






 本文详细介绍了线性数据结构中的数组、链表、栈、队列以及树的特性,重点讲解了哈希表的工作原理,包括哈希函数、哈希值和解决哈希冲突的方法,如开放寻址法和拉链法。
本文详细介绍了线性数据结构中的数组、链表、栈、队列以及树的特性,重点讲解了哈希表的工作原理,包括哈希函数、哈希值和解决哈希冲突的方法,如开放寻址法和拉链法。
线性数据结构
1.数组
-
数组(Array) 是一种很常见的数据结构。由相同类型的元素组成,并且是使用一块连续的内存来存储的。
-
在数组中 我们可以直接利用元素的索引(index)计算出该元素对应的存储地址。
-
数组的特点是:随机访问,但容量有限
int[] arr = new int[n]; 访问:O(1)//访问特定元素 插入/删除:O(n)//插入到数组头,或删除数组头元素--》都需要将数组中所有元素进行移动操作
2.链表
-
有趣的理解(只是便于理解)
可以这么理解链表把链表看成一个家庭关系(只查单线哈),把链表中的数据看成家庭里的人。 有一天啊,来你家做人口调查 怎么查呢?按常理--》从最年长的开始,比如: 爷爷 爷爷的孩子--》爸爸 爸爸的孩子--》你 你--》null 这里,每个人,就相当于链表中的一个数据元素, 它包括了爷爷本身 和 从爷爷出发找爸爸的指针 同理,爸爸 也包括了它自身 和 指向你的指针 你没有孩子,所以指针为空 这就是,单链表 -
链表分类(常见)
- 单链表
- 双向链表
- 循环链表
- 双向循环链表
-
链表由一系列节点(链表中每一个元素成为节点)组成,节点在运行时动态生成,每个节点包括两个部分:
- 数据域:存储数据元素 - 指针域:存储下一个节点地址-
单链表

-
循环链表
尾节点不指向null,而是指向头结点

-
双向链表
包含两个指针,一个prev指向前一个节点,一个next指向后一个节点

-
-
双向循环

-
链表(LinkedList)
- 虽然是一种线性表,但它和数组不同,它不是顺序存储的,而是使用不连续的内存空间存储数据(链表的结点一般都有后继指针next–》指向后面的元素存储位置)。
- 因此,插入和删除操作:O(1);查找O(n);
- 这种结构可以克服数组需要预先知道数据大小的缺点,充分利用计算机的内存空间,实现灵活的内存动态管理。
- 同时,也因此 链表不具有数组的随机读取的特点(必须知道目标位置元素的上一个元素)
-
数组VS链表
- 数组可以随机访问,链表不可以随机访问
- 如果需要存储的数据元素的个数不确定,并且需要经常添加和删除数据的话,使用链表比较合适
- 如果需要存储的数据元素的个数确定,并且不需要经常添加和删除数据的话,使用数组比较合适
- 数组使用的是连续的内存空间,对CPU的缓存机制友好,链表则相反
- 数组大小固定,而链表天然支持动态扩容。如果声明的数组过小,需要另外申请一个更大的内存空间放数组元素,然后将原数组拷贝进去(这个操作是比较耗时的!)
3.栈(现java中一般用 双端队列 来实现栈)
栈(Stack)就像个无顶的盒子
只允许在有序的线性数据集合的一端(称为栈顶top)进行加入数据(push)和移除数据(pop)的操作。
因而按照后进先出(LIFO,last in first out)的原理运作。
在栈中,push和pop的操作都发生在栈顶
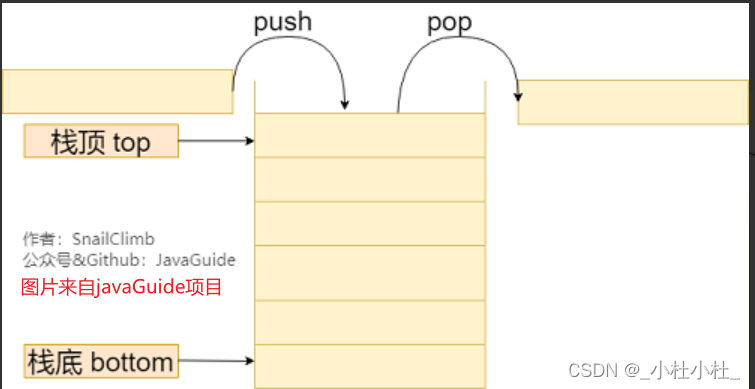
- 栈 常用一维数组或链表来实现,用数组实现的栈叫做顺序栈,用链表实现的栈叫做链式栈。
使用场景
只涉及在一端进行插入和删除数据时
- 实现浏览器的回退和前进功能
- 检查符号是否成对出现
常用方法
- push(E item):入栈
- pop():出栈
- peek():获取栈顶元素(只是获取,不删除)
- empty():判断栈是否为空
- search(Object o):基于栈顶位置(index=1,索引自顶向下递增)查找对象o,找到返回index,找不到返回-1
经典例题——有效的括号

