








🌈 个人主页:十二月的猫-CSDN博客
🔥 系列专栏: 🏀各种软件安装与配置_十二月的猫的博客-CSDN博客💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光
关注本专栏并在专栏中任何一篇文章下发表评论,即可获得【PyCharm、Clion、DataGrip、DataSpell、IDEA、Goland、Rider、PhpStorm等软件的破解版】。
目录
4.2 编辑模式(Enter 键 或 点击单元格输入区域 启动)
1. 前言
在学习这篇文章之前,如果没有安装过Jupyter Notebook的友友可以参考下面文章:
在上篇文章中,猫猫手把手带大家安装了Jupyter、Anaconda等。接下来,我将带大家入门使用Jupyter Notebook这个好用的工具,相信它将成为你学习生涯中的一大助力🥰。
2. Jupyter的使用
运行Jupyter:
Jupyter Notebook 通过 Anaconda 或 Jupyter 安装的本地服务器在浏览器上运行。因此,请确保您安装了浏览器,例如 Firefox、Google Chrome 或 Edge。在 Windows 上,转到开始菜单并启动 Anaconda。在 Anaconda 面板中,单击 Jupyter Notebook。如果您仅使用 pip 安装了 Jupyter,则从命令提示符运行以下命令来启动 Jupyter Notebook。
jupyter notebook成功运行后,您应该看到默认浏览器打开,如下所示。这意味着您的 Jupyter Notebook 运行良好。
