






目录
!!!本文思路、代码均参考于[代码大多参考于此文章]!!!
!!!本文思路、代码均参考于[代码大多参考于此文章]!!!:https://labuladong.online/algo/essential-technique/backtrack-framework-2/#%E4%B8%80%E3%80%81%E5%85%A8%E6%8E%92%E5%88%97%E9%97%AE%E9%A2%98
引入
- 看了一些DFS和BFS的文章 , 我对这两个搜索算法的理解又深了一些
- 我之前一直搞不明白一个问题 : 什么时候用DFS? 什么时候用BFS?
先对二叉树的dfs和bfs来分析一波:
-
二叉树的dfs(深度优先遍历) 顾名思义就是竖着遍历 , 直到遍历到叶子节点(第一次遍历到的叶子节点一定是左下的那个) , 然后开始往回走
所以dfs 最大的特点就是–>要遍历完所有可能的路径—>再去寻找答案 -
而bfs(广度优先遍历)呢? 那也就是横着遍历了呗—>bfs一般用队列实现,将同一层的节点都装进队列中
因而,bfs在寻找最短路径时,比dfs好用点(当然,只是某些情况下好用.毕竟bfs要占用的空间太多了 . 二叉树每层又是呈指数型增加,那不kuku网上增,得用多少空间啊) 为什么是某些情况好用的-->你想啊,一个差不多的二叉树,找他的最短路径 bfs咋找?-->一层层找 , 比如第一个叶子节点在第三层--->那bfs找到第三层之后就不用再找了 dfs呢?--->找出所有的路径 , 再比较一下谁最短.
综上啊
-
dfs啥时候用呢?---->要找所有可能情况的时候
-
bfs呢—>最短路径
当然,这里最短路径可能包括 : - 走迷宫,有的格子是围墙不能走,从起点到终点的最短距离是多少? 如果这个迷宫带[传送门]可以瞬间传送呢? - 比如果两个单词,要求你通过某些替换,把其中一个变成另一个,每次只能替换一个字符,最少要替换几次? - 再比如 连连看游戏,两个方块消除的条件不仅仅是图案相同,还得保证两个方块之间的最短连线不能多与两个拐点 . 玩连连看时,点击两个坐标,如何判断它俩的最短线之间有几个拐点的? [当然,以上都是一幅图,让你从一个起点,走到终点,问最短路径.]
以下附上某AI的回答:
