







##################################################
目录
##################################################
活动简介
活动地址:CSDN21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰;一个人摸索学习很难坚持,想组团高效学习;想写博客但无从下手,急需写作干货注入能量;热爱写作,愿意让自己成为更好的人…
…
欢迎参与CSDN学习挑战赛,成为更好的自己,请参考活动中各位优质专栏博主的免费高质量专栏资源(这部分优质资源是活动限时免费开放喔~),按照自身的学习领域和学习进度学习并记录自己的学习过程,或者按照自己的理解发布专栏学习作品!
##################################################
详解 字典/列表/元组
——————————
最常见的三种数据类型
Python 主要有三种数据类型 字典、列表、元组
其分别由如下表示
花括号字典
中括号列表
小括号元组
示例:
dic = { 'a':12, 'b':34 } /* 字典 */
list = [ 1, 2, 3, 4 ] /* 列表 */
tup = ( 1, 2, 3, 4 ) /* 元组 */%%%%%
元组
小括号 () 代表 tuple/元组 数据类型
元组是一种不可变序列
其创建方法很简单 大多时候都是用小括号括起来的 示例:
Microsoft Windows [版本 6.3.9600]
(c) 2013 Microsoft Corporation。保留所有权利。
C:\Users\byme>python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (
AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> tup = ( 1, 2, 3 ) /* 创建一个元组 */
>>> tup
(1, 2, 3)
>>> type ( tup )
<class 'tuple'>
>>> () /* 空元组 */
()
>>> 55, /* 一个值的元组 */
(55,)
>>> %%%%%
列表
中括号 [] 代表 list/列表 数据类型
列表是一种可变的序列
其创建方法即简单又特别:
>>> list ( "Python" )
['P', 'y', 't', 'h', 'o', 'n']
>>> %%%%%
字典
大括号 {} 花括号 代表 dict 字典数据类型
字典是由键对值组组成
冒号分开 键 和 值
逗号隔开 组
示例:
>>> dic = { "崽崽":"女", "仔仔":"男" }
>>> dic
{'仔仔': '男', '崽崽': '女'}
>>> %%%%%
根据括号判断数据类型
Python 语言最常见的括号有三种 分别是
小括号 ()
中括号 []
大括号也叫做花括号 {}
其作用也各不相同 分别用来代表不同的 Python 基本内置数据类型
——————————
为什么必须要加转义符转义
看下面这个例子:
re.findall() 函数可以遍历匹配获取字符串中所有匹配的字符串返回的是一个列表
C:\Users\byme>python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (
AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.findall ( r"\.", "\." )
['.']
>>> 可以看出加上
\这个转义符号
\.才能表示一个点:
.##################################################
简单接触 Python 正则表达式
——————————
匹配单个字符
%%%%%
符号 ./点 的用法
点表示一个字符 具体演示请看:
C:\Users\byme>python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (
AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import re /* 导入正则表达式模块 */
>>>
>>> r = re.match ( "", "崽" ) /* match 方法从开头扫描 第一个参数是规则 第二个参数是目标文本 */
>>> r.group() /* group 函数表示提取分组截获的字符 上一条代码没有匹配规则所以什么都没有提取到 */
''
>>> r = re.match ( ".", "喜欢崽崽" ) /* 匹配规则为 提取第一个字符 */
>>> r.group() /* 查看上一行代码截取到的字符 */
'喜'
>>> r = re.match ( "喜.崽", "喜欢崽崽" ) /* 提取 '喜' 和 '崽' 之间的那个字符 */
>>> r.group() /* 查看提取结果 */
'喜欢崽'
>>> 为什么一定要用 group 方法
