




 本文详细剖析了Linux内核从用户态send调用到数据通过网卡发送出去的全过程,包括网卡启动准备、socket创建、传输层处理、网络层处理、邻居子系统、网络设备子系统、软中断调度、网卡驱动发送和发送完成硬中断。通过源码分析解释了内存拷贝、软中断与硬中断在发送过程中的角色,以及NET_RX和NET_TX软中断差异的原因。文章适合对Linux内核和网络感兴趣的读者深入学习。
本文详细剖析了Linux内核从用户态send调用到数据通过网卡发送出去的全过程,包括网卡启动准备、socket创建、传输层处理、网络层处理、邻居子系统、网络设备子系统、软中断调度、网卡驱动发送和发送完成硬中断。通过源码分析解释了内存拷贝、软中断与硬中断在发送过程中的角色,以及NET_RX和NET_TX软中断差异的原因。文章适合对Linux内核和网络感兴趣的读者深入学习。
在开始今天的文章之前,我先来请大家思考几个小问题。
-
问1:我们在查看内核发送数据消耗的 CPU 时,是应该看 sy 还是 si ?
-
问2:为什么你服务器上的 /proc/softirqs 里 NET_RX 要比 NET_TX 大的多的多?
-
问3:发送网络数据的时候都涉及到哪些内存拷贝操作?
这些问题虽然在线上经常看到,但我们似乎很少去深究。如果真的能透彻地把这些问题理解到位,我们对性能的掌控能力将会变得更强。
带着这三个问题,我们开始今天对 Linux 内核网络发送过程的深度剖析。还是按照我们之前的传统,先从一段简单的代码作为切入。如下代码是一个典型服务器程序的典型的缩微代码:
int main(){
fd = socket(AF_INET, SOCK_STREAM, 0);
bind(fd, ...);
listen(fd, ...);
cfd = accept(fd, ...);
// 接收用户请求