通常情况下,可以根据以下几点考虑何时使用深度优先搜索(DFS)和广度优先搜索(BFS)算法:
- 使用DFS:
1. 当问题需要遍历所有可能的路径或状态时,可以使用DFS。
2. 当问题的解可能在深层次的状态中,且不需要最短路径时,DFS是一个不错的选择。
3. 当问题涉及到图的遍历、连通性检测、拓扑排序等情况时,DFS通常是一个简单且有效的选择。
- 使用BFS:
1. 当问题需要在最短路径上找到解时,可以使用BFS。
2. 当问题需要按层级遍历或搜索时,BFS是一个很好的选择。
3. 当问题需要找到最短路径、最短距离或最短步数时,BFS通常是更好的选择。
总的来说,DFS适用于深度优先搜索、递归问题和状态空间搜索,而BFS适用于广度优先搜索、最短路径问题和层级遍历。根据问题的特点和需求,选择合适的搜索算法可以提高算法效率和解决问题的准确性。
回溯算法和dfs的区别
回溯算法和dfs算法极为相似,本质上就是一种暴力穷举算法。
区别就是:回溯算法是在遍历【树枝】,dfs算法是在遍历【节点】
(其实没啥区别)
回溯算法(DFS)
站在回溯树的节点上,你只需要思考3个问题 :
- 路径 : 也就是已经做出的选择
- 选择列表 : 也就是你当前可以做的选择
- 结束条件 : 也就是到达决策树底层,无法再做选择的条件
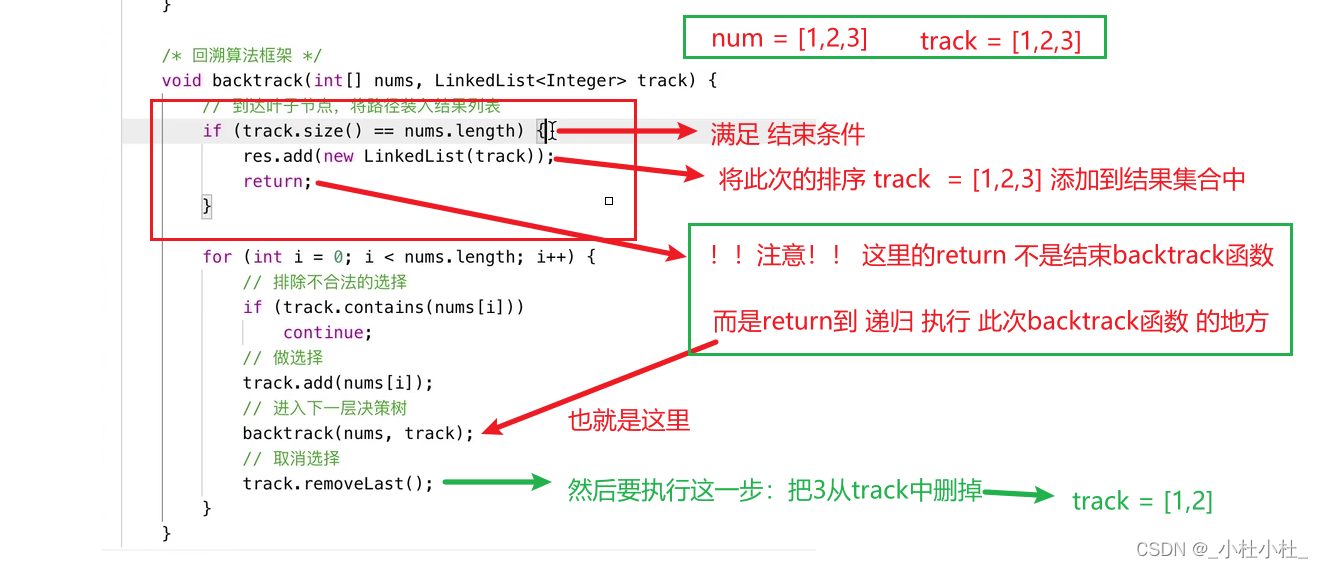
1.基本框架
result = []
def backtrack(路径,选择列表):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(路径,选择列表)
撤销选择
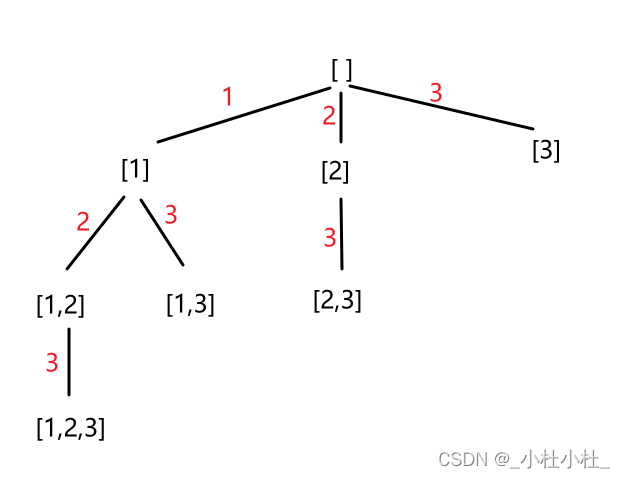
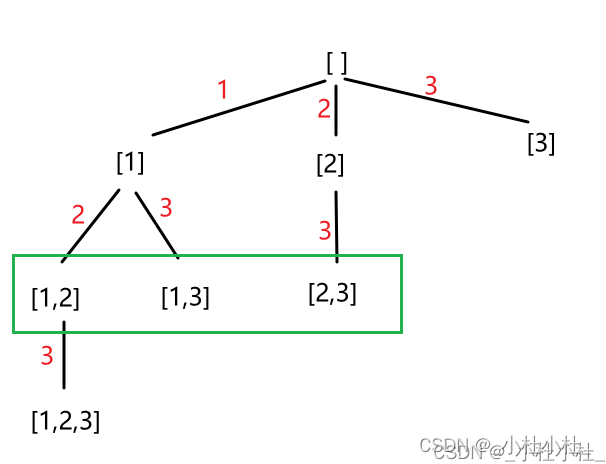
2.例题:【1,2,3】的全排列
- 如图,1,2,3的全排列我们可以用一个树来表示(回溯算法是记录路径!!)
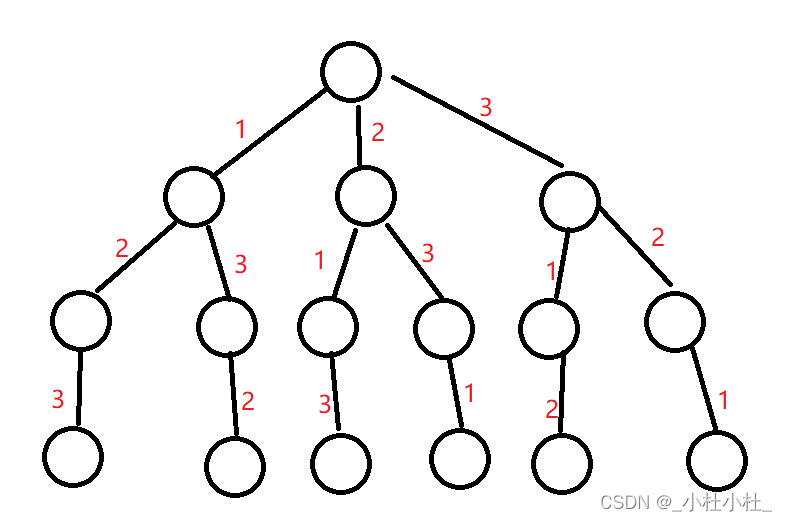
- 大致思想是这样的(先拿出来一支杈 分析分析)
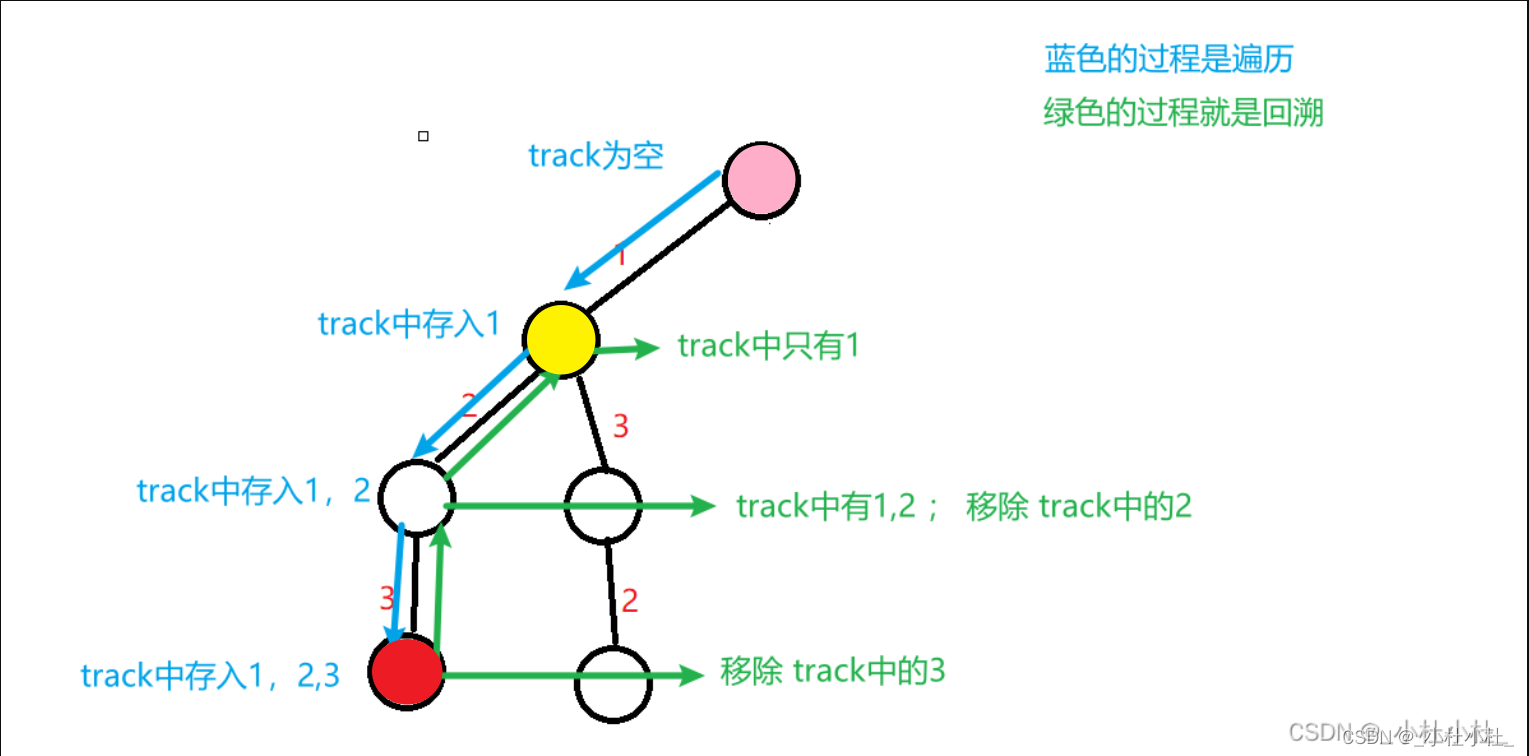
再重复一遍
- 站在一个回溯树的节点上,只需要思考3个问题:
1.路径:也就是已经做出的选择(往后看看)
