







 本文介绍了如何使用Python结合天行数据的API开发垃圾分类应用,包括桌面APP和微信小程序。内容涉及选择合适的垃圾分类服务、API接口封装、使用tkinter创建GUI界面以及事件处理逻辑。
本文介绍了如何使用Python结合天行数据的API开发垃圾分类应用,包括桌面APP和微信小程序。内容涉及选择合适的垃圾分类服务、API接口封装、使用tkinter创建GUI界面以及事件处理逻辑。
嗨害大家好鸭!我是小熊猫❤
今天这篇文章主要介绍的是:
如何利用现有的工具来实现一个垃圾分类的应用
有什么python相关报错解答自己不会的、或者源码资料/模块安装/女装大佬精通技巧 都可以来这里:(https://jq.qq.com/?_wv=1027&k=2Q3YTfym)或者+V:python5180问我
要想垃圾分类,首先,自我定位明确:

言归正传
主要做了三个核心内容:
- 对比现有垃圾分类服务,挑选一个合适并编码实现
- 开发桌面版垃圾分类APP
- 开发垃圾分类微信小程序
上面这三部分第一部分是后端的活儿,
其他两部分都是前端的活儿,
所以,我在这三块没有太多经验,
基本上是面向搜索引擎编程。
先看效果图,PC版:
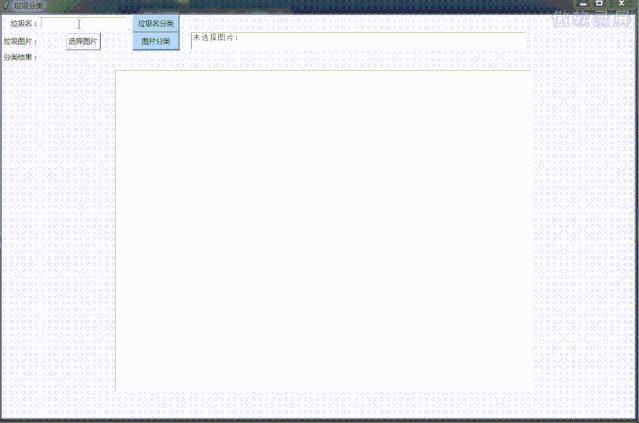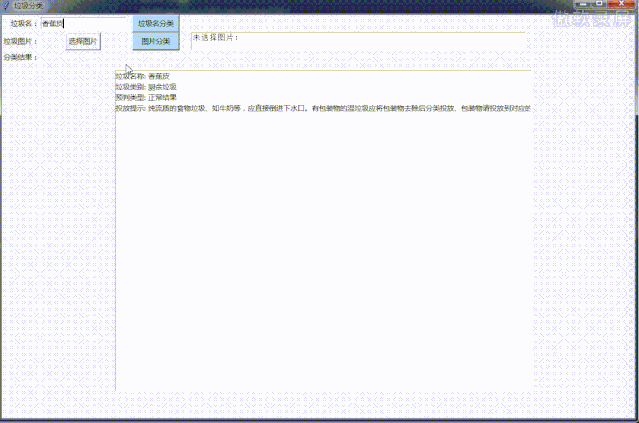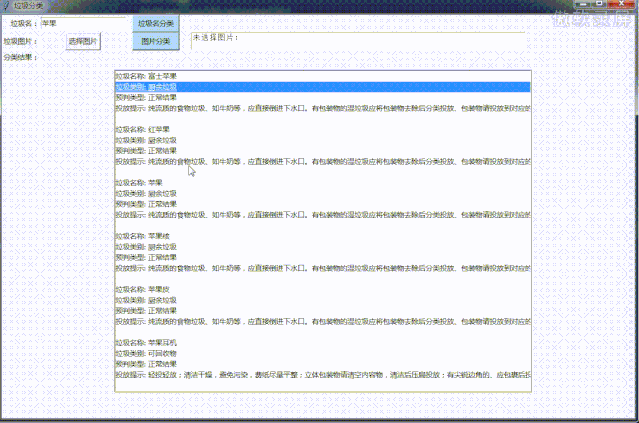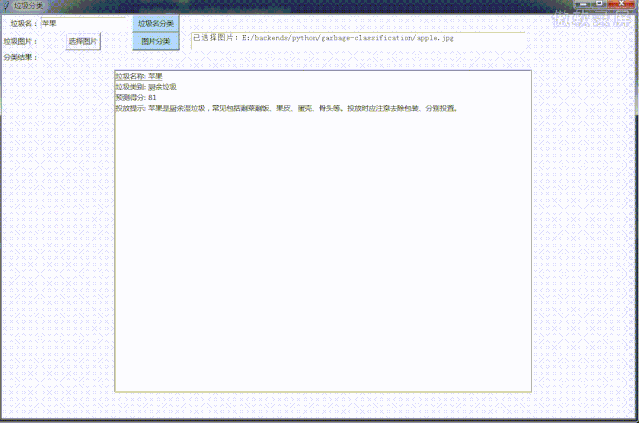
小程序:
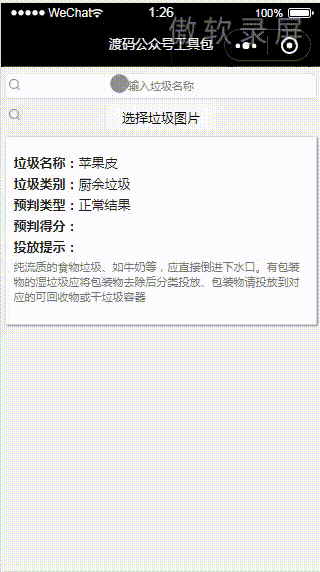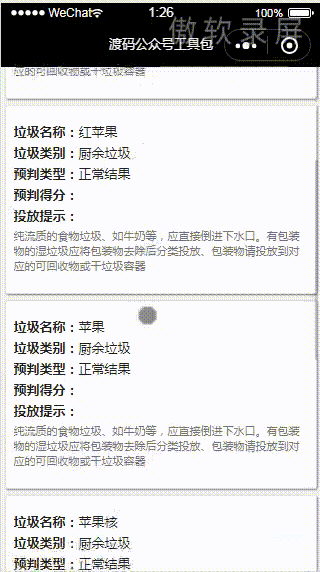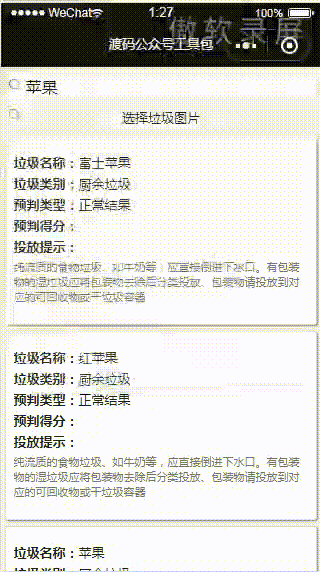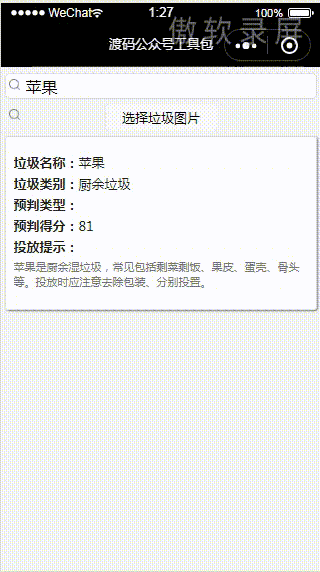
那么,接下来我们进入到具体的细节是如何做的。
其实垃圾分类已经开始很长一段时间了,肯定会有一些服务商把垃圾分类的能力通过API的方式开放出来,供大家调用。我找了3家简单对比下供大家参考:
聚合数据(www.juhe.cn):提供文本、图像、语音分类。免费调用20次,定价不灵活只能批量购买
天行数据(www.tianapi.com):提供文本、图像、语音分类。文本分类5000次,其他50次,定价按量计费
京东AI开放平台:提供文本、图像、语音分类。免费,每日5000次
简单对比了图像分类情况,聚合和天行数据明显更好,再综合定价因素最终我决定用天行数据。
下面就来编写代码,将API接口封装成我们需要的服务,以文本(垃圾名称)分类接口为例,请求的接口如下
http://api.tianapi.com/txapi/lajifenlei/index?key=APIKEY&word=眼镜

