







一、消费者相关概念
1.1 消费组&消费者
消费者:
- 消费者从订阅的主题消费消息,消费消息的偏移量保存在Kafka的名字是
__consumer_offsets的主题中 - 消费者还可以将⾃⼰的偏移量存储到
Zookeeper,需要设置offset.storage=zookeeper - 推荐使⽤Kafka存储消费者的偏移量。因为Zookeeper不适合⾼并发。
消费组:
- 多个从同⼀个主题消费的消费者可以加⼊到⼀个消费组中
- 消费组中的消费者共享group_id。配置方法:
configs.put("group.id", "xxx"); - group_id⼀般设置为应⽤的逻辑名称。⽐如多个订单处理程序组成⼀个消费组,可以设置group_id为"order_process"
- group_id通过消费者的配置指定:
group.id=xxxxx - 消费组均衡地给消费者分配分区,每个分区只由消费组中⼀个消费者消费
⼀个拥有四个分区的主题,包含⼀个消费者的消费组
此时,消费组中的消费者消费主题中的所有分区。并且没有重复的可能。

如果在消费组中添加⼀个消费者2,则每个消费者分别从两个分区接收消息
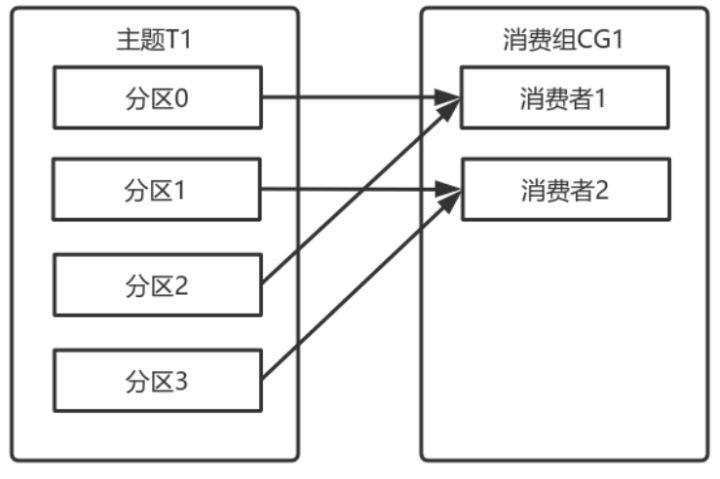
如果消费组有四个消费者,则每个消费者可以分配到⼀个分区

如果向消费组中添加更多的消费者,超过主题分区数量,则有⼀部分消费者就会闲置,不会接收任何消息

向消费组添加消费者是横向扩展消费能⼒的主要⽅式。
必要时,需要为主题创建⼤量分区,在负载增⻓时可以加⼊更多的消费者。但是不要让消费者的数量超过主题分区的数量。

除了通过增加消费者来横向扩展单个应⽤的消费能⼒之外,经常出现多个应⽤程序从同⼀个主题消费的情况。
此时,每个应⽤都可以获取到所有的消息。只要保证每个应⽤都有⾃⼰的消费组,就可以让它们获取到主题所有的消息。
横向扩展消费者和消费组不会对性能造成负⾯影响。
为每个需要获取⼀个或多个主题全部消息的应⽤创建⼀个消费组,然后向消费组添加消费者来横向扩展消费能⼒和应⽤的处理能⼒,则每个消费者只处理⼀部分消息。
1.2 心跳机制
初始的消费者消费分区:

消费者宕机,退出消费组,触发再平衡,重新给消费组中的消费者分配分区

由于broker宕机,主题X的分区3宕机,此时分区3没有Leader副本,触发再平衡,消费者4没有对应的主题分区,则消费者4闲置

Kafka 的⼼跳是 Kafka Consumer 和 Broker 之间的健康检查,只有当 Broker Coordinator 正常时,Consumer 才会发送⼼跳。
Consumer 和 Rebalance 相关的 2 个配置参数:

broker 端,sessionTimeoutMs 参数
broker 处理⼼跳的逻辑在 GroupCoordinator类中。如果⼼跳超期, broker coordinator 会把消费者从 group 中移除,并触发 rebalance。
可以看看源码的kafka.coordinator.group.GroupCoordinator#completeAndScheduleNextHeartbeatExpiration方法。
如果客户端发现⼼跳超期,客户端会标记 coordinator 为不可⽤,并阻塞⼼跳线程;如果超过了 poll 消息的间隔超过了 rebalanceTimeoutMs,则 consumer 告知 broker 主动离开消费组,也会触发 rebalance
可以看看源码的org.apache.kafka.clients.consumer.internals.AbstractCoordinator.HeartbeatThread 内部类
二、消息接收相关
2.1 常用参数配置