2.选择列表:也就是当前可以做的选择(往前看看)
3.结束条件:到达决策树底层,无法再做选择的条件(看看自己啥时候over)
-
只针对上面有色儿的那一支杈
- 对于上面的“粉色”节点: 路径:没有 选择列表:【1】 结束条件:遍历到叶子节点 - 对于上面的“黄色”节点: 路径:【1】 选择列表:【2,3】 结束条件:遍历到叶子节点 - “红色”: 路径:【1,2,3】 选择列表:没有 结束条件:到达结束条件
3.代码详解
- 基本思想完事了,我们来仔细分析下代码

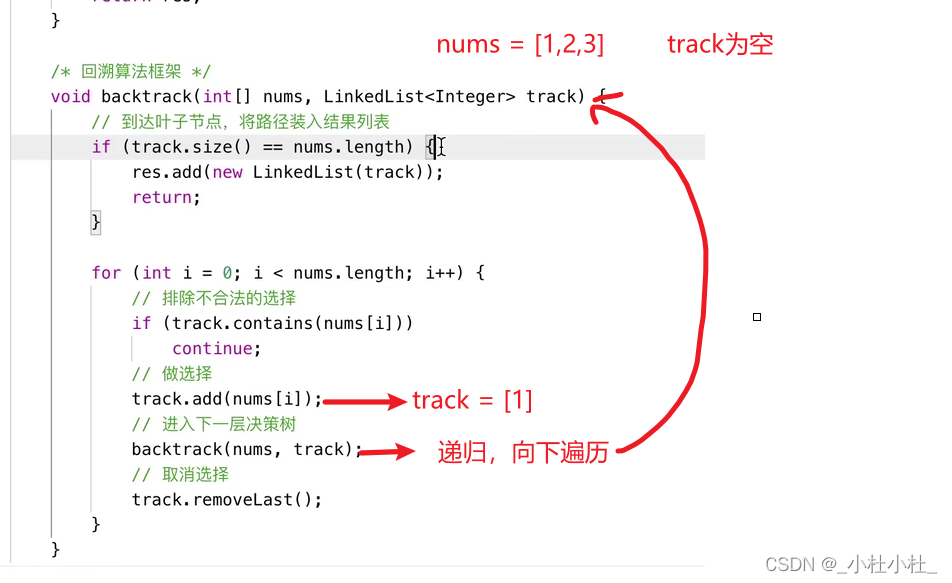
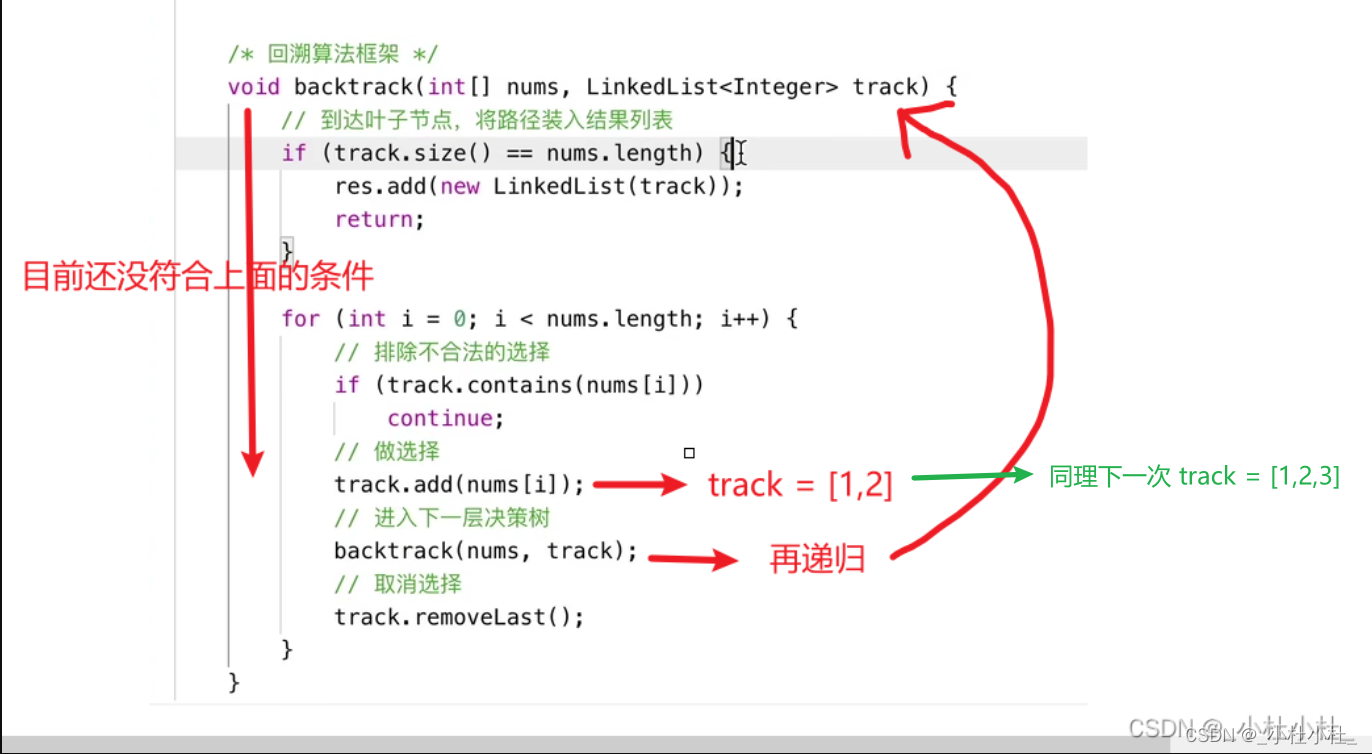
4.完整代码
import java.util.LinkedList;
import java.util.List;
//import com.sun.xml.internal.bind.v2.schemagen.xmlschema.List;
public class Main{
static LinkedList<List<Integer>> list = new LinkedList<>();
public static void main(String[] args) {
int[] nums = {1,2,3};
System.out.println(permute(nums));
}
//输入一组不重复的数字,返回他们的全排列
static List<List<Integer>> permute(int[] nums){
//记录[路径]
LinkedList<Integer> track = new LinkedList<>();
// [路径] 中的元素会被标记为true,避免重复使用
boolean[] used = new boolean[nums.length];
backtrack(nums,track,used);
return list;
}
// 路径:记录在track中
//选择列表:nums中不存在于track的那些元素(used[i] 为false)
//结束条件:nums中的元素全都在track中出现
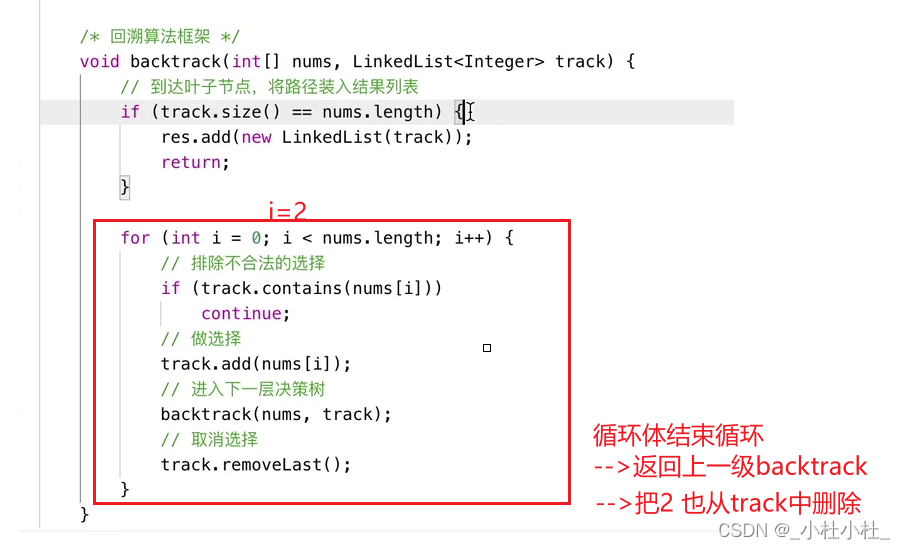