read(cfd, ...);
// 用户请求处理
dosometing();
// 给用户返回结果
send(cfd, buf, sizeof(buf), 0);
}
今天我们来讨论上述代码中,调用 send 之后内核是怎么样把数据包发送出去的。本文基于Linux 3.10,网卡驱动采用Intel的igb网卡举例。
预警:本文共有一万多字,25 张图,长文慎入!
一、Linux 网络发送过程总览
我觉得看 Linux 源码最重要的是得有整体上的把握,而不是一开始就陷入各种细节。
我这里先给大家准备了一个总的流程图,简单阐述下 send 发送了的数据是如何一步一步被发送到网卡的。
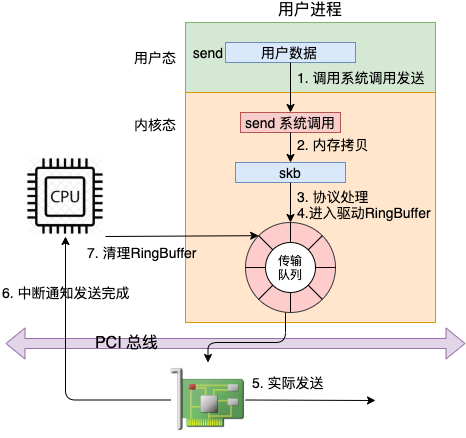
在这幅图中,我们看到用户数据被拷贝到内核态,然后经过协议栈处理后进入到了 RingBuffer 中。随后网卡驱动真正将数据发送了出去。当发送完成的时候,是通过硬中断来通知 CPU,然后清理 RingBuffer。
因为文章后面要进入源码,所以我们再从源码的角度给出一个流程图。
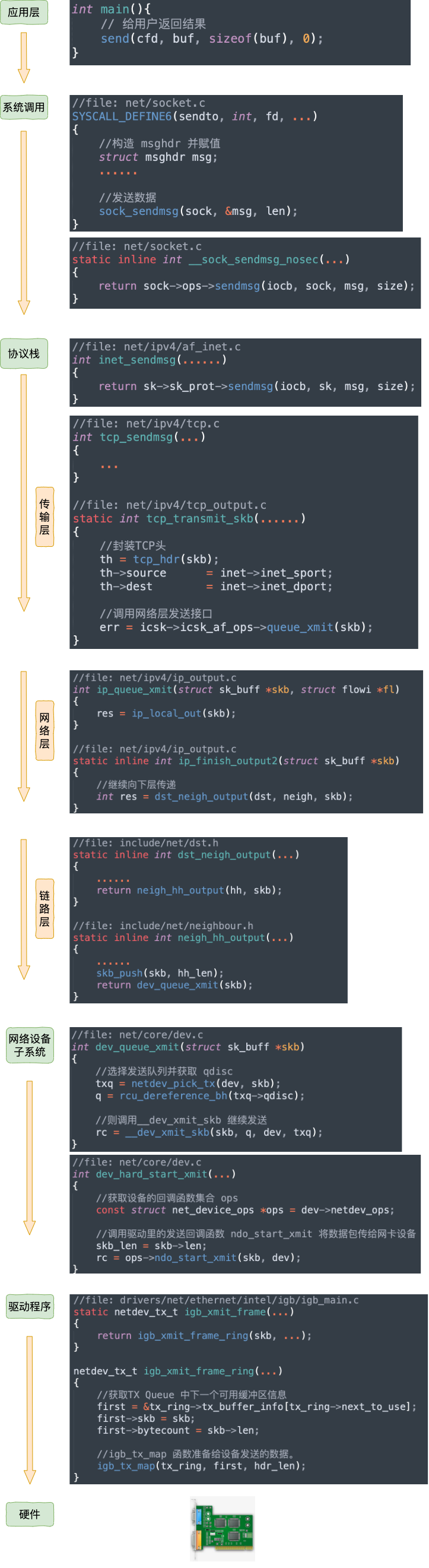
虽然数据这时已经发送完毕,但是其实还有一件重要的事情没有做,那就是释放缓存队列等内存。
那内核是如何知道什么时候才能释放内存的呢,当然是等网络发送完毕之后。网卡在发送完毕的时候,会给 CPU 发送一个硬中断来通知 CPU。更完整的流程看图:
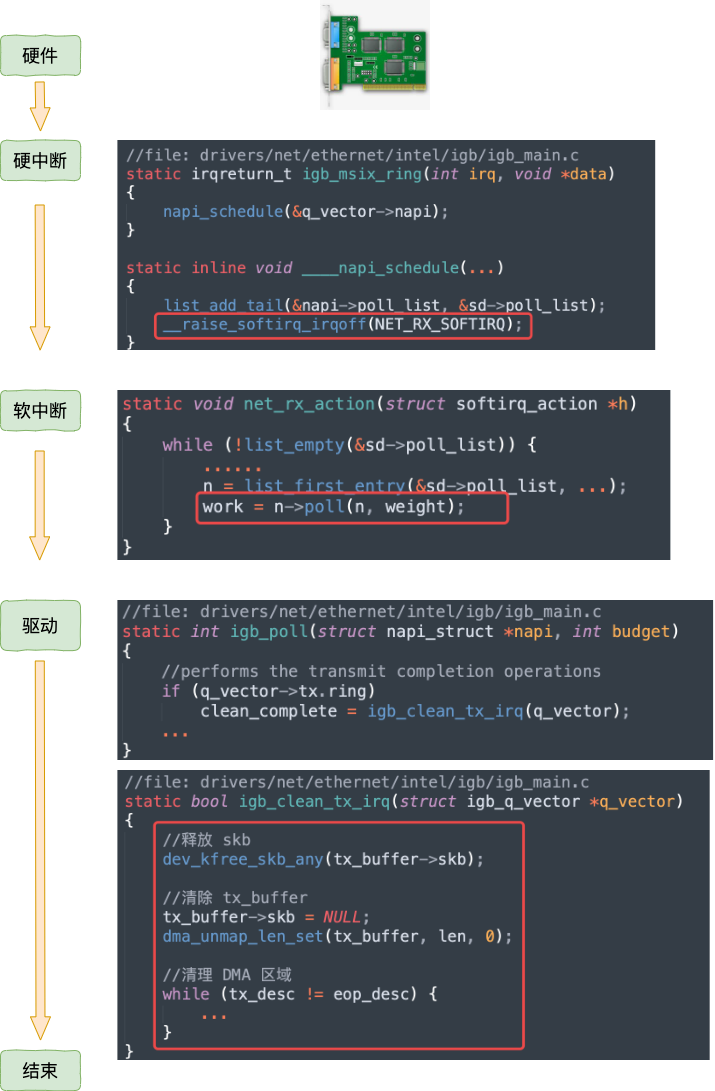
注意,我们今天的主题虽然是发送数据,但是硬中断最终触发的软中断却是 NET_RX_SOFTIRQ,而并不是 NET_TX_SOFTIRQ !!!(T 是 transmit 的缩写,R 表示 receive)
意不意外,惊不惊喜???
