







OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,它提供了很多函数,这些函数非常高效地实现了计算机视觉算法(最基本的滤波到高级的物体检测皆有涵盖)。
OpenCV 使用 C/C++ 开发,同时也提供了 Python、Java、MATLAB 等其他语言的接口。
OpenCV 是跨平台的,可以在Windows、Linux、Mac OS、Android、iOS 等操作系统上运行。
OpenCV 的应用领域非常广泛,包括图像拼接、图像降噪、产品质检、人机交互、人脸识别、动作识别、动作跟踪、无人驾驶等。
OpenCV 还提供了机器学习模块,你可以使用正态贝叶斯、K最近邻、支持向量机、决策树、随机森林、人工神经网络等机器学习算法。
OpenCV是一个开源的计算机视觉库,可以从http://opencv.org获取。
1999 年,Gary Bradski(加里·布拉德斯基)当时在英特尔任职,怀着通过为计算机视觉和人工智能的从业者提供稳定的基础架构并以此来推动产业发展的美好愿景,他启动了 OpenCV 项目。
OpenCV 库用C语言和C++语言编写,可以在 Windows、Linux、Mac OS X 等系统运行。同时也在积极开发Python、Java、Matlab 以及其他一些语言的接口,将库导入安卓和 iOS 中为移动设备开发应用。
OpenCV 自项目成立以来获得了来自英特尔和谷歌的大力支持,尤其需要感谢 Itseez,该公司完成了早期开发的大部分工作。此后,Arraiy 团队加入该项目并负责维护始终开源和免费的 OpenCV.org。
Itseez 是俄罗斯的一家视觉公司,专门从事计算机视觉算法。2016 年 5 月,英特尔收购该公司,以“帮助英特尔的用户打造创新型深度学习的 CV 应用,如果自动驾驶、数字安全监控和工业检测”(英特尔物联网总经理 Doug Dacies 如此说)。
OpenCV 设计用于进行高效的计算,十分强调实时应用的开发。它由 C++ 语言编写并进行了深度优化,从而可以享受多线程处理的优势。
OpenCV 的一个目标是提供易于使用的计算机视觉接口,从而帮助人们快速建立精巧的视觉应用。
OpenCV 库包含从计算机视觉各个领域衍生出来的 500 多个函数,包括工业产品质量检验、医学图像处理、安保领域、交互操作、相机校正、双目视觉以及机器人学。
因为计算机视觉和机器学习经常在一起使用,所以 OpenCV 也包含一个完备的、具有通用性的机器学习库(ML模块)。这个子库聚焦于统计模式识别以及聚类。ML 模块对 OpenCV 的核心任务(计算机视觉)相当有用,但是这个库也足够通用,可以用于任意机器学习问题。
IPPICV 加速
如果希望得到更多在英特尔架构上的自动优化,可以购买英特尔的集成性能基元(IPP)库,该库包含了许多算法领域的底层优化程序。在库安装完毕的情况下 OpenCV 在运行的时候会自动调用合适的 IPP 库。
从 OpenCV 3.0 开始,英特尔许可 OpenCV 研发团队和 OpenCV 社区拥有一个免费的 IPP 库的子库(称 IPPICV),该子库默认集成在 OpenCV 中并在运算时发挥效用。
如果你使用的是英特尔的处理器,那么 OpenCV 会自动调用 IPPICV。
IPPICV 可以在编译阶段链接到 OpenCV,这样一来,会替代相应的低级优化的C语言代码(在 cmake 中设置WITH_IPP=ON/OFF来开启或者关闭这一功能,默认情况为开启)。使用 IPP 获得的速度提升非常可观。
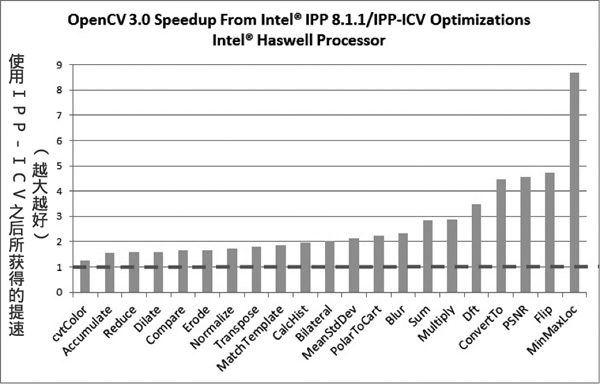
图:当 OpenCV 在 Intel Haswell 处理器上使用 IPPICV 时的加速效果
给大家推荐一个国内OpenCV讲得最好的教程。
许多计算机科学家和经验丰富的程序员多多少少都了解计算机视觉的某些方面,但是很少有人熟谙计算机视觉的每一个应用。比如:
- 很多人了解计算机视觉在安保行业的应用;
- 一些人也知道它在网页端的图像和视频处理中的应用在逐渐增加。
但很少有人知道计算机视觉在游戏交互中的应用。同时,也很少有人认识到大部分航空图像和街景图像(比如说谷歌街景)已经大量应用相机校正和图像拼接技术。
有一些人略微知道一点视觉在自动监控、无人机或者生物制药分析上的应用,但很少有人知道计算机视觉早已经在制造业普遍使用。事实上,批量制造的所有东西都已经利用计算机视觉在进行某些方面的质检工作了。