static void backtrack(int[] nums, LinkedList<Integer> track, boolean[] used) {
//结束条件
if(track.size() == nums.length) {
list.add(new LinkedList(track));
return; //返回上一级backtrack
}
for(int i=0;i<nums.length;i++) {
//排除不合法的选择
if(used[i]) {
//nums[i]已经在track中,跳过
continue;
}
//做选择
track.add(nums[i]);
used[i] = true;
//进入下一层决策树
backtrack(nums, track, used);
//取消选择
track.removeLast();
used[i] = false;
}
//return; //返回上一级的backtrack(不加也行,循环结束,自动返回上一级backtrack)
}
}
经典dfs(回溯)解法----排列/组合/子集问题
解这些题的时候还是可以把他们看做一棵树
1.计算所有子集
还是遍历一棵树 , 树棍上标着要遍历的下一个nums中的元素 , 每个节点就是组合出来的子集 . 而我们可以轻易发现 , 每层组合出来的子集,由相同元素个数组成 且元素个数等于层数
0层 0个元素组成
1层 1个元素组成
2层 2个元素组成
3层 3个元素组成
由此 , 我们把这棵树的节点都遍历出来 , 不就是[1,2,3]的所有子集了吗
框架
class Soluction{
List<List<Integer>> res = new LinkedList<>();//存放所有子集
LinkedList<Integer> track = new LinkedList<>(); //记录回溯算法的递归路径
//主函数
public List<List<Integer>> subsets(int[] nums){
backtrack(nums,0);
return res;
}
//回溯算法核心函数,遍历子集问题的回溯树
void backtrack(int[] nums,int start){ //start是用来去重的(只要每次索引从start开始,那么,start前的元素就不会再被使用了)