group() 输出的其实就是 match
演示:
>>> r = re.match ( ".", "崽崽崽" )
>>> r.group()
'崽'
>>> r /* 可以看到如下信息 span 表示范围 match 表示提取到的字符 */
<re.Match object; span=(0, 1), match='崽'>
>>> r = re.match ( "喜.崽", "喜欢崽崽" )
>>> r
<re.Match object; span=(0, 3), match='喜欢崽'>
>>> %%%%%
符号 []/或 的用法
如下:
>>> r = re.match ( "A", "abc" ) /* 匹配条件是大写 目标文本确是小写 */
>>> r.group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> r = re.match ( "A", "Abc" ) /* 如果条件是大写字母 则目标也必须是大写字母 */
>>> r.group()
'A'
>>> r = re.match ( "a", "abc" ) /* 如果条件是小写 目标也必须是小写 */
>>> r.group()
'a'
>>> 第一个字符是大写或者小写都可以:
>>> r = re.match ( "[aA]", "aAbc" )
>>> r.group()
'a'
>>> r = re.match ( "[aA]", "Abc" )
>>> r.group()
'A'
>>> 就是判断第一个字符是不是 [] 中的:
>>> r = re.match ( "[我你]", "我爱你" )
>>> r.group()
'我'
>>> r = re.match ( "[我你]", "你爱我" )
>>> r.group()
'你'
>>> r = re.match ( "[我你]", "她爱他" )
>>> r.group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> 当然也可以指定范围 这边以数字示例 你也可以测试字母 一样的 只不过分大小写:
>>> r = re.match ( "一共有[0123456789]个坑队友", "一共有4个坑队友" )
>>> r.group()
'一共有4个坑队友'
>>> r = re.match ( "一共有[0-9]个坑队友", "一共有4个坑队友" )
>>> r.group()
'一共有4个坑队友'
>>> r = re.match ( "一共有[035-9]个坑队友", "一共有4个坑队友" ) /* 唯独匹配不到数字 4 此时 r 为 None */
>>> r.group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> %%%%%
符号 %d/匹配数字 的用法
就是匹配数字的:
>>> r = re.match ( "有\d个崽崽", "有1个崽崽!" )
>>> r.group()
'有1个崽崽'
>>> r = re.match ( "有\d个崽崽", "有2个崽崽!" )
>>> r.group()
'有2个崽崽'
>>> ——————————
匹配多个字符
%%%%%
符号 */前一个字符出现至少零次 用法
匹配规则为:
[A-Z] 表示字符串的首字母为大写
[a-z] 表示后面的这个字母必须为小写
* 表示上一个字母可以出现零次或无数次
>>> r = re.match ( "[A-Z][a-z]*", "G" )
>>> r.group()
'G'
>>> r = re.match ( "[A-Z][a-z]*", "GgFuck" )
>>> r.group()
'Gg'
>>> r = re.match ( "[A-Z][a-z]*", "Ggfuck" )
>>> r.group()
'Ggfuck'
>>> %%%%%
符号 +/前一个字符出现至少一次 用法
根据判断字符串是否符合
[a-zA-Z_]+[\w]规则:
前一个字母必须是
或小写的
或大写的
或者是下划线
且必须出现至少一次
test.py code:
这个脚本就不注释了 如果你看得懂大概逻辑 你就非常适合写程序!!!
import re
strS = [ "str1", "_str", "2_str", "__str__" ]
for str in strS:
r = re.match ( "[a-zA-Z_]+[\w]", str )
if r:
print ( "字符串 %s 符合要求!" % r.group () )
else:
print ( "字符串 %s 是非法的.." % str )VSCode demo:
Windows PowerShell
版权所有 (C) 2014 Microsoft Corporation。保留所有权利。
PS C:\Users\byme> python -u "e:\PY\test.py"
字符串 str1 符合要求!
字符串 _str 符合要求!
字符串 2_str 是非法的..
字符串 __str__ 符合要求!
