






一、对BPR_loss的理解
BPR_loss(Bayesian Personalized Ranking loss)是一种用于推荐系统中的损失函数,用于衡量预测的排序与真实的用户行为排序之间的差异,使正样本和负样本的得分之差尽可能达到最大。BPR_loss的计算过程如下:
输入:BPR_loss的输入包括用户u、物品i和物品j,即一个三元组<u,i,j>。表示用户u对物品i和物品j的偏好,其中,u对i的偏好大于u对j的偏好。
预测得分计算:首先,通过计算用户u对物品i和物品j的预测得分来衡量用户对物品的偏好程度。预测得分是通过用户u的潜在因子向量和物品i、物品j的潜在因子向量之间的内积得到的,即score(u,i) = wu • hi和score(u,j) = wu • hj^T。
损失计算:接下来,使用BPR_loss来计算预测得分的排序损失。BPR_loss的目标是最大化用户对正样本物品(i)的偏好得分与对负样本物品(j)的偏好得分之间的差异。具体地,BPR_loss定义为负对数似然损失函数,即L = -log σ(score(u,i) - score(u,j)),其中σ(x)表示Sigmoid函数,将x映射到(0,1)之间。
参数更新:在训练过程中,使用梯度下降法来最小化BPR_loss。即通过计算BPR_loss对用户u和物品i、物品j的潜在因子向量的偏导数,来更新这些潜在因子的数值。具体计算可参考https://blog.csdn.net/qq_46006468/article/details/125987744
通过最小化BPR_loss,推荐系统可以学习到一组潜在因子向量,从而对用户的偏好进行准确预测和排序。这样,在给定用户和物品的情况下,推荐系统可以根据得分来推荐合适的物品给用户。
对潜在因子向量的理解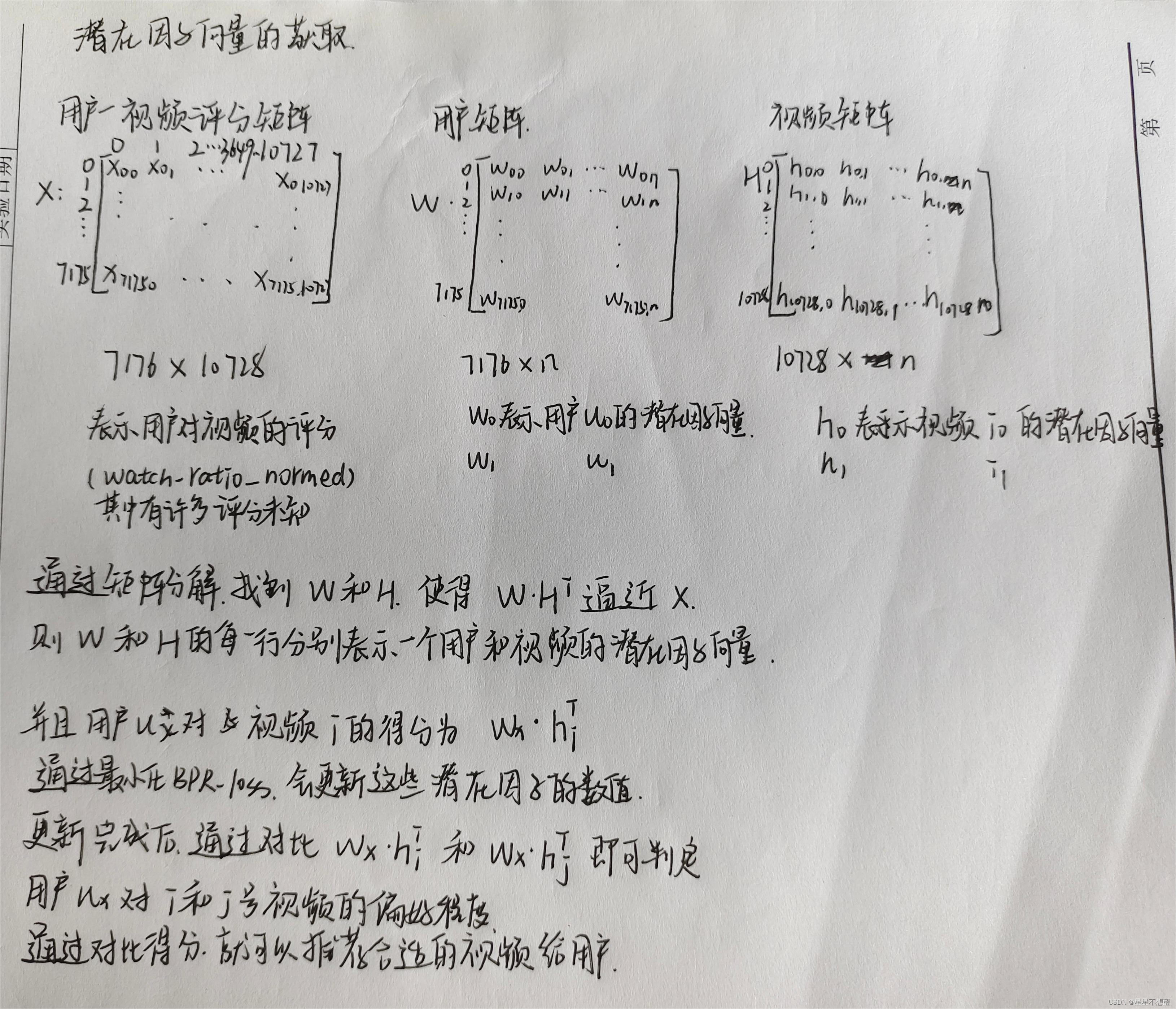
二、对MCD的理解
论文的 5.2 Matthew Effect 中对MCD的解释如下:
To quantify the Matthew effect in the results of recommendation,we use a metric: majority category domination (MCD), which is deffned asthe percentage of the recommended items that are labeled as the dominated categories in training data.
即MCD被定义为在训练数据中标记为主导类别的物品在推荐结果中所占的比例。换句话说,MCD衡量了推荐系统在其输出中主导类别的影响程度。进而,MCD可用于量化推荐结果中的马太效应。MCD越大表示推荐结果中的马太效应越强,MCD越小表示推荐结果中的马太效应越弱。
代码中根据环境名称获取训练中的物品主导信息(run_worldModel_ensemble.py中第三步539行)
![]()