自从测试版本在 1999 年 1 月发布以来,OpenCV 已经广泛用于许多应用、产品以及科研工作中。这些应用包括在卫星和网络地图上拼接图像,图像扫描校准,医学图像的降噪,目标分析,安保以及工业检测系统,自动驾驶和安全系统,制造感知系统,相机校正,军事应用,无人空中、地面、水下航行器。
它也被运用于声音和音乐的识别,在这些场景中,视觉识别方法被运用于声音的频谱图像。
OpenCV 亦是斯坦福大学的机器人斯坦利至关重要的一部分,这个机器人赢得了美国国防部高级研究计划署主持的 DARPA 机器人挑战赛野外机器人竞速的 200 万美元大奖。
DARPPA 机器人挑战赛(DRC)是机器人领域的一项重大赛事,堪称“机器人的奥林匹克”。
OpenCV 使用开源许可证
OpenCV 的开源许可允许任何人利用 OpenCV 包含的任何组件构建商业产品。你也没有义务开源自己的产品或者对该产品所涉及领域进行反馈和改进,虽然我们希望你这样做。
在这种自由许可的影响下,项目有着极其庞大的用户社区,社区用户包括一些来自大公司的员工(IBM、微软、英特尔、索尼、西门子和谷歌等)以及一些研究机构(例如斯坦福大学、麻省理工学院、卡内基梅隆大学、剑桥大学以及法国国家信息与自动化研究所)。
此外,OpenCV 项目还有一个雅虎论坛组为用户提供提问和讨论的地方,该论坛组有超过 50 000 名成员。
OpenCV 在世界范围内都非常流行,尤其是在中国、日本、俄罗斯、欧洲和以色列有着庞大的用户社区。
计算机视觉这种技术可以将静止图像或视频数据转换为一种决策或新的表示。所有这样的转换都是为了完成某种特定的目的而进行的。
输入数据可能包含一些场景信息,例如“相机是搭载在一辆车上的”或者“雷达发现了一米之外有一个目标”。一个新的表示,意思是将彩色图像转换为黑白图像,或者从一个图像序列中消除相机运动所产生的影响。
人类的视觉
因为我们是被赋予了视觉的生物,所以很容易误认为“计算机视觉也是一种很简单的任务”。计算机视觉究竟有多困难呢?
请说说你是如何从一张图像中观察到一辆车的。你最开始的直觉可能具有很强的误导性。人类的大脑将视觉信号划分为许多通道,好让不同的信息流输入大脑。大脑已经被证明有一套注意力系统,在基于任务的方式上,通过图像的重要部分检验其他区域的估计。在视觉信息流中存在巨量的信息反馈,并且到现在我们对此过程也知之甚少。
肌肉控制的感知器和其他所有感官都存在着广泛的相互联系,这让大脑能够利用人在世界上多年生活经验所产生的交叉联想,大脑中的反馈循环将反馈传递到每一个处理过程,包括人体的感知器官(眼睛),通过虹膜从物理上控制光线的量来调节视网膜对物体表面的感知。
计算机的视觉
然而在机器视觉系统中,计算机会从相机或者硬盘接收栅格状排列的数字,也就是说,最关键的是,机器视觉系统不存在一个预先建立的模式识别机制。没有自动控制焦距和光圈,也不能将多年的经验联系在一起。大部分的视觉系统都还处于一个非常朴素原始的阶段。
图 1 展示了一辆汽车。在这张图片中,我们看到后视镜位于驾驶室旁边。但是对于计算机而言,看到的只是按照栅格状排列的数字。所有在栅格中给出的数字还有大量的噪声,所以每个数字只能给我们提供少量的信息,但是这个数字栅格就是计算机所能够“看见”的全部了。我们的任务变成将这个带有噪声的数字栅格转换为感知结果“后视镜”。
图 2 给出了为什么计算机视觉如此困难的另一些解释。
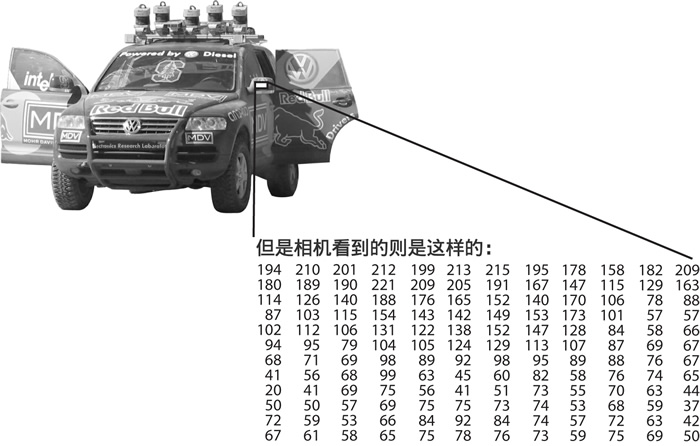
图1:对于计算机来说,汽车的后视镜就是一组栅格状排列的数字
图2:视觉的不适定问题,物体的二维表示可能随着视点的不同完全改变
一个数学物理定解问题的解如果存在,唯一并且稳定的,则说明该问题是适定的(well-posed);如果不满足,则说明该问题是不适定的(ill-posed)。
实际上,这一问题,正如我们之前所提出的,用“困难”已经不足以形容它了,它在很多情况下根本不可能解决。
给定一个对于 3D 世界的二维(2D)观测,就不存在一个唯一的方式来重建三维信号。即使数据是完美的,相同的二维图像也可能表示一个无限的 3D 场景组合中的任一种情况。
而且,前面也提到过,数据会被噪声和畸变所污染。这样的污染源于现实生活中的很多方面(天气、光线、折射率和运动),还有传感器中的电路噪声以及其他的一些电路系统影响,还有在采集之后对于图像压缩产生的影响。
在这一系列的影响之下,我们又该如何推动事情的进展呢?