2.2 订阅
Topic:Kafka⽤于分类管理消息的逻辑单元,类似与MySQL的数据库。
*Partition:是Kafka下数据存储的基本单元,这个是物理上的概念。同⼀个topic的数据,会被分散的存储到多个partition中,这些partition可以在同⼀台机器上,也可以是在多台机器上。优势在于:有利于⽔平扩展,避免单台机器在磁盘空间和性能上的限制,同时可以通过复制来增加数据冗余性,提⾼容灾能⼒。为了做到均匀分布,通常partition的数量通常是Broker Server数量的整数倍。
Consumer Group:同样是逻辑上的概念,是Kafka实现单播和⼴播两种消息模型的⼿段**。保证⼀个消费组获取到特定主题的全部的消息。在消费组内部,若⼲个消费者消费主题分区的消息,消费组可以保证⼀个主题的每个分区只被消费组中的⼀个消费者消费。
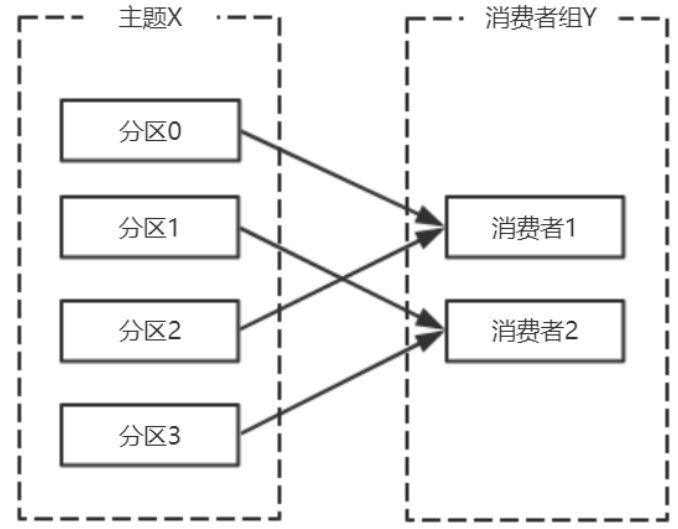
consumer 采⽤ pull 模式从 broker 中读取数据。
采⽤ pull 模式,consumer 可⾃主控制消费消息的速率, 可以⾃⼰控制消费⽅式(批量消费/逐条消费),还可以选择不同的提交⽅式从⽽实现不同的传输语义。
订阅主题:consumer.subscribe("tp_demo_01,tp_demo_02")
2.3 反序列化
2.3.1 Kafka 自带反序列化器
Kafka的broker中所有的消息都是字节数组,消费者获取到消息之后,需要先对消息进⾏反序列化处理,然后才能交给⽤户程序消费处理。
常用的Kafka提供的,反序列化器包括key的和value的反序列化器:
- key.deserializer:IntegerDeserializer
- value.deserializer:StringDeserializer
消费者从订阅的主题拉取消息:consumer.poll(3_000);
在Fetcher类中,对拉取到的消息⾸先进⾏反序列化处理:
private ConsumerRecord<K, V> parseRecord(TopicPartition partition, RecordBatch batch, Record record) {
try {
long offset = record.offset();
long timestamp = record.timestamp();
Optional<Integer> leaderEpoch = this.maybeLeaderEpoch(batch.partitionLeaderEpoch());
TimestampType timestampType = batch.timestampType();
Headers headers = new RecordHeaders(record.headers());
ByteBuffer keyBytes = record.key();
byte[] keyByteArray = keyBytes == null ? null : Utils.toArray(keyBytes);
K key = keyBytes == null ? null : this.keyDeserializer.deserialize(partition.topic(), headers, keyByteArray);
ByteBuffer valueBytes = record.value();
byte[] valueByteArray = valueBytes == null ? null : Utils.toArray(valueBytes);
V value = valueBytes == null ? null : this.valueDeserializer.deserialize(partition.topic(), headers, valueByteArray);
return new ConsumerRecord(partition.topic(), partition.partition(), offset, timestamp, timestampType, record.checksumOrNull(),  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3290
3290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









