







专栏链接:
深度学习知识点总结_Mr.小梅的博客-CSDN博客本专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章介绍深度学习中的常用公式
目录
2.1 常用公式
2.1.1 卷积计算方式
bs:batchsize in_c:输入通道 h/w:输入尺寸 k:卷积核数 p:padding s:步长 out_c:输出通道

2.1.2 常用导数计算公式


2.1.3 常用公式
- Sigmoid.
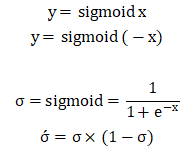

取值范围:(-∞,+∞),值域:(0,1)。属于激活函数。
计算one-hot中的二分类,可用于单标签二分类任务和多标签多分类任务中,模型预测的每个值指的是某个类别的概率,各个预测结果之间互不干扰。
例如某个模型输出:[[-0.3,0.1,0.6]],sigmoid计算后:[[0.4256, 0.5250, 0.6457]]
可以把sigmoid的计算结果看成是对某个类别的预测概率,值越趋近于1越说明属于该类别的概率大。
Sigmoid计算应用于BCELoss中。
- Softplus
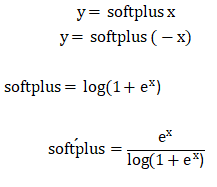

取值范围:(-∞,+∞),值域:(0,+∞),属于激活函数。
- Softmax
![]()
取值范围:(-∞,+∞),值域:(0,1)。
也称之为归一化指数函数。一般用于单标签分类任务中,模型预测的结果中,只取预测结果最大的那一个,各个预测值之间相互影响,所有预测值相加为1。
例如某个模型输出:[[-0.3,0.1,0.6]],Softmax计算后:[[0.2020, 0.3013, 0.4967]]
预测的结果中哪个值大,代表属于该类别的概率大。
- LogSoftmax
![]()
把公式展开计算如下,其中M为x中最大的值,具体如下:


- log(x)
















 1367
1367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