import java.util.HashMap;
import java.util.Scanner;
import java.util.Stack;
// 1:无需package
// 2: 类名必须Main, 不可修改
public class Main {
public static void main(String[] args) {
String s = "{()}";
System.out.println(isValid(s));
}
public static boolean isValid(String s) {
HashMap<Character,Character> hashMap = new HashMap<Character,Character>();
hashMap.put(')', '(');
hashMap.put('}', '{');
hashMap.put(']', '[');
Stack<Character> stack = new Stack<Character>();
char[] c = s.toCharArray();
for(int i=0;i<c.length;i++) {
if(hashMap.containsValue(c[i])) { //如果c[i]是左括号,那就把它放进栈中
stack.push(c[i]);
}else if(hashMap.containsKey(c[i])) { //如果c[i]是右括号,那就取栈顶元素进行匹配
char topElement = stack.empty() ? '#' : stack.pop(); //考虑栈空的情况;栈不空则取栈顶元素
if(topElement != hashMap.get(c[i])) { //获取key对应的value值,如果不同,则不匹配
return false;
}
}
}
return true;
}
}
4.队列
-
可以把队列看做是食堂打饭的队伍

-
队列(Queue)是先进先出(FIFO,first int first out)的线性表。
应用场景
当我们需要按照一定顺序来处理数据的时候,可以考虑使用队列这个数据结构。
队列分类
- 单队列
单队列是最常见的队列,每次添加元素都添加到队尾。
数组实现的叫顺序队列;链表实现的叫链式队列
队列中会有“假溢出”的情况,通常在队列中都会有两个指针(front,rear),用来指向队列的头和尾—》假溢出就是rear移动到了数组之外(越界了)—》也就造成,虽然队列中还有空位置,但不能进行元素的入队了
为了避免只有一个元素的时候,队头和队尾重合使得处理变得麻烦,所以引入两个指针,front指针指向队头元素,rear指针指向队列最后一个元素的下一个位置,这样当front等于rear时,此队列不是还剩一个元素,而是空队列。——fron《大话数据结构》
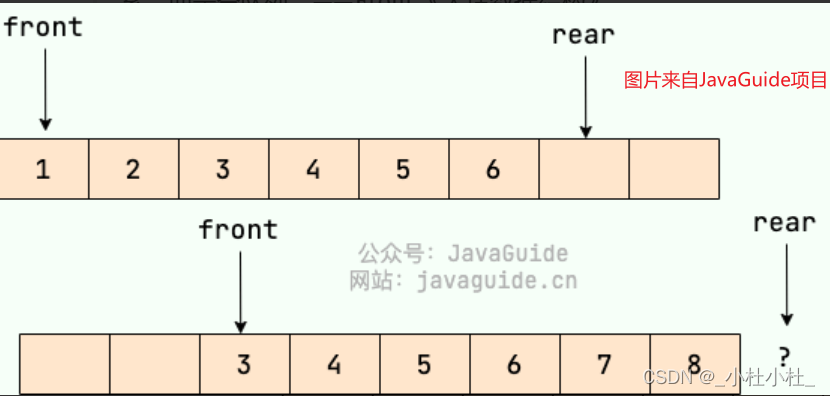
- 循环队列
循环队列就是rear指针移动到最后一个index时,下一步指向inden=0的地方—》构成一个闭环 - 双端队列
队列两端都可以进行插入、删除操作的队列
操作方法:addFirst , addLast , removeFirst , removeLast - 优先队列
优先队列 一般是由堆来实现的。
1.在每个元素入队时,优先队列会将新元素其插入堆中并调整堆。
2.在队头出队时,优先队列会返回堆顶元素并调整堆。
双端队列天生就可以实现栈的全部功能,并且在Deque接口中已经实现了相关方法。
所以Stack已经被遗弃,在java中普遍使用双端队列(Deque)来实现栈。
5.树
-
树的链式存储

