强、适当的损失函数和优化器,以及验证集进行模型评估和调整,确保了模型的准确性和泛化能力。此外,还通过使用测试集来评估模型的准确率和其他关键性能指标,确保了模型的有效性。
针对未来的改进方向,超参数的调优、尝试更复杂的网络结构以及增加训练数据的多样性和数量都是值得探索的领域。这个项目不仅提供了深入理解深度学习在图像分类任务中的应用的机会,也为处理更复杂的图像识别任务打下了坚实的基础。















 1962
1962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