//前序位置,每个节点的值都是一个子集
res.add(new LinkedList<>(track));
//回溯算法标准框架
for(int i = start; i < nums.length; i++){
//做选择
track.addLast(nums[i]);
//通过 start 参数控制树枝的遍历,避免产生重复的子集
backtrack(nums,i+1);
//撤销选择
track.removeLast();
}
}
}
完整代码
import java.util.LinkedList;
import java.util.List;
public class Main{
static List<List<Integer>> res = new LinkedList(); //用来存放结果集
static int[] nums = {1,2,3};
static List<Integer> track = new LinkedList<Integer>(); //用来记录路径(并进行添加和回溯)
public static void main(String[] args) {
dfs(nums, 0);
System.out.println(res); //output:[[], [1], [1, 2], [1, 2, 3], [1, 3], [2], [2, 3], [3]]
}
//回溯算法
public static void dfs(int[] nums,int start) {
res.add(new LinkedList<Integer>(track));
//回溯经典框架
for(int i=start;i<nums.length;i++) {
//选择
track.add(nums[i]);
//递归
dfs(nums, i+1);
//撤销选择
track.remove(track.size()-1);
}
}
}
2.组合
子集完事了 , 那现在想想 , 如果让你输出nums = [1,2,3] 中拿2个元素形成的所有组合 , 怎么做?
- 那不就是输出树的第2层吗
例题 : 给定两个整数n和k,返回方位[1,n]中所有可能的k个数的组合.
- 那不就是输出这一层吗 .