-
二叉树的遍历
可以把先序,中序,后序—》这几个位置理解为遍历中间节点的位置,左右还是不变
例如:先序:就是先遍历中间节点–》中 , 左右
中序:就是在左右中间遍历中间节点—》左,中,右
后序:就是最后遍历 中间节点—》左右 中
- 先序遍历(中,左,右)
先输出根节点,再遍历左子树,最后遍历右子树
public void preOrder(TreeNode root){
if(root == null) return;
system.out.println(root.data);
preOrder(root.left);
preOrder(root.rigth);
}
- 中序遍历(左,中,右)
public void inOrder(TreeNode root){
if(root == null) return;
inOrder(root.left);
System.out.println(root.data);
inOrder(root.rigth);
}
- 后序遍历(左,右,中)
public void postOrder(TreeNode root){
if(root == null) return;
postOrder(root.left);
postOrder(root.right);
System.out.println(root.data);
}
6.哈希表
百科解释:
散列表(Hash
table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
特点
提炼一下:
- 哈希表(也叫散列表)。
- 哈希表本质是一种数据结构----》特点:可以根据一个key值直接访问数据,因此查找速度快
提到数据结构,特点是查找速度快的还有什么呢?
- 数组—》所以,Hash Table本质就是一个数组
???那它跟数组有什么区别呢?
哈希函数,哈希值,哈希冲突
-
这有一个例子:
eg.在电话表里找“王三”这个人 - 如果是数组,怎么找呢?---》遍历 for(...){ if(...)... } - 那哈希表呢? 我们把电话表中的数据,按照首字母进行分类 然后,查找 ‘w’ 里面的数据 从而,找到 “王二”