PS C:\Users\byme> 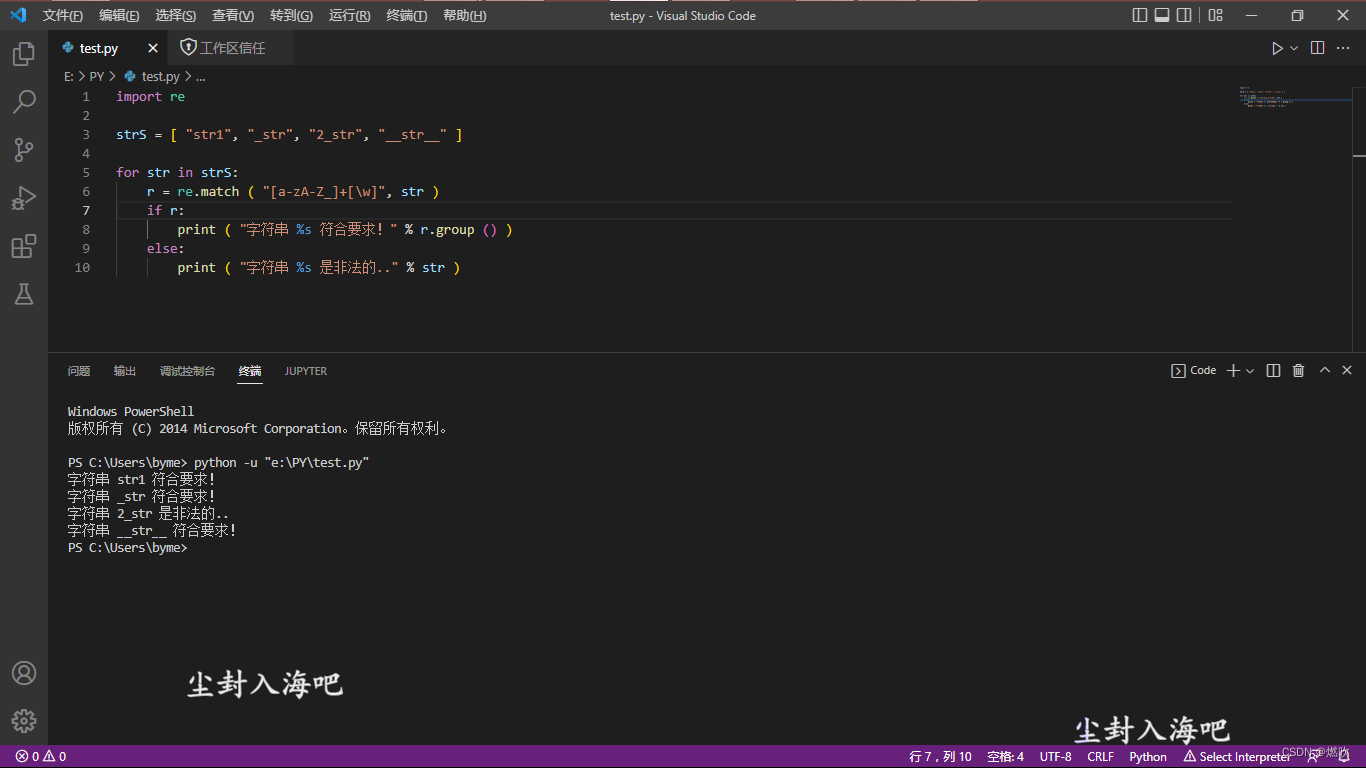
%%%%%
符号 ?/前一个字符必须出现一次或者不出现 用法
示例 匹配出 0 到 99 之间的数字:
>>> r = re.match ( "[1-9]?[0-9]", "5" )
>>> r.group ()
'5'
>>> r = re.match ( "[1-9]?\d", "52" )
>>> r.group ()
'52'
>>> %%%%%
符号 m/上一个字符出现了 m 次 用法
匹配出前 8 密码 可以是大小写英文字母和数字:
>>> r = re.match ( "[a-zA-Z0-9]{8}", "82s4h12452" )
>>> r.group ()
'82s4h124'
>>> 匹配出前 6 到 15 位的密码 可以是大小写英文字母、数字、下划线 示例:
>>> r = re.match ( "[a-zA-Z0-9_]{6,15}", "3sa43t65C23656Xp09" )
>>> r.group ()
'3sa43t65C23656X'
>>> ——————————
匹配开头结尾
%%%%%
符号 ^/匹配字符串开头 用法
匹配以 139 开头的电话号码 示例:
>>> r = re.match ( "^139[0-9]{8}", "13968576141" ) /* 开头必须是 139 后面一个是数字 而 {8} 表示这个数字可以再出现 (8-1) 次 */
>>> r.group ()
'13968576141'
>>> r = re.match ( "^139[0-9]{8}", "15968576141" ) /* 开头不对就不会截取 */
