






一文搞懂深度学习常见求导公式(含 sigmoid、tanh、梯度详解)
📌 本文面向刚入门深度学习的同学,带你用最简单的方式掌握几种常用函数的导数推导和它们在神经网络中的意义。公式虽多,但其实一点也不难,看完你一定会觉得:“原来就这么回事!”
🧠 为什么我们要学求导?
在深度学习中,反向传播(Backpropagation) 是训练模型的核心。而反向传播的关键就是利用导数和偏导数,去计算每个参数的“责任”,进而进行优化。
📌 所以我们要掌握各种函数的求导方法,尤其是激活函数(如 Sigmoid、Tanh)的导数,以及如何理解“梯度”和“梯度下降”。
一、指数函数的求导(基础中的基础)
📌 1.1 自然指数 e x e^x ex 的导数
d d x e x = e x \frac{d}{dx} e^x = e^x dxdex=ex
👉 它的导数等于它自己,是非常罕见又实用的性质。
📌 1.2 链式法则举例: e − x e^{-x} e−x 的求导
d d x e − x = − e − x \frac{d}{dx} e^{-x} = -e^{-x} dxde−x=−e−x
✅ 使用链式法则:先对外层求导,再乘以内层导数。
📌 1.3 底数为 a 的情况: a x a^x ax 的导数
d d x a x = a x ⋅ ln a \frac{d}{dx} a^x = a^x \cdot \ln a dxdax=ax⋅lna
如果底数是 2、10 等,就要乘上对数因子。
二、Sigmoid 函数的导数推导

📌 2.1 定义公式
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
📌 2.2 求导过程(逐步推导)
令:
y = σ ( x ) = 1 1 + e − x y = \sigma(x) = \frac{1}{1 + e^{-x}} y=σ(x)=1+e−x1
步骤:
- 设 u = 1 + e − x u = 1 + e^{-x} u=1+e−x,则 y = 1 u y = \frac{1}{u} y=u1
- 使用链式法则:
d y d x = d y d u ⋅ d u d x = − 1 u 2 ⋅ ( − e − x ) = e − x ( 1 + e − x ) 2 \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} = -\frac{1}{u^2} \cdot (-e^{-x}) = \frac{e^{-x}}{(1 + e^{-x})^2} dxdy=dudy⋅dxdu=−u21⋅(−e−x)=(1+e−x)2e−x
然后进行代数变换(可带上图示化步骤):
σ ′ ( x ) = σ ( x ) ( 1 − σ ( x ) ) \sigma'(x) = \sigma(x)(1 - \sigma(x)) σ′(x)=σ(x)(1−σ(x))
🔑 这是反向传播中的高频公式,必须掌握!
三、Tanh 函数的导数推导
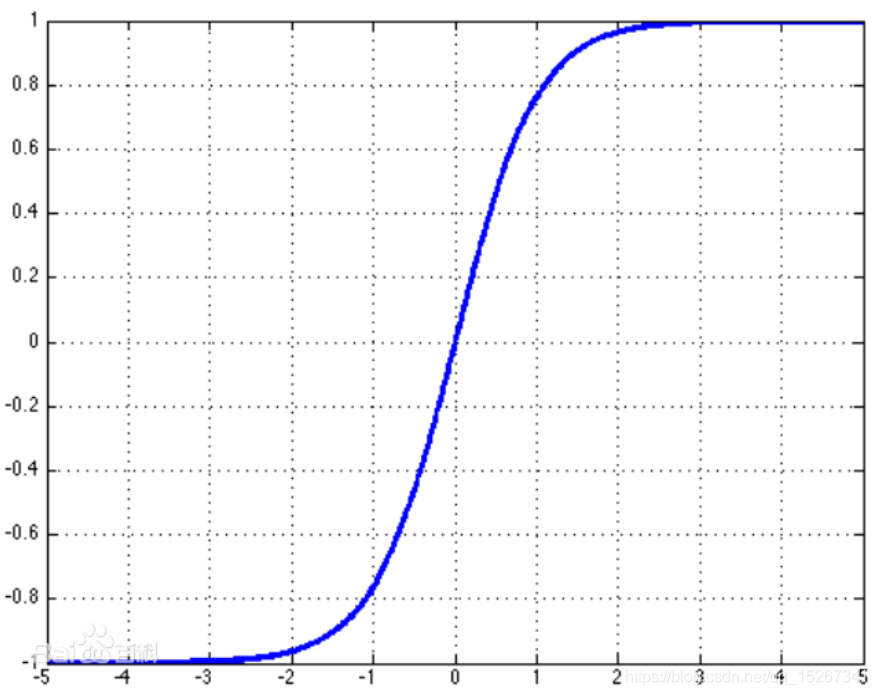
📌 3.1 函数定义
tanh ( x ) = e x − e − x e x + e − x \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x
📌 3.2 导数结论
