








🌈 个人主页:十二月的猫-CSDN博客
🔥 系列专栏: 🏀编译原理_十二月的猫的博客-CSDN博客💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光
目录
1. 预测分析技术与LL(1)文法
思考回溯算法的问题——随意选择文法产生式作为操作。
想要不是随便选择,而是有目的性的选择就需要 考察后面输入的值是什么。
这也就是为什么这类算法叫做预测分析(考察下一位是什么,然后预测哪个产生式可能性高)~~
基本思想:采用深度优先策略构建解析树,每次为非终结符号选择适当的产生式,以避免回溯。具体实现上通过向前查看输入中的一个或多个尚未被匹配的终结符来选定产生式。
对于非左递归文法,因不再回溯所以速度更快;但是仍存在无法处理的文法(例如左递归文法)。
考虑通过向前查看一个输入符号就能用预测分析算法解析的文法:人们将这类文法定义为LL(1)文法。
一个文法是LL(1)文法的充要条件是L:每个非终结符A的两个不同产生式A→α,A→β满足SELECT(A→α)∩SELECT(A→β)=∅。
其中第一个“L”表示从左向右扫描输入,第二个“L”表示最左推导,“1”表示只需要看一个输入符号。这个命名规则在后面同样适用。
要进行这样的预测就需要语法分析表,构建语法分析表的过程需要FIRST和FOLLOW两个函数的辅助,二者都可以辅助选择合适的生成式:
- FIRST(α):可以出现在α导出的句型的开头的终结符的集合;如果α⇒ϵ∗,那么ϵ也包含在FIRST(α)中。
- FOLLOW(α):可能在某些句型中紧跟在α右边的终结符的集合。
FOLLOW(α):是针对于非终结符而言的,这意味着α只能是非终结符。
FIRST(α):是针对非终结符和终结符而言的,这意味着α可以是终结符也可以是非终结符。
小提示:后面的很多算法求解过程都会用到 不动点思想(While直到集合没变化停止)🤗!
1.1 FIRST集求法
规则如下:
- 如果X是一个终结符,那么FIRST(X)=X
- 如果X是一个非终结符,且X→Y1Y2...Yk∈P(k≥1),那么如果对于某个i,a在FIRST(Yi)中且ε在所有的FIRST(Y1),FIRST(Y2)...FIRST(Yi−1)中,那么把a加入FIRST(X)中
- 如果X→ε,那么把ε放入FIRST(X)中
求串的first:
-
向FIRST(X1X2...Xn)中加入FIRST(X1)中的所有非ε符号
-
如果ε在FIRST(X1)中,那么把FIRST(X2)中所有非ε符号加入FIRST(X1X2...Xn)......以此类推
-
最后,如果对于所有的i,ε在FIRST(Xi)中,那么把ε加入FIRST(X1X2...Xn)

上面的代码希望大家好好体会一下,非常有助于理解!!😊😊
1.2 求FOLLOW集
不断应用以下规则,知道没有新的终结符可以加到任何FOLLOW集合。
- 将$放入FOLLOW(S)中,其中S是开始符号,$是输入右端的结束标记
- 如果存在一个产生式A→αBβ,那么FIRST(β)中所有非ε符号都在FOLLOW(B)中
- 如果存在一个产生式A→αB,或存在A→αBβ且FIRST(β)包含ε,那么FOLLOW(A)中的所有元素都在FOLLOW(B)中这里说明了一种FOLLOW(B)对于FOLLOW(A)的依赖关系
求FOLLOW的过程是不断更新的过程,FOLLOW集直接有依赖关系,如果后面一个FOLLOW集更新了,那么所有依赖他的FOLLOW集都需要更新。可以在他们之间建一条边,说明这种依赖关系。

