







第 6章 Python 应对反爬虫策略
爬取一个网站的基本步骤
(1)分析请求:URL 规则、请求头规则、请求参数规则。
(2)模拟请求:通过 Requests 库或 urllib 库来模拟请求。
(3)解析数据:获取请求返回的结果,利用 lxml、Beautiful Soup 或正则表达式提取需
要的节点数据。
(4)保存数据:把解析的数据持久化到本地,保存为二进制文件、TXT 文件、CSV 文
件、Excel 文件、数据库等。
随着爬取的网站越来越多,你会慢慢发现有些网站获取不到正确数据,或者根本获取不了数据,原因是这些站点使用了一些反爬虫策略。
6.1 反爬虫概述
6.1.1 为什么会出现反爬虫
编写爬虫的目的是自动获取站点的一些数据,而反爬虫则是利用技术手段防止爬虫爬
取数据,为什么要防止爬虫爬取数据的原因如下所示:
很多初级爬虫非常简单,不管服务器压力,有时甚至会使网站宕机。 保护数据,重要或涉及用户利益的数据不希望被别人爬取。 商业竞争,多发生在同行之间,如电商。
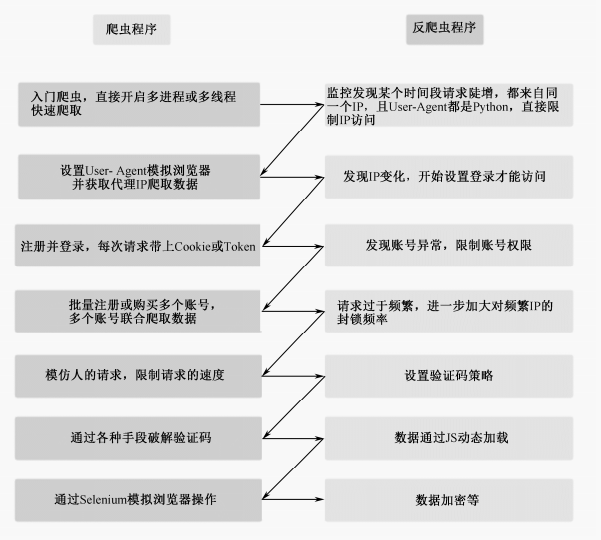
6.1.2 常见的爬虫与反爬虫大战
常见的爬虫与反爬虫大战流程
6.2 反爬虫策略
接下来了解一些基本的反爬虫策略,以及应对反爬虫的策略。
6.2.1 User-Agent 限制
服务端通过识别请求中的 User-Agent 是否为合理真实的浏览器,从而来判断是否为爬
虫程序,比如 urllib 库中默认的 User-Agent 请求头为 Python-urllib/2.1,而 Requests 库中为
python-requests/2.18.4,服务器检测到这样的非真实的浏览器请求头就会进行限制,一个正常的浏览器 User-Agent 请求头示例如下:
Mozilla/6.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/68.0.3440.106 Safari/537.36
每个浏览器的 User-Agent 因为浏览器类型和版本号的区别都会有所不同,,关于模拟 User-Agent,可以用一个很便利的库fake-useragent,但是生成伪造(模拟)数据的库中,Faker是一个非常流行的选项,它可以用来生成各种各样的假数据,如姓名、地址、电话号码等。也可用来生成useragent。
from faker import Faker
facker = Faker()
ua =facker.user_agent()
print(ua)
运行结果如下:
Mozilla/5.0 (compatible; MSIE 5.0; Windows 95; Trident/5.1)
也可以指定生成浏览器的。
from faker import Faker
def generate_user_agents(num=10):
faker = Faker()
ua =faker.user_agent()
for _ in range(num):
print("Chrome:", faker.chrome(version_from=50, version_to=80))
print("Firefox:", faker.firefox())
print("IE:", faker.internet_explorer())
print('随机生成:',ua)
if __name__ == '__main__':
# 生成并打印10个随机User-Agent字符串
generate_user_agents(1)
代码执行结果如下:
Chrome: Mozilla/5.0 (X11; Linux i686) AppleWebKit/531.0 (KHTML, like Gecko) Chrome/80.0.883.0 Safari/531.0
Firefox: Mozilla/5.0 (X11; Linux x86_64; rv:1.9.7.20) Gecko/7116-07-25 05:40:18 Firefox/3.8
IE: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/3.1)
随机生成: Mozilla/5.0 (Windows; U; Windows NT 6.1) AppleWebKit/533.16.2 (KHTML, like Gecko) Version/4.0.1 Safari/533.16.2
6.2.2 302 重定向
当访问某个站点的速度过快或发出的请求过多时,会引起网络流量异常,服务器识别出是爬虫发出的请求,会向客户端发送一个跳转链接,大部分是一个图片验证链接,有时是空链接。对于这种情况,有两种可选的操作。
- 降低访问速度,比如每次请求后调用 time.sleep()休眠一小段时间,避免被封。
- 使用代理 IP 进行访问。
任务量比较小时可以采取第一种策略。另外,这个休眠时间建议使用一个随机数,比如 time.sleep(random.randint(1,10)),因为有些服务器会把定时访问判定为爬虫。
6.2.3 IP 限制
除了上述这种单位时间内访问频率过高让服务器判定为爬虫进行封禁,导致无法获取数据的情况,还有一些站点限制了每个 IP 在一定时间内访问的频次,比如每个 IP 一天只能访问 100 次,超过这个次数就不能访问了。此时降低访问速度也是没用的,只能通过代理 IP 的形式来爬取更多的数据。
6.2.4 什么是网络代理
网络代理是一种特殊的网络服务,网络终端(客户端)通过这个服务(代理服务器)和另一个终端(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2054
2054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