>>> r.group ()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> %%%%%
符号 $/匹配字符串结尾 用法
匹配输出 163 的邮箱地址 而且 @ 符号之前有 6 到 15 位
例如
ooxxYMD@163.comtest.py code:
import re
email_S = { "ooxxYMD@163.com", "ooxxYMD@163.comnet", ".ooxxYMD@qq.com" }
for email in email_S:
r = re.match ( "[\w]{6,15}@163\.com$", email )
if r:
print ( "[%s] 是合法的邮件地址,匹配后的结果为 >>> [%s]" % ( email, r.group() ) )
else:
print ( "[%s] 非法!" % email )VSCode demo:
Windows PowerShell
版权所有 (C) 2014 Microsoft Corporation。保留所有权利。
PS C:\Users\byme> python -u "e:\PY\test.py"
[.ooxxYMD@qq.com] 非法!
[ooxxYMD@163.com] 是合法的邮件地址,匹配后的结果为 >>> [ooxxYMD@163.com]
[ooxxYMD@163.comnet] 非法!
PS C:\Users\byme> 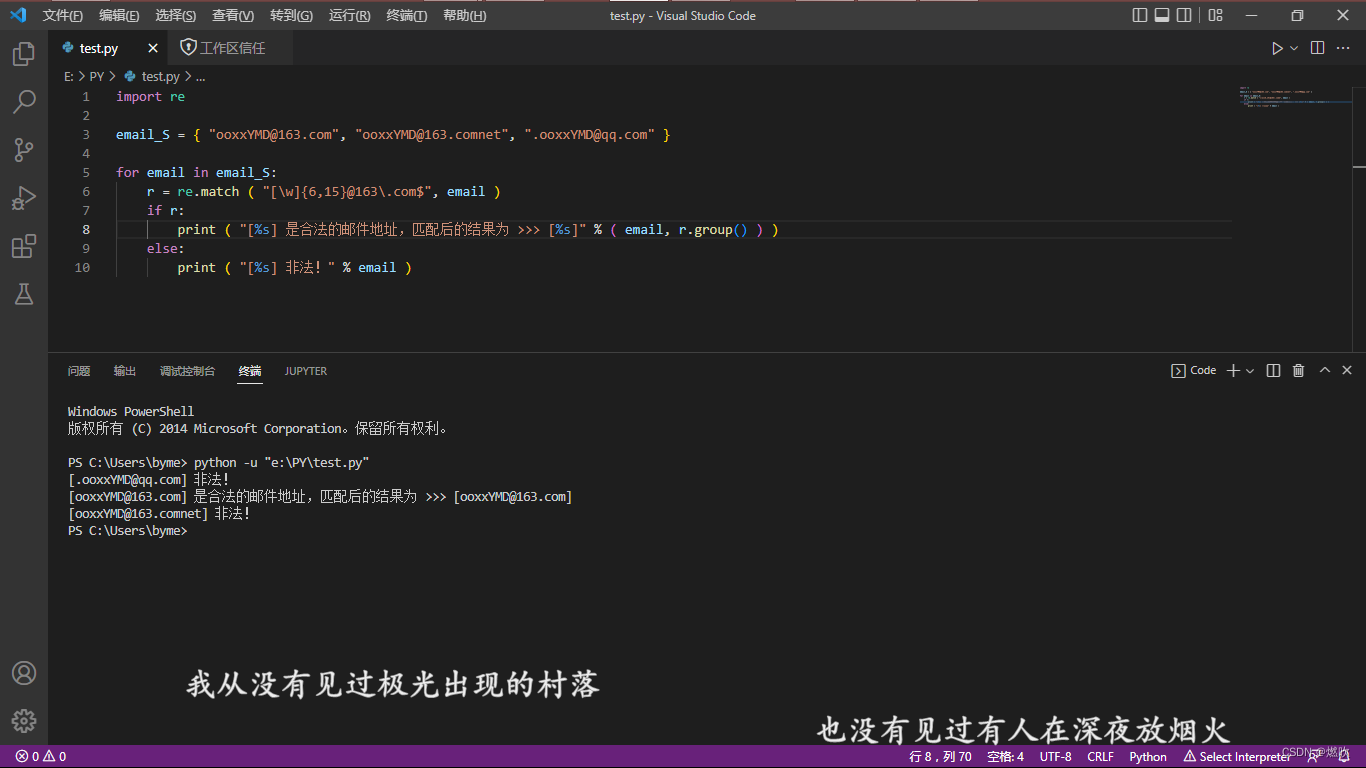
——————————
分组匹配
%%%%%
符号 |/两项都匹配 用法
匹配出 0~100 之间的数字!