这里,我们把按首字母排序这个方法叫做哈希函数(散列函数)
键值对 Entry
-
这还有个 不算例子
我们都知道,哈希表经常存放的是一些键值对(key,value),jdk中把键值对叫做Entry。这是啥意思呢? 就是key对应着value 也就是value是由key通过哈希函数映射来的 value就叫做哈希值(hash值)
啥玩应?
-
这是个例子:
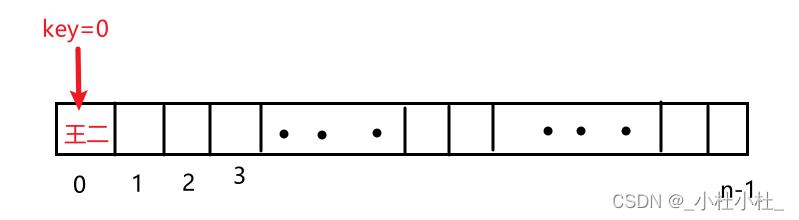
eg. 王二的学生信息:002,王二 我们根据之前说的,要有一个哈希函数, 假设哈希函数的作用是 将002--》0 那么 key = 0;value = 王二 (0,王二)就是一个键值对(key,value) 根据 0,我们可以查找出 王二 来
那 如何把kv对存到哈希表中呢?
我们说了,哈希表本质还是个数组嘞
根据 key 的值,就可以把value存到对应的位置上去
那这就有个问题了?
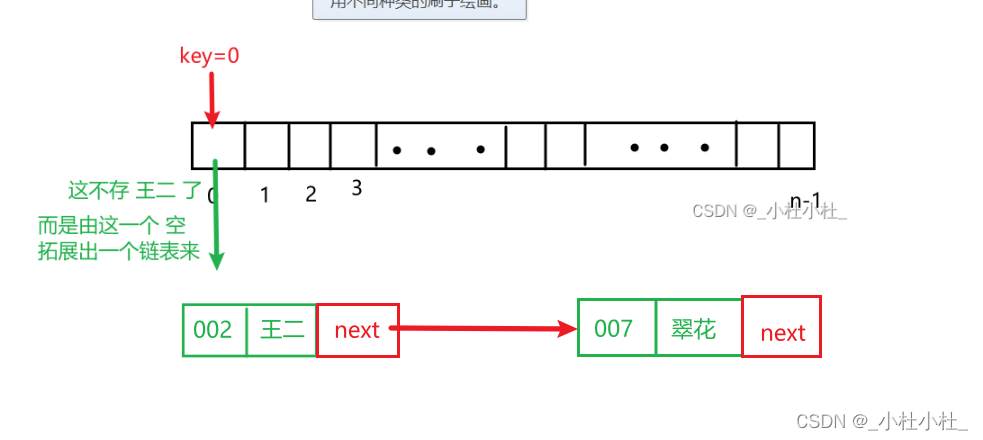
如果 还有个学生 (007,翠花)
key=0 value=翠花
那不就和 王二的key冲突了吗?
这个就叫做哈希冲突(也叫做哈希碰撞)
怎么解决?
开放寻址法和拉链法
-
开放寻址法
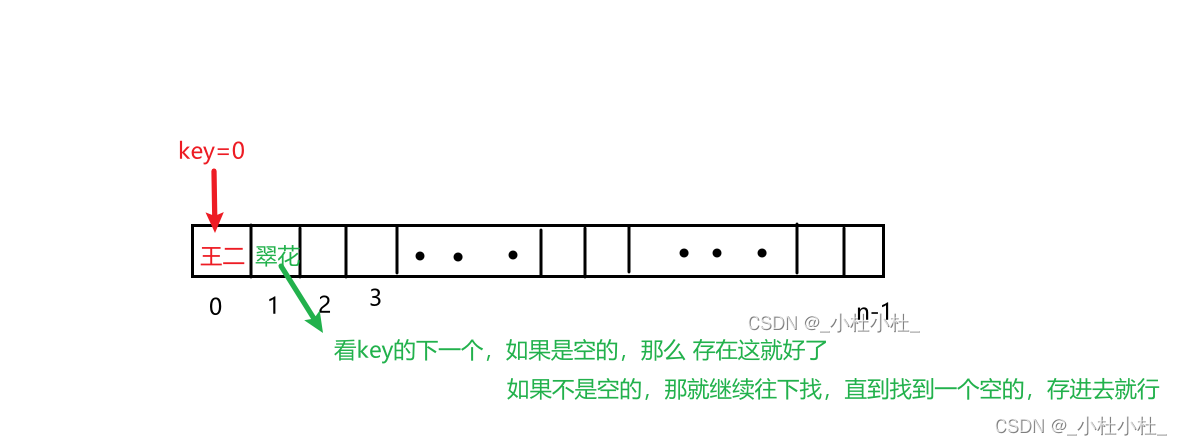
这里 会一直找不到空位置吗?不会的,对于HashMap来说,当它的增长因子(也叫负载因子),到达0.7--》比如,一共10个位置,被占了7位,那就要扩容了 扩容 是create一个数组,是原来的2倍,然后把原数组的所有Entry都重新Hash一遍,放到新数组中 重新hash 就是:把之前的数据,通过新的哈希函数计算出新的位置来存放。(因为数组扩大了,所以一般哈希函数也会有变化,就需要重新hash一遍) -
拉链法(常用)

















 2786
2786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