- 框架
class Soluction{
static List<List<Integer>> res = new LinkedList();
static List<Integer> track = new LinkedList();
//主函数
public List<List<Integer>> combine(int n, int k){
backtrack(1,n,k);
return res;
}
//回溯函数
void backtrack(int start,int n,int k){
if(k == track.size()){
res.add(new LinkedList<>(track));
return;
}
for(int i=start;i<=n;i++){
//选择
track.addLast(i);
//递归
backtrack(i+1,n,k);
//撤销选择
track.removeLast();
}
}
}
- 完整代码
import java.util.LinkedList;
import java.util.List;
public class Main{
static List<List<Integer>> res = new LinkedList(); //用来存放结果集
// static int[] nums = {1,2,3};
static List<Integer> track = new LinkedList<Integer>(); //用来记录路径(并进行添加和回溯)
public static void main(String[] args) {
dfs(1,3,2); //1到3,输出两个元素的所有组合
System.out.println(res);
}
//回溯算法
public static void dfs(int start,int n,int k) {
if(track.size() == k) {
res.add(new LinkedList<Integer>(track));
return;
}
for(int i=start; i<=n;i++) {
//选择
track.add(i);
//递归
dfs(i+1, n, k);
//撤销选择
track.remove(track.size()-1); //remove(索引)
}
}
}
岛屿问题
二维矩阵遍历框架
- 可以正常遍历
void dfs(int[][] grid,int i,int j,boolean[][] visited) {
int m = grid.length;
int n = grid[0].length;
if(i<0 || j<0 || i>=m || j>=n) {
//超出索引边界
return;
}
if(visited[i][j]) {
//该点已经遍历过
return;
}
//进入节点(i,j)
visited[i][j] = true;
dfs(grid, i-1, j, visited);//上
dfs(grid, i+1, j, visited);//下
dfs(grid, i, j-1, visited);//左
dfs(grid, i, j+1, visited);//右
}
- 也可以使用方向数组遍历
static int[][] dirs = new int[][] {{-1,0},{1,0},{0,-1},{0,1}};//上,下,左,右(方向数组)
public static void dfs(int[][] grid,int i,int j,boolean[][] visited) {
int m = grid.length;
int n = grid[0].length;
if(i<0 || j<0 || i>=m || j>=n) {
//超出索引边界
return;
}
if(visited[i][j]) {
//该点已经遍历过
return;
}
//进入节点(i,j)
visited[i][j] = true;
//递归遍历上下左右的节点
for(int[] d : dirs) {
int next_i = i + d[0];
int next_j = j + d[1];
dfs(grid, next_i, next_j, visited);
}
}
例题:岛屿数量
- 代码实现
class Solution{
//主函数,计算岛屿的数量
int numIslands(char[][] grid) {
int res = 0;
int m = grid.length; //行数
int n = grid[0].length; //列数
