







专栏目录:《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有40+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
对YOLOv10感兴趣的同学可以先看YOLOv8,因为改进方式大部分一样,我也会尽快更新相关的教程
YOLOv10训练报错
YOLOv10是在YOLOv8基础上修改的,即:训练方法和过程是相同的。
但按照v8训练程序train.py,如下所示,直接训练:
from ultralytics import YOLO
# Load a model
model = YOLO("ultralytics/cfg/models/v8/yolov8n.yaml") # build a new
# train
model.train(data='dataset/data.yaml',
cache=False,
imgsz=640,
epochs=100,
batch=16,
close_mosaic=0,
workers=4,
device='0',
optimizer='SGD', # using SGD
amp=False, # close amp
project='runs/train',
name='exp',
)
会提示以下错误:
AttributeError: ‘str’ object has no attribute ‘view’
解决方法
把代码中的YOLO改为YOLOv10即可,注意下面代码第一行和第三行。
from ultralytics import YOLOv10
# Load a model
model = YOLOv10("ultralytics/cfg/models/v10/yolov10n.yaml")
# train
model.train(data='dataset/data.yaml',
cache=False,
imgsz=640,
epochs=100,
batch=16,
close_mosaic=0,
workers=4,
device='0',
optimizer='SGD', # using SGD
amp=False, # close amp
project='runs/train',
name='exp',
)
当然这个是基于你下载的YOLOv10的官方仓库的代码,即THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection (github.com)
但是现在ultralytics已经将YOLOv10添加到其仓库中 ,根据官方提供的说明,用ultralytics也可以运行yolov10,启动脚本如下:
from ultralytics import YOLO
# Load YOLOv10n model from scratch
model = YOLO("yolov10n.yaml")
# Train the model
model.train(data="coco8.yaml", epochs=100, imgsz=640)即和YOLOv8的启动脚本是一样的。不用再导入YOLOv10,也大概率不会产生这样的错误了。
YOLOv10创新点回顾:
创新点
无NMS的一致双分配(consistent dual assignments):
YOLOv10提出了一种通过双标签分配而不用非极大值抑制NMS的策略。这种方法结合了一对多和一对一分配策略的优势,提高了效率并保持了性能。
效率-精度驱动的模型设计(Holistic Efficiency-Accuracy Driven Model Design):
轻量化分类头:在不显著影响性能的情况下,减少了计算开销。
空间-通道解耦下采样:解耦空间下采样和通道调整,优化计算成本。
基于秩的块设计:根据各阶段的内在秩适应块设计,减少冗余,提高效率。
大核卷积和部分自注意力PSA:在不显著增加计算成本的情况下,增强了感受野和全局建模能力。