APIKEY需要到天行网站注册来获取,返回的结果如下:
{
"code":200,
"msg":"success",
"newslist":[
{
"name":"隐形眼镜",
"type":3,
"aipre":0,
"explain":"干垃圾即其它垃圾,指除可回收物、有害垃圾、厨余垃圾(湿垃圾)以外的其它生活废弃物。",
"contain":"常见包括砖瓦陶瓷、渣土、卫生间废纸、猫砂、污损塑料、毛发、硬壳、一次性制品、灰土、瓷器碎片等难以回收的废弃物",
"tip":"尽量沥干水分;难以辨识类别的生活垃圾都可以投入干垃圾容器内"
},
{
"name":"眼镜",
"type":3,
"aipre":0,
"explain":"干垃圾即其它垃圾,指除可回收物、有害垃圾、厨余垃圾(湿垃圾)以外的其它生活废弃物。",
"contain":"常见包括砖瓦陶瓷、渣土、卫生间废纸、猫砂、污损塑料、毛发、硬壳、一次性制品、灰土、瓷器碎片等难以回收的废弃物",
"tip":"尽量沥干水分;难以辨识类别的生活垃圾都可以投入干垃圾容器内"
},
]
}
接口的字段说明大家可以看官网文档,这里我就不再赘述了。
下面来编写请求文本分类接口的代码:
import base64
import requests
class TxApiService:
def __init__(self):
self.appkey = 'xxx' # 需要换成自己的
self.text_cls_url_root = 'https://api.tianapi.com/txapi/lajifenlei/index?key=%s&word=%s'
self.img_cls_url_root = 'https://api.tianapi.com/txapi/imglajifenlei/index'
def get_text_cls_res(self, garbage_name):
url = self.text_cls_url_root % (self.appkey, garbage_name)
response = requests.get(url)
res = []
if response.status_code == 200:
res_json = response.json()
if res_json.get('newslist'):
new_list_json = res_json['newslist']
for item in new_list_json:
name = item.get('name')
cat  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1490
1490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