//遍历grid
for(int i=0;i<m;i++) {
for(int j=0;j<n;j++) {
if(grid[i][j] == '1') {
//每发现一个岛屿 , 岛屿数加一
res++;
//然后使用dfs把与他相邻的岛屿都淹了
dfs(grid,i,j);
}
}
}
return res;
}
//从(i,j)开始,将与之相邻的陆地都变成海水
void dfs(char[][] grid,int i,int j) {
int m = grid.length;
int n = grid[0].length;
//超出边界
if(i < 0 || j < 0 || i >= m || j >= n) {
return;
}
//该点已经是海水了
if(grid[i][j] == '0') {
return;
}
//将(i,j)变成海水
grid[i][j] = '0';
//淹没该点旁边的陆地
dfs(grid, i-1, j);
dfs(grid, i+1, j);
dfs(grid, i, j-1);
dfs(grid, i, j+1);
}
}
例题:岛屿的最大面积
class Solution {
int maxAreaOfIsland(int[][] grid) {
int m = grid.length;
int n = grid[0].length;
int res = 0;
//遍历岛屿
for(int i=0;i<m;i++) {
for(int j=0;j<n;j++) {
if(grid[i][j] == 1) {
res = Math.max(res,dfs(grid,i,j));
}
}
}
}
//淹没(i,j)相邻的陆地 , 并返回淹没的陆地面积
int dfs(int[][] grid,int i,int j) {
int res = 0;
int m = grid.length;
int n = grid[0].length;
if(i<0 || j<0 || i>=m || j>=n) return 0;
if(grid[i][j] == 0) return 0;
//将(i,j)变为海水
grid[i][j] = 0;
//计算周围岛屿数量
return dfs(grid, i+1, j)
+dfs(grid, i-1, j)
+dfs(grid, i, j+1)
+dfs(grid, i, j-1)+1;
}
}
BFS
- BFS算法 都是用 队
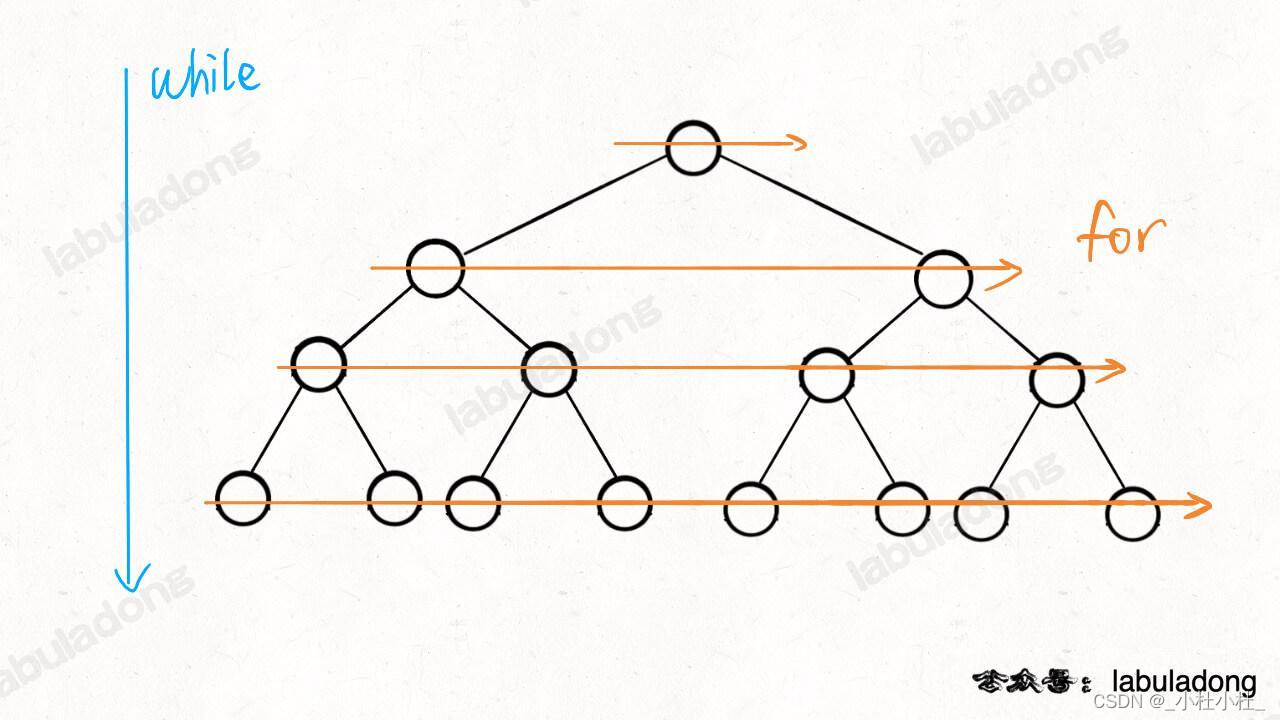
在这里插入代码片列 这种数据结构,每一次将一个节点周围的所有节点加入队列- BFS 和 DFS 最主要的区别是 : BFS找到的路径一定是最短的(但代价就是空间复杂度可能比DFS大很多)
代码框架
//伪码
//计算从起点start 到终点target的最短距离
int bfs(Node start,Node target){
Queue<Node> q; //核心数据结构
Set<Node> visited; //避免走回头路
q.offer(start); //将起点加入队列
visited.add(start);
while(q not empty){
int sz = q.size();
//将 当前队列中的所有节点啊向四周扩散
for(int i = 0;i < sz; i++){
Node cur = q.poll; //取队头元素
//判断是否达到终点
if(cur is target)
return step;
//将 cur 的相邻节点加入队列
for(Node x : cur.adj()){ //cur.adj()表示与cur相邻的节点
if(x not in visited){
q.offer(x);
visited.add(x);
}
}
}
}
//如果走到了这里,说明在图中没有找到目标节点
}
练习----二叉树的最小深度
- 二叉树的最小深度 给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明:叶子节点是指没有子节点的节点。
示例 1:
输入:root = [3,9,20,null,null,15,7]
输出:2示例 2:
输入:root = [2,null,3,null,4,null,5,null,6]
输出:5提示: 树中节点数的范围在 [0, 105] 内
-1000 <= Node.val <= 1000

思路:
首先明确起点start 和 终点target是什么?怎么判断到达了终点(也就是结束条件)?