一致双分配策略(Consistent Dual Assignments)
YOLOv10引入了一种新的双分配策略,用于在训练期间同时利用一对多(one-to-many)和一对一(one-to-one)标签分配。这种方法在保持模型高效训练的同时,摆脱了推理过程中对非极大值抑制NMS的依赖。
双标签分配(Dual Label Assignments)
一对多分配:在训练期间,多个预测框被分配给一个真实物体标签。这种策略提供了丰富的监督信号,优化效果更好。
一对一分配:仅一个预测框被分配给一个真实物体标签,避免了NMS,但由于监督信号较弱,容易导致收敛速度慢和性能欠佳。
双头架构:模型在训练期间使用两个预测头,一个使用一对多分配,另一个使用一对一分配。这样,模型可以在训练期间利用一对多分配的丰富监督信号,而在推理期间则使用一对一分配的预测结果,从而实现无NMS的高效推理。
根据官方的代码,画出C2fCIB的模块图,代码中有两种结构,因此画了两张图 ,因为整体的结构和YOLOv8的是一样的,因此不再画出整个YOLOv10的结构图
class CIB(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, e=0.5, lk=False):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = nn.Sequential(
Conv(c1, c1, 3, g=c1),
Conv(c1, 2 * c_, 1),
Conv(2 * c_, 2 * c_, 3, g=2 * c_) if not lk else RepVGGDW(2 * c_),
Conv(2 * c_, c2, 1),
Conv(c2, c2, 3, g=c2),
)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv1(x) if self.add else self.cv1(x)
class C2fCIB(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, lk=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(CIB(self.c, self.c, shortcut, e=1.0, lk=lk) for _ in range(n))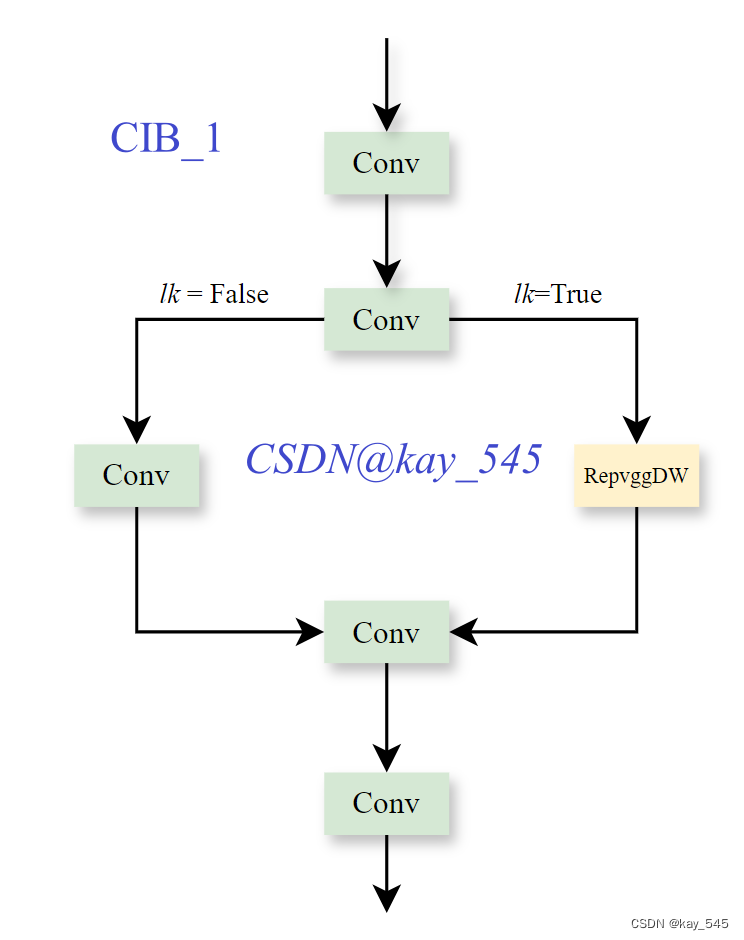
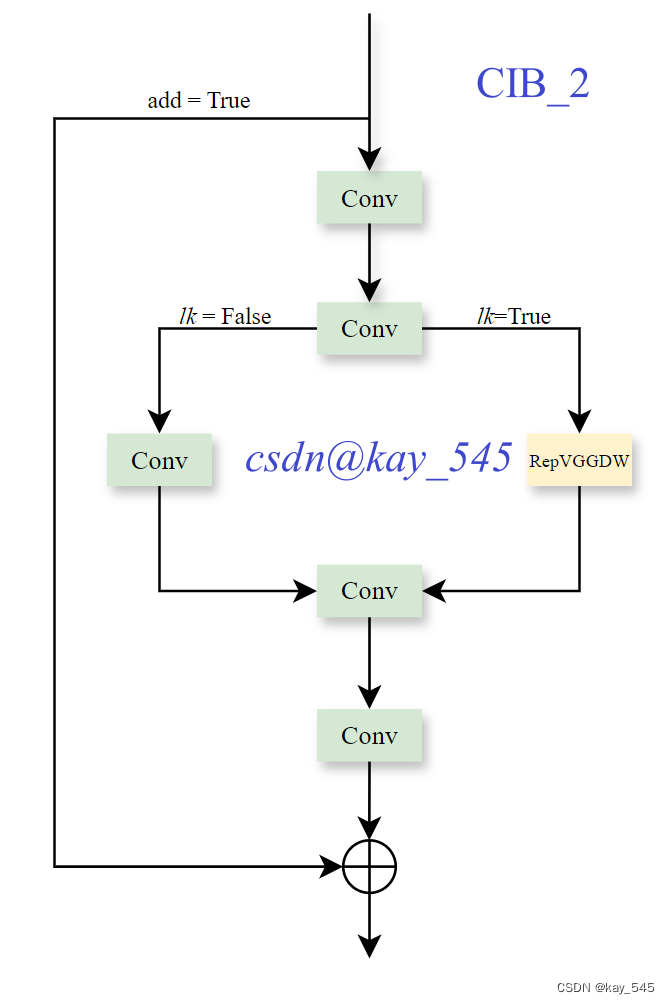
YOLOv10引入了额外的one-to-one头部,通过双分配策略,在训练时提供更丰富的监督信息,而在推理时则利用one-to-one头部进行高效预测,从而无需NMS后处理。此外,YOLOv10从效率和准确性两个方面全面优化了YOLO的各个组件,包括轻量级分类头部、空间-通道解耦的下采样层、基于秩的模块设计等,以降低计算冗余并提升模型性能。
YOLOv10检测器的提出不仅为实时目标检测领域带来了新的突破,也展示了通过后处理和模型设计的联合优化,同时提升效率和精度的有效思路。YOLOv10检测器有望在自动驾驶、机器人导航、物体跟踪等实际应用中得到广泛应用,为实时目标检测任务带来更高的效率。
对于后处理,我们提出了用于NMS-free训练的一致双分配策略,实现了高效的端到端检测。在模型架构方面,我们引入了全面的效率和准确性驱动的模型设计策略,改善了性能和效率之间的权衡。这些创新带来了我们的YOLOv10,这是一个全新的实时端到端目标检测器。大量的实验结果表明,YOLOv10与其他先进检测器相比,在性能和延迟方面都取得了state-of-the-art的成果,充分展示了其优越性。

















 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