在经典的系统设计中,额外场景信息可以帮助我们从传感器的层面改善获取信息的质量。
场景信息可以辅助计算机视觉
考虑这样一个例子,一个移动机器人需要在一栋建筑中找到并且拿起一个订书机。机器人就可能用到这样的事实:桌子通常放在办公室里,而订书机通常收纳在桌子里。这也同样给出了一个关于尺寸的推断:订书机的大小一定可以被桌子所收纳。
更进一步,这还可以帮助减少在订书机不可能出现的地方错误识别订书机的概率(比如天花板或者窗口)。机器人可以安全忽略掉 200 英尺高的订书机形状的飞艇,因为飞艇没有满足被放置在木制桌面上的先验信息。
相对的,在诸如图像检索等任务中,数据集中所有的订书机图像都是来自真实的订书机,这样不合常理的尺寸以及一些奇形怪状的造型都会在我们进行图片采集的时候隐式消除——因为摄影师只会去拍摄普通的正常尺寸的订书机。人们同样倾向于在拍摄的时候将拍摄目标放在图片的中间,并且倾向于在最能够展现目标特征的角度拍摄。因此,通常也有很多无意的附加信息在人们拍摄照片的时候无意加进去。
场景信息同样可以(尤其是通过机器学习技术)进行建模。隐式的变量(比如尺寸、重力的方向等不容易被直接观测到的)可以从带标记的数据集中发现关系并推测出来。或者,可以尝试使用附加的传感器测量隐式变量的值,比如利用激光雷达来测量深度,从而准确得到目标的尺寸。
使用统计的方法来对抗噪声
计算机视觉所面临的下一个问题是噪声,我们一般使用统计的方法来对抗噪声。
比如,我们很难通过单独的像素点和它的相邻像素点判断其是否是一个边缘点,但如果观察它在一个区域的统计规律,边缘检测就会变得更加简单了。
一个真正的边缘应该表现为一个区域内一连串独立的点,所有点的朝向都与其最接近的点保持一致。我们也可以通过时间上的累计统计对噪声进行抑制,当然也有通过现有数据建立噪声模型来消除噪声的方法。例如,因为透镜畸变很容易建模,我们只需要学习一个简单的多项式模型来描述畸变就可以几乎完美矫正失真图像。
基于摄像机的数据,计算机视觉准备做出的动作或决定是在特定的目的或者任务的场景环境中执行的。我们也许想要移除噪声或者修复被损坏的照片,这样安全系统就可以对试图爬上栏杆等危险行为发出警报,或者对于穿过某个游乐场区域的人数进行统计。
而在大楼中漫游的机器人的视觉软件将会采取和安全系统完全不同的策略,因为两种策略处于不同的语境中。一般来说,视觉系统所处的环境约束越严格,我们就越能够依赖这些约束来简化问题,我们最终的解决方案也越可靠。
OpenCV的目标是为计算机视觉需要解决的问题提供工具。在某些情况下,函数库中的高级功能可以有效解决计算机视觉中的问题。即使遇到不能够一次性解决的问题,函数库中的基础组件也具有足够的完备性来增强解决方案的性能,以应对任意的计算机视觉难题。
在后一种情况下,也存在一些使用库的可靠方法,所有的这些方法都是从尽量多使用不同的组件库开始。通常,在开发了第一个粗糙的解决方案之后,就可以发现解决方案存在哪些缺陷并且使用自己的代码与聪明才智修复那些缺陷(更为熟知的说法是“解决真正存在的问题,而不是你想象中的那些问题”)。在此之后可以使用粗糙的解决方案作为一个评判标准,评价改善水平。从这一点出发,你可以解决任意问题。
OpenCV缘起于英特尔想要增强 CP
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