d d x tanh ( x ) = 1 − tanh 2 ( x ) \frac{d}{dx} \tanh(x) = 1 - \tanh^2(x) dxdtanh(x)=1−tanh2(x)
👉 这个形式和 sigmoid 的导数形式非常相似。
📌 3.3 Tanh 与 Sigmoid 的关系
tanh ( x ) = 2 ⋅ σ ( 2 x ) − 1 \tanh(x) = 2 \cdot \sigma(2x) - 1 tanh(x)=2⋅σ(2x)−1
✔️ 这也说明它们之间是可以相互转换的。
四、偏导数是什么?怎么求?
📌 4.1 偏导直观理解
举例:
z = x 2 + 3 x y + y 2 z = x^2 + 3xy + y^2 z=x2+3xy+y2
- 对 x x x 求偏导时,把 y y y 当常数:
∂ z ∂ x = 2 x + 3 y \frac{\partial z}{\partial x} = 2x + 3y ∂x∂z=2x+3y
- 对 y y y 求偏导:
∂ z ∂ y = 3 x + 2 y \frac{\partial z}{\partial y} = 3x + 2y ∂y∂z=3x+2y
五、什么是梯度?为什么要“下降”?
📌 5.1 梯度的定义
∇ f ( x , y ) = [ ∂ f ∂ x , ∂ f ∂ y ] \nabla f(x, y) = \left[ \frac{\partial f}{\partial x}, \frac{\partial f}{\partial y} \right] ∇f(x,y)=[∂x∂f,∂y∂f]
👉 梯度表示函数变化最快的方向。
📌 5.2 梯度下降法
θ = θ − η ⋅ ∇ J ( θ ) \theta = \theta - \eta \cdot \nabla J(\theta) θ=θ−η⋅∇J(θ)
- θ \theta θ 是参数
- η \eta η 是学习率
- J ( θ ) J(\theta) J(θ) 是损失函数
💬 你可以把它想象成“从山顶顺着最陡的坡往下走”,最终找到最低点。
🧾 总结:常见导数速查表
| 函数 | 导数 |
|---|---|
| e x e^x ex | e x e^x ex |
| a x a^x ax | a x ⋅ ln a a^x \cdot \ln a ax⋅lna |
| ln x \ln x lnx | 1 / x 1/x 1/x |
| x n x^n xn | n ⋅ x n − 1 n \cdot x^{n-1} n⋅xn−1 |
| σ ( x ) \sigma(x) σ(x) | σ ( x ) ( 1 − σ ( x ) ) \sigma(x)(1 - \sigma(x)) σ(x)(1−σ(x)) |
| tanh ( x ) \tanh(x) tanh(x) | 1 − tanh 2 ( x ) 1 - \tanh^2(x) 1−tanh2(x) |
📌 后记
这些看起来枯燥的公式,其实是深度学习“大脑”思考的逻辑核心。
掌握它们不仅是通往反向传播的必经之路,也能帮你理解训练过程中的参数如何被优化、损失如何被最小化。
🧠 如果你觉得这篇文章有帮助,不妨点赞 👍、收藏 ⭐,也欢迎关注我,一起学习 PyTorch、神经网络和 AI 应用实践!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