所以这就是开篇问题 1 的一部分的原因(注意,这只是一部分原因)。
问1:在服务器上查看 /proc/softirqs,为什么 NET_RX 要比 NET_TX 大的多的多?
传输完成最终会触发 NET_RX,而不是 NET_TX。所以自然你观测 /proc/softirqs 也就能看到 NET_RX 更多了。
好,现在你已经对内核是怎么发送网络包的有一个全局上的把握了。不要得意,我们需要了解的细节才是更有价值的地方,让我们继续!!
二、网卡启动准备
现在的服务器上的网卡一般都是支持多队列的。每一个队列上都是由一个 RingBuffer 表示的,开启了多队列以后的的网卡就会对应有多个 RingBuffer。
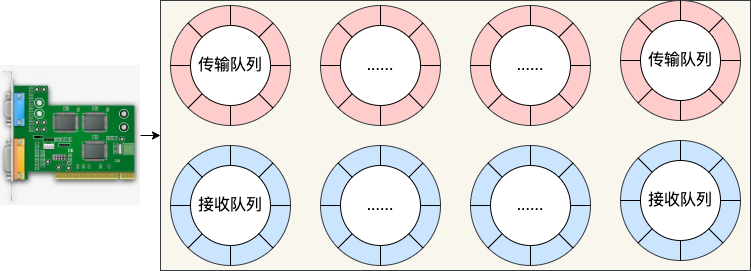
网卡在启动时最重要的任务之一就是分配和初始化 RingBuffer,理解了 RingBuffer 将会非常有助于后面我们掌握发送。因为今天的主题是发送,所以就以传输队列为例,我们来看下网卡启动时分配 RingBuffer 的实际过程。
在网卡启动的时候,会调用到 __igb_open 函数,RingBuffer 就是在这里分配的。
//file: drivers/net/ethernet/intel/igb/igb_main.c
static int __igb_open(struct net_device *netdev, bool resuming)
{
struct igb_adapter *adapter = netdev_priv(netdev);
//分配传输描述符数组
err = igb_setup_all_tx_resources(adapter);
//分配接收描述符数组
err = igb_setup_all_rx_resources(adapter);
//开启全部队列
netif_tx_start_all_queues(netdev);
}
在上面 __igb_open 函数调用 igb_setup_all_tx_resources 分配所有的传输 RingBuffer, 调用 igb_setup_all_rx_resources 创建所有的接收 RingBuffer。
//file: drivers/net/ethernet/intel/igb/igb_main.c
static int igb_setup_all_tx_resources(struct igb_adapter *adapter)
{
//有几个队列就构造几个 RingBuffer
for (i = 0; i < adapter->num_tx_queues; i++) {
igb_setup_tx_resources(adapter->tx_ring[i]);
}
}
真正的 RingBuffer 构造过程是在 igb_setup_tx_resources 中完成的。
//file: drivers/net/ethernet/intel/igb/igb_main.c
int igb_setup_tx_resources(struct igb_ring *tx_ring)
{