—>显然 , 起点就是 root 根节点 , 终点就是最靠近根节点的那个叶子节点 叶子节点就是两个子节点都是null的节点
if(cur.left == null && cur.rigth == null)
//到达了叶子节点
- 核心代码
//给定一颗树的根节点,求这棵树的最小深度
int minDepth(TreeNode root){
if(root == null) return 0;
Queue<TreeNode> q = new LinkedList<>():
q.offer(root);
//root本身就是一层,depth初始化为1
int depth = 1;
while(!q.isEmpty){
int sz = q.size();
//将 当前队列中的所有节点向四周扩散
for(int i = 0; i < sz; i++){
TreeNode cur = q.poll();
//判断是否到达终点
if(cur.left == null && cur.right == null)
return depth;
//将cur的相邻节点加到队列中
if(cur.left != null)
q.offer(cur.left);
if(cur.rigth != null)
q.offer(cur.right);
}
//这里增加步数
depth++;
}
return depth;
}
- 完整代码
import java.util.LinkedList;
import java.util.Queue;
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}
public class Main {
public static void main(String[] args) {
// 创建一棵二叉树用于测试
TreeNode root = new TreeNode(1);
root.left = new TreeNode(2);
root.right = new TreeNode(3);
root.left.left = new TreeNode(4);
root.left.right = new TreeNode(5);
Main solution = new Main();
int minDepth = solution.minDepth(root);
System.out.println("Minimum depth of the binary tree: " + minDepth);
}
//bfs
//给定二叉树的头结点,输出这颗树的最小深度
public int minDepth(TreeNode root) {
if(root == null) return 0;
//bfs必用队列 可能会有一个集合visited来存储走过的路(避免走回头路)--->此题不用
Queue<TreeNode> q = new LinkedList<>();
q.offer(root); //先把根节点放进去
int depth = 1; //要算上根节点那一层
while(! q.isEmpty()) {
int sz = q.size(); //sz只是 二叉树 一层的节点个数--->所以,for完一层后,还会再while,再让sz = 下一层的节点个数
//将 当前队列中的所有节点向四周扩散
for(int i = 0;i < sz; i++) {
TreeNode cur = q.poll(); //每次都取队头元素
//找到叶子节点
if(cur.left == null && cur.right == null)
return depth;
//不是叶子节点,那就cur的子节点存入队列中
if(cur.left != null) q.offer(cur.left);
if(cur.right != null) q.offer(cur.right);
}
depth++;
}
return depth; //这里返回depth,其实是做了一个保险操作(因为在正常情况下,一个二叉树,不会没有叶子节点)
}
}
练习例子
import java.util.LinkedList;
import java.util.Queue;
import java.util.Scanner;
// 1:无需package
// 2: 类名必须Main, 不可修改
public class Main {
//bfs方法-->队列
//按照DLRU的方向找路径
static char[][] c = new char[30][50]; //输入题目迷宫
static int[][] visited = new int[30][50]; //判断每个坐标是否走过
static int[][] step = {{1,0},{0,-1},{0,1},{-1,0}}; //方向数组(DLRU)
static char[] direction = {'D','L','R','U'};
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
//在此输入您的代码...
for(int i=0;i<30;i++)
c[i] = scan.nextLine().toCharArray();
System.out.println(bfs());
scan.close();
}
//存储路径字母序的类
static class Node{
int x;
int y;
String str;
public Node(int x,int y,String str){
this.x = x;
this.y = y;
this.str = str;
}
}
public static String bfs(){
Queue<Node> q = new LinkedList();
q.offer(new Node(0, 0, ""));
visited[0][0] = 1;
String shunxv = ""; //存储到达每个节点的路径(字母序)
while(! q.isEmpty()){
int sz = q.size();
for(int i=0;i<sz;i++){
Node t = q.poll();
int x1 = t.x;
int y1 = t.y;
String str1 = t.str;
//结束条件
if(x1 == 29 && y1 == 49){
shunxv = str1;
break;
}
//队列中节点的子节点入队-->此题应按照字母序
for(int j=0;j<4;j++){
int x2 = x1 + step[j][0];
int y2 = y1 + step[j][1];
if(x2>=0 && x2<=29 && y2>=0 && y2<=49 && c[x2][y2] == '0'&& visited[x2][y2] == 0){
q.offer(new Node(x2,y2,str1+direction[j]));
visited[x2][y2] = 1;
}
}
}
}
return shunxv;
}
}
DFS(拓展,也不算拓展,只拓了,没展)
我在读这篇<回溯算法>的文章时 , 本以为他会讲回溯算法和dfs的区别 但是,文章后面说----其实回溯算法就是dfs…(无语啊啊啊啊)
- 总的来说,几乎没有区别
- 下面这个是我之前学过的一个dfs全排列的代码,一起来对比一下吧
详情看这篇文章,也算是看一看另一种理解方式吧
//也是[1,2,3]的全排列
import java.util.Scanner;
public class Main {
static int n;
static int[] a;
static boolean book[];
public static void main(String[] args) {
Scanner scanner=new Scanner(System.in);
n=scanner.nextInt();
a=new int[n+2];
book=new boolean[n+2];
dfs(1);
scanner.close();
}
public static void dfs(int k) {
// 回头条件
if(k==n+1){ //说明n个盒子都已经放完了
for(int i=1;i<=n;i++){
System.out.print(a[i]+" ");
}
System.out.println();
return; //这里的return是返回上一级dfs(可以理解为,方案一执行完了,还要进行方案二的排序)
}
// 放牌等操作
for(int i=1;i<=n;i++){ //进行1~n号牌的排序
if(book[i]==false){ //当这个盒子里没有牌时,可以进行以下操作
a[k]=i; //i号牌放入k号盒子中
book[i]=true; //标记盒子不为空
dfs(k+1); //带着手中的牌,走向下一个盒子
book[i]=false; //箱子置空。其实每次循环都执行到dfs(k++),只有当执行到没有路可走的时候,才会"回头";也就相当于例子中的,要从3号箱开始往回一个个收牌了
}
}
return;
}
}














 1198
1198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