上面的代码希望大家好好体会一下,非常有助于理解!!😊😊
小tip:用其他元素的first和follow集来求解自己的时一定加入的都是非ε符号
1.3 求SELECT集
SELECT集针对的是产生式
FOLLOW集和FIRST集针对的是符号(终结符、非终结符)
SELECT(A→α):要选择A→α的预测符集合
对于一个产生式A→αA→α,求SELECT(A→α)SELECT(A→α)
- 若ε∉FIRST(α),那么SELECT(A→α)=FIRST(α)
- 若ε∈FIRST(α),那么SELECT(A→α)=FIRST(α)∪FOLLOW(A)
2. 求First集与Follow集例题
强烈建议去看下面这个博客:如何求First集与Follow集(超详细)_first集合和follow集合的求法-CSDN博客
这个博客求解方法使用的是:不动点算法,也是前面提到的伪代码流程
可能有的人喜欢按照规则去求解First集与Follow集,可以去看下面这篇文章:[编译原理]FIRST集和FOLLOW集的介绍和求解_文法first集follow集的计算-CSDN博客
我并不喜欢~~~
例1:写出下面文法中所有非终结符的FIRST集。
E → TE’
E’ → +E|ε
T → FT’
T’ → T|ε
F → PF’
F’ → *F’|ε
P → (E)|a|b|^
解答:
FIRST(E’) = {+ , ε}
FIRST(F’) = {* , ε}
FIRST(P) = {( , a , b , ^}
FIRST(F) = FIRST(PF’) = FIRST(P)\{ε}= {( , a , b , ^}
FIRST(T) = FIRST(FT’) = FIRST(F)\{ε}= {( , a , b , ^}
FIRST(E) = FIRST(TE’) = FIRST(T)\{ε}= {( , a , b , ^}
FIRST(T’) = {FIRST(T)\{ε}} ∪ {ε} = {( , a , b , ^ ,ε}
例2:写出下面文法中求FIRST(S),FIRST(A),FIRST(B)。
G: S → BA
A → BS|d
B → aA|bS|c
解答:
FIRST(A) = {FIRST(B)\{ε}}∪{d} = {a, b, c, d}
FIRST(S) = {FIRST(B)\{ε}} = {a, b, c}
FIRST(B)={a, b, c}
例3:写出下面文法中所有非终结符的FOLLOW集。
G: E → TE’
E’ → +TE’|ε
T → FT’
T’ → *FT’|ε
F → (E)|i
已知:
FIRST(E) = FIRST(T) = FIRST(F) = {(, i}
FIRST(E’) = {+, ε}
FIRST(T’) = {*, ε}
解答:



例4:写出下面文法中所有非终结符的LL(1)分析表。
G'[E]: E → TE'
E' → +TE'|ε
T → FT'
T' → *FT'|ε
F → (E)|i
这个文法就是前面给出的文法,前面已经求出first和follow集,只要求出select集就可以写出LL(1)分析表了。
已知:
FIRST(E) = {(,i}
FIRST(E') = {+,ε}
FIRST(T) = {(,i}
FIRST(T') = {*,ε}
FIRST(F) = {(,i}
FOLLOW(E) = {#,)}
FOLLOW(E') = {#,)}
FOLLOW(T) = {+,#,)}
FOLLOW(T') = {+,#,)}
FOLLOW(F) = {*,+,#,)}
解答:
SELECT(E → T E') = {(,i}
SELECT(E' → + T E') = {+}
SELECT(E' → ε) = {#,)}
SELECT(T → F T') = {(,i}
SELECT(T' → * F T') = {*}
SELECT(T' → ε) = {+,#,)}
SELECT(F → ( E )) = {(}
SELECT(F → i) = {i}于是有分析表如下:
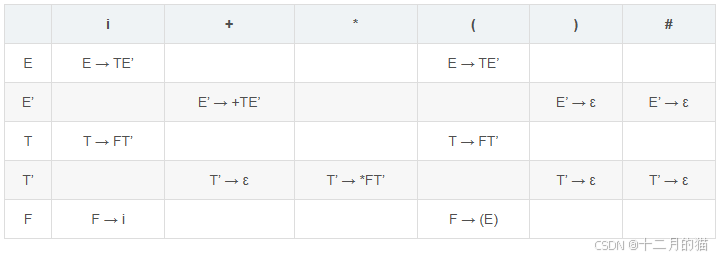
到这里,我们也就能理解为什么 SELECT(A→α)∩SELECT(A→β)=∅是LL(1)算法的一个条件了
3. 总结
本文到这里就结束啦~~
本系列专栏将专注于【编译原理】知识。
内容包括:知识点讲解、习题练习、重点知识带练等~~目前已完成:
【编译原理】编译原理知识点汇总·词法分析器(正则式到NFA、NFA到DFA、DFA最小化)-CSDN博客
【编译原理】词法分析器设计(山东大学实验一)_山东大学编译原理实验-CSDN博客
【编译原理】语法、语义分析器设计(山东大学实验二)_语法分析实验-实现一个简单语法分析器(自上而下方法)实验小结-CSDN博客
【编译原理】代码生成器的构建与测试(山东大学实验三)_编译原理实验语义分析代码-CSDN博客 【编译原理】一篇搞定正规式到NFA、NFA到DFA、DFA最小化-CSDN博客
【编译原理】一篇搞定语法分析器对文法的要求(上下文无法文法、消除二义性文法、消除左递归)-CSDN博客期待您的关注~~🥰🥰
猫猫陪你永远在路上💪💪
如果觉得对你有帮助,友友们可以点个赞,收个藏呀~




















 2256
2256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