//1.申请 igb_tx_buffer 数组内存
size = sizeof(struct igb_tx_buffer) * tx_ring->count;
tx_ring->tx_buffer_info = vzalloc(size);
//2.申请 e1000_adv_tx_desc DMA 数组内存
tx_ring->size = tx_ring->count * sizeof(union e1000_adv_tx_desc);
tx_ring->size = ALIGN(tx_ring->size, 4096);
tx_ring->desc = dma_alloc_coherent(dev, tx_ring->size,
&tx_ring->dma, GFP_KERNEL);
//3.初始化队列成员
tx_ring->next_to_use = 0;
tx_ring->next_to_clean = 0;
}
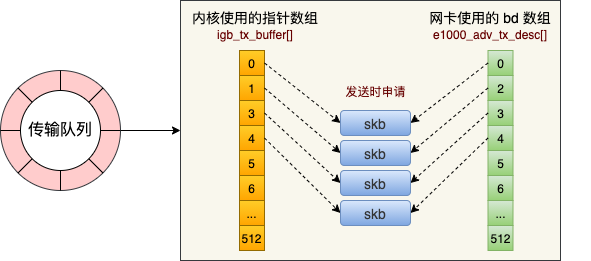
从上述源码可以看到,实际上一个 RingBuffer 的内部不仅仅是一个环形队列数组,而是有两个。
1)igb_tx_buffer 数组:这个数组是内核使用的,通过 vzalloc 申请的。
2)e1000_adv_tx_desc 数组:这个数组是网卡硬件使用的,硬件是可以通过 DMA 直接访问这块内存,通过 dma_alloc_coherent 分配。
这个时候它们之间还没有啥联系。将来在发送的时候,这两个环形数组中相同位置的指针将都将指向同一个 skb。这样,内核和硬件就能共同访问同样的数据了,内核往 skb 里写数据,网卡硬件负责发送。
最后调用 netif_tx_start_all_queues 开启队列。另外,对于硬中断的处理函数 igb_msix_ring 其实也是在 __igb_open 中注册的。
三、accept 创建新 socket
在发送数据之前,我们往往还需要一个已经建立好连接的 socket。
我们就以开篇服务器缩微源代码中提到的 accept 为例,当 accept 之后,进程会创建一个新的 socket 出来,然后把它放到当前进程的打开文件列表中,专门用于和对应的客户端通信。
假设服务器进程通过 accept 和客户端建立了两条连接,我们来简单看一下这两条连接和进程的关联关系。
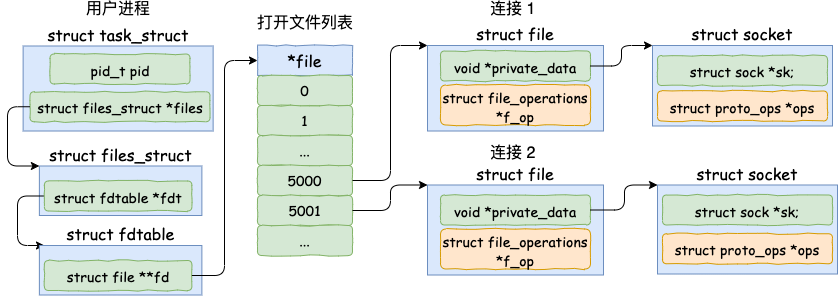
其中代表一条连接的 socket 内核对象更为具体一点的结构图如下。
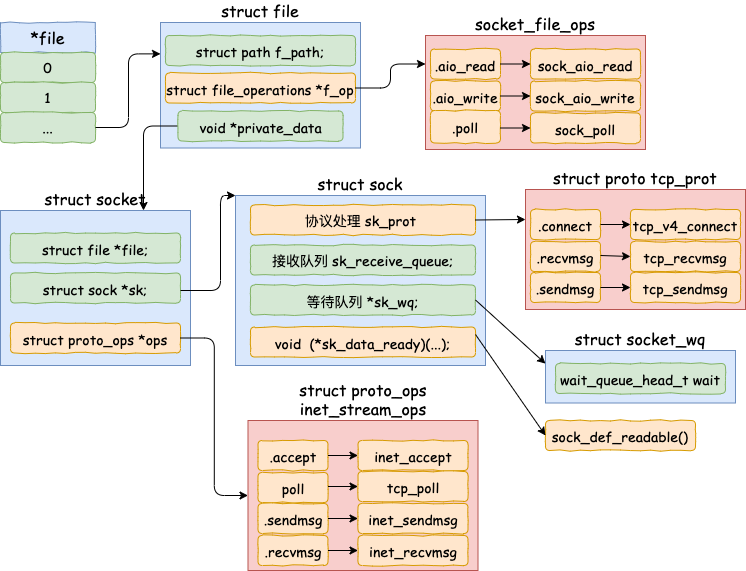
为了避免喧宾夺主,accept 详细的源码过程这里就不介绍了,感兴趣请参考 《图解 | 深入揭秘 epoll 是如何实现 IO 多路复用的!》。一文中的第一部分。
今天我们还是把重点放到数据发送过程上。
四、发送数据真正开始
4.1 send 系统调用实现
send 系统调用的源码位于文件 net/socket.c 中。在这个系统调用里,内部其实真正使用的是 sendto 系统调用。整个调用链条虽然不短,但其实主要只干了两件简单的事情,
