







前言
说实话,在写这一篇文章之前我一直没有搞懂一个问题。明明我们项目中使用最多的缓存技术就是Redis,用Redis就完全就可以搞定缓存的问题了,为什么还有一个SpringCache,以及SpringCache和Redis之间的区别。
一、 为什么要使用缓存
- 缓存是将数据直接存入内容中,读取效率比数据库的更高
- 缓存可以有效地降低数据库压力,为数据库减轻负担
二、 常见的缓存中间件
Redis、Memcached、Guava、Caffeine,其中Redis和Memcached使用的较多,各自也有不同的优缺点,可参考博客:https://blog.csdn.net/galen2016/article/details/81673870
三、 为什么要使用SpringCache
先看一下我们使用缓存步骤:
- 查寻缓存中是否存在数据,如果存在则直接返回结果
- 如果不存在则查询数据库,查询出结果后将结果存入缓存并返回结果
- 数据更新时,先更新数据库
- 然后更新缓存,或者直接删除缓存
此时我们会发现一个问题,所有我们需要使用缓存的地方都必须按照这个步骤去书写,这样就会出现很多逻辑上相似的代码。并且我们程序里面也需要显示的去调用第三方的缓存中间件的API,如此一来就大大的增加了我们项目和第三方中间件的耦合度。就以Redis为列,如下图所示:
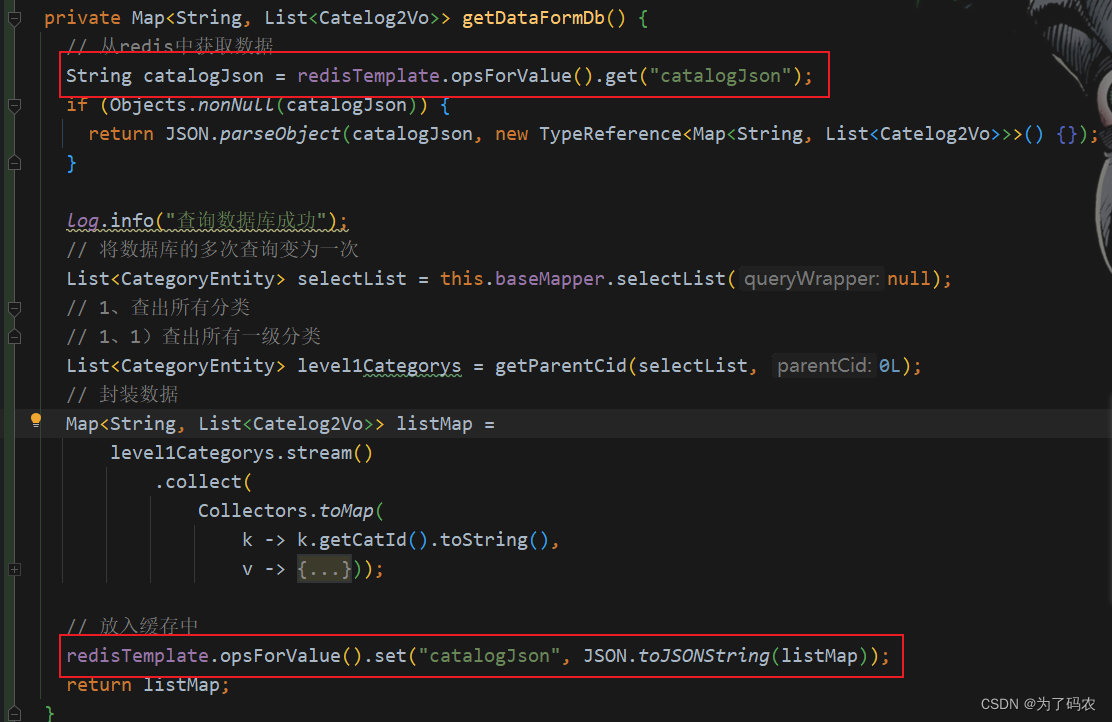
图中代码所示,就是我们上面描述的使用Redis作为缓存中间件来进行缓存的实列,我们不难发现,我们的查询和存储时都是使用到了SpringBoot整合Redis后的相关API的,并且项目中所有的使用缓存的地方都会如此使用,这样子提升了代码的复杂度,我们程序员更应该关注的是业务代码,因此我们需要将查询缓存和存入缓存这类似的代码封装起来用框架来替我们实现,让我们更好的去处理业务逻辑。
那么我们如何让框架去帮我们自动处理呢,这不就是典型的AOP思想吗?
是的,Spring Cache就是一个这样的框架。它利用了AOP,实现了基于注解的缓存功能,并且进行了合理的抽象,业务代码不用关心底层是使用了什么缓存框架,只需要简单地加一个注解,就能实现缓存功能了。而且Spring Cache也提供了很多默认的配置,用户可以3秒钟就使用上一个很不错的缓存功能。
使用了Spring Cache框架后使用缓存实列,如下图所示:
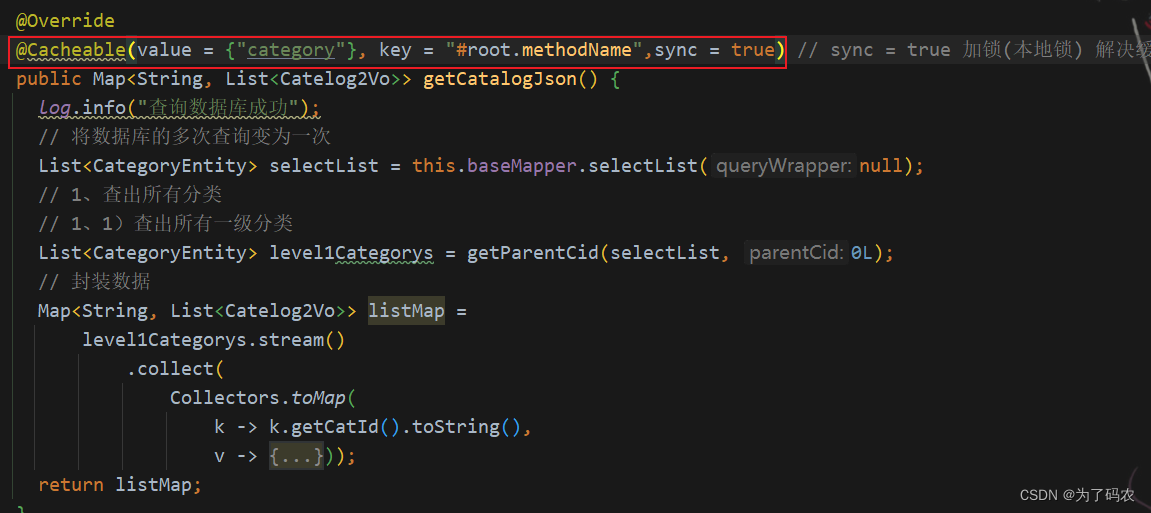
我们只需要将我们的方法添加一个注解就可以将方法返回结果直接存入缓存,并不需要手动去进行设置,是不是大大的简化了代码。
三、 SpringBoot整合Redis
1.导入jar包
<!--redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2.添加配置文件(直接复制得话,检查下格式哟)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2040
2040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