>>> r = re.match ( "[1-9]?\d", "0" )
>>> r.group()
'0'
>>> r = re.match ( "[1-9]?\d", "52" )
>>> r.group()
'52'
>>> r = re.match ( "[1-9]?\d", "02" ) /* 这样不对啊 */
>>> r.group()
'0'
>>>
还可以在交互模式中写脚本:
>>> import re
>>> r = re.match ( "[1-9]?\d$", "02" )
>>> if r: /* 冒号!!! */
... print ( r.group () ) /* 可用 TAB 缩进 */
... else:
... print ( "不在 0~100 之间.." )
...
不在 0~100 之间..
>>> 使用 | 符号:
>>> r = re.match ( "[1-9]?\d$|100", "52" )
>>> r.group()
'52'
>>> r = re.match ( "[1-9]?\d$|100", "100" )
>>> r.group()
'100'
>>> %%%%%
符号 ()/括号中是一个分组 用法
示例匹配 163、126、qq 邮箱:
C:\Users\byme>python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (
AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>>
>>> r = re.match ( "\w{6,15}@163\.com", "Python@163.com" )
>>> r.group ()
'Python@163.com'
>>>
>>> r = re.match ( "\w{6,15}@(163|126|qq)\.com", "Python@126.com" )
>>> r.group ()
'Python@126.com'
>>>
>>> r = re.match ( "\w{6,15}@(163|126|qq)\.com", "Python@qq.com" )
>>> r.group ()
'Python@qq.com'
>>>
>>> r = re.match ( "\w{6,15}@163\.com", "Python@test.com" )
>>> if r:
... print ( r.group () )
... else:
... print ( "不是如下邮箱 >>> [163|126|qq] ..!" )
...
不是如下邮箱 >>> [163|126|qq] ..!
>>> 不是以 4、7 结尾的 11 位手机号码:
import re
tels = ["13100001234", "18912344321", "10086", "18800007777"]
tels = ["73834629344", "19488342830", "18611", "99999999987"]
for tel in tels:
ret = re.match ( "1\d{9}[0-35-68-9]", tel )
if ret:
print ( ret.group () )
else:
print ( ">>> [%s] 不是想要的手机号" % tel )VSCode demo:
Windows PowerShell
版权所有 (C) 2014 Microsoft Corporation。保留所有权利。
PS C:\Users\byme> python -u "e:\PY\test.py"
>>> [73834629344] 不是想要的手机号
19488342830
>>> [18611] 不是想要的手机号
>>> [99999999987] 不是想要的手机号
PS C:\Users\byme> 提取区号和电话号码 示例:
C:\Users\byme>python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (
AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>>
>>> r = re.match ( "([^-]*)-(\d+)", "131-12345678" )
>>> r.group ()
'131-12345678'
>>> r.group ( 1 )
'131'
>>> r.group(2)
'12345678'
>>> 
















 202
202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