-
第一是在内核中把真正的 socket 找出来,在这个对象里记录着各种协议栈的函数地址。
-
第二是构造一个 struct msghdr 对象,把用户传入的数据,比如 buffer地址、数据长度啥的,统统都装进去.
剩下的事情就交给下一层,协议栈里的函数 inet_sendmsg 了,其中 inet_sendmsg 函数的地址是通过 socket 内核对象里的 ops 成员找到的。大致流程如图。
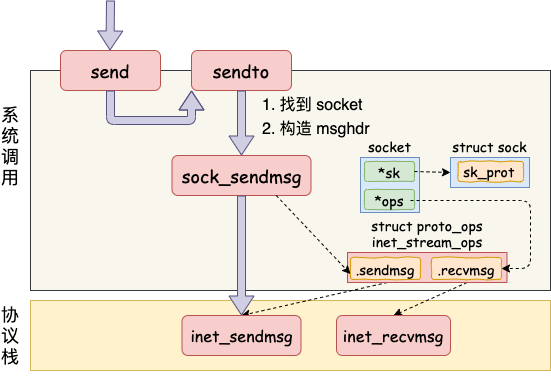
有了上面的了解,我们再看起源码就要容易许多了。源码如下:
//file: net/socket.c
SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len,
unsigned int, flags)
{
return sys_sendto(fd, buff, len, flags, NULL, 0);
}
SYSCALL_DEFINE6(......)
{
//1.根据 fd 查找到 socket
sock = sockfd_lookup_light(fd, &err, &fput_needed);
//2.构造 msghdr
struct msghdr msg;
struct iovec iov;
iov.iov_base = buff;
iov.iov_len = len;
msg.msg_iovlen = 1;
msg.msg_iov = &iov;
msg.msg_flags = flags;
......
//3.发送数据
sock_sendmsg(sock, &msg, len);
}
从源码可以看到,我们在用户态使用的 send 函数和 sendto 函数其实都是 sendto 系统调用实现的。send 只是为了方便,封装出来的一个更易于调用的方式而已。
在 sendto 系统调用里,首先根据用户传进来的 socket 句柄号来查找真正的 socket 内核对象。接着把用户请求的 buff、len、flag 等参数都统统打包到一个 struct msghdr 对象中。
接着调用了 sock_sendmsg => __sock_sendmsg ==> __sock_sendmsg_nosec。在__sock_sendmsg_nosec 中,调用将会由系统调用进入到协议栈,我们来看它的源码。
//file: net/socket.c
static inline int __sock_sendmsg_nosec(...)
{
......
return sock->ops->sendmsg(iocb, sock, msg, size);
}
通过第三节里的 socket 内核对象结构图,我们可以看到,这里调用的是 sock->ops->sendmsg 实际执行的是 inet_
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3363
3363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