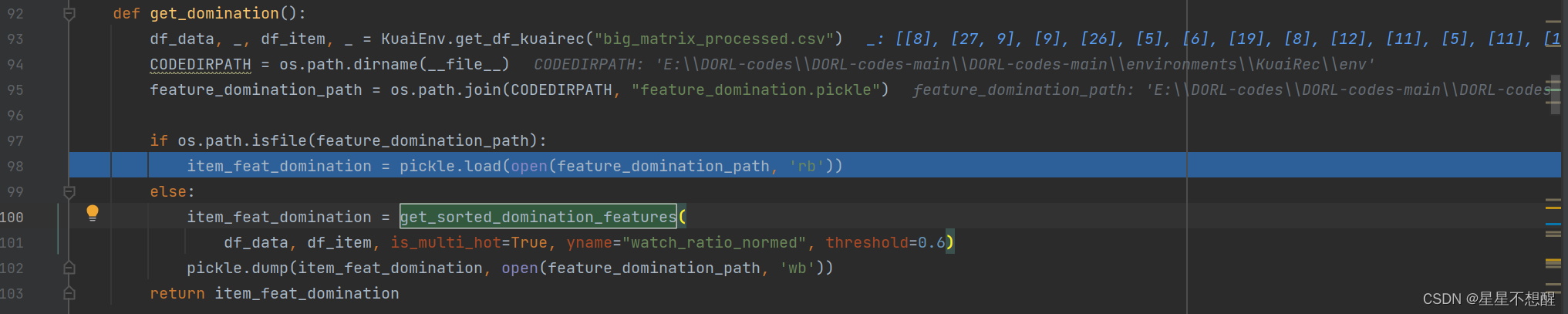
通过统计每个类别在数据集中的百分比并从高至低排序后,得到 item_feat_domination

从上至下,所示类别占据主导地位的强度逐渐下降。也就是说,类别28的主导性最强,类别24的主导性最弱。
由论文中对MCD的定义处的注释4知:主导类别要求覆盖训练集中80%的物品,在KuaiRand的46个类别中主导类别有13个,在KuaiRec的31个类别中主导类别有12个.















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