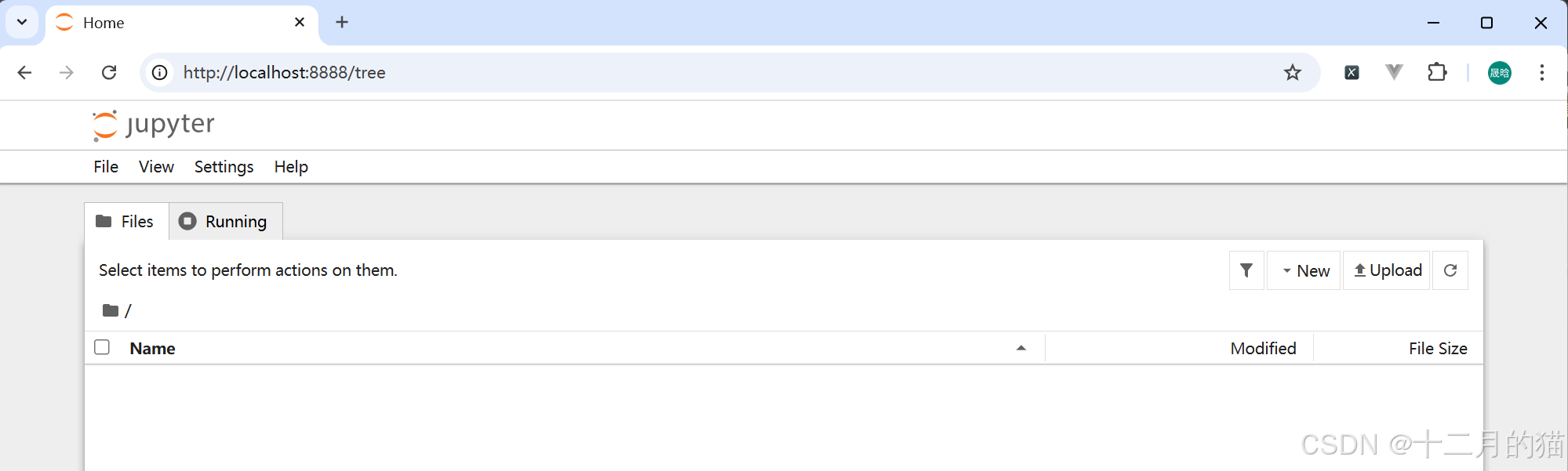
上面打开的页面还不是笔记本。它实际上是笔记本管理中心,旨在帮助您管理 Jupyter 笔记本。将其视为探索、编辑和创建笔记本的启动板。
请记住,仪表板仅提供对位于 Jupyter 的启动目录(默认目录 或 命令行自定义工作目录)内的文件和子文件夹的访问。例如,您可以通过从命令行遍历到任意目录来运行命令“jupyter notebook”。该页面将在当前工作目录中打开,此时这个目录就是Jupyter的启动目录。
具体命令如下:
jupyter notebook --notebook-dir="/home/arindam/Downloads/"当然,在上一篇文章中:
猫猫已经教大家将Jupyter的默认启动目录的设置方法。通过那个方法,我们可以将默认目录修改为我们想要的目录,从而就避免了每次都用命令来指定启动目录的麻烦。
2.1 新建笔记本
在本部分中,您将学习如何运行和保存笔记本、了解其结构以及导航界面。我们还将介绍关键术语,以帮助您自信地使用 Jupyter Notebooks 并为下一部分做好准备。接下来的部分将引导我们完成一个数据分析示例,将我们所学到的一切付诸实践。
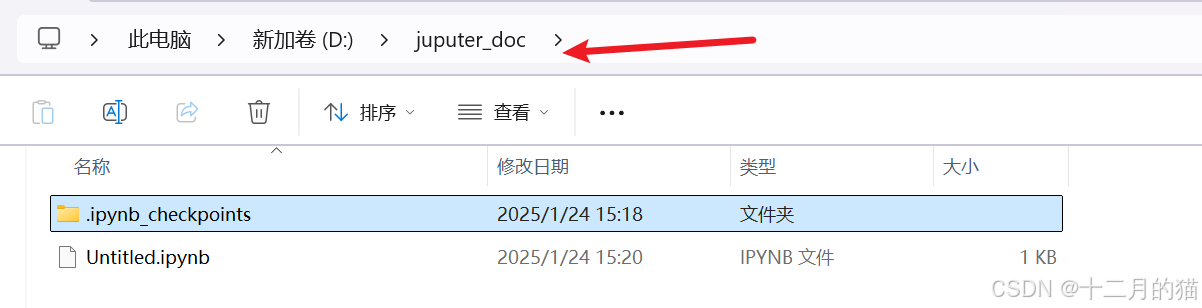
1、我这里进入的文件夹是自己设置的D盘下的Jupyter_doc:
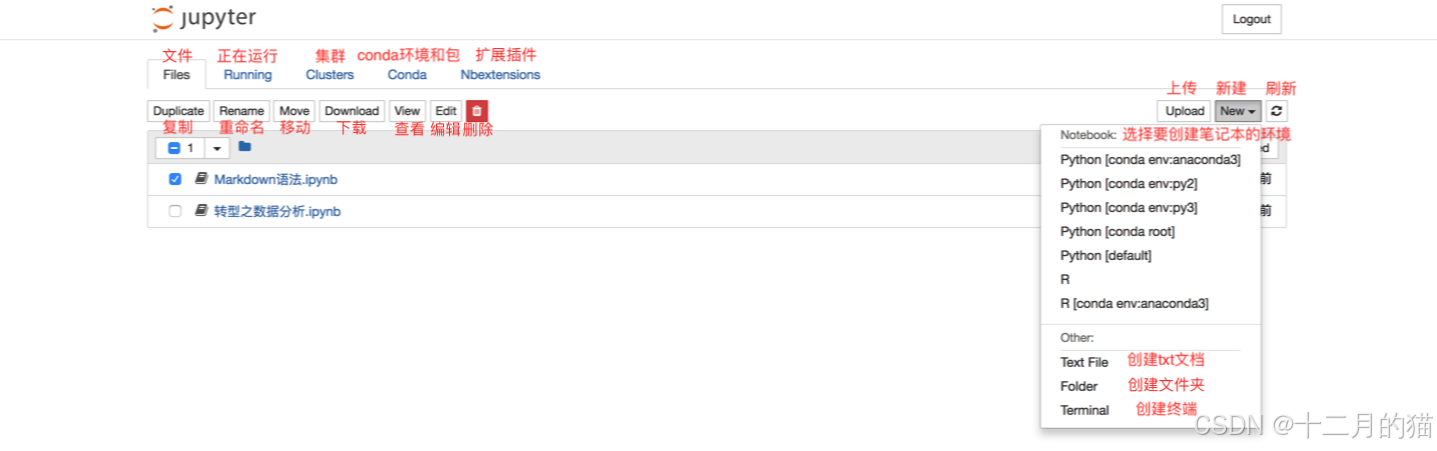
2、从顶部菜单中选择new > Python 3。这将创建您的第一个笔记本
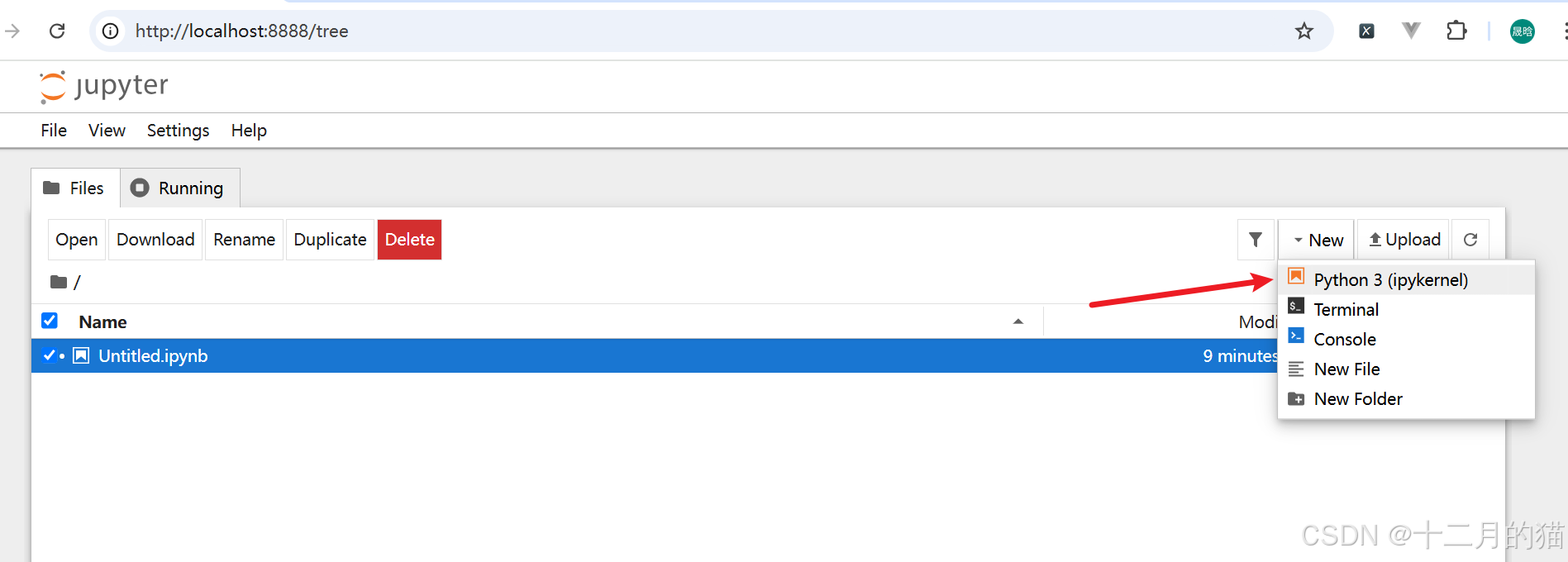
3、此后进入新页面: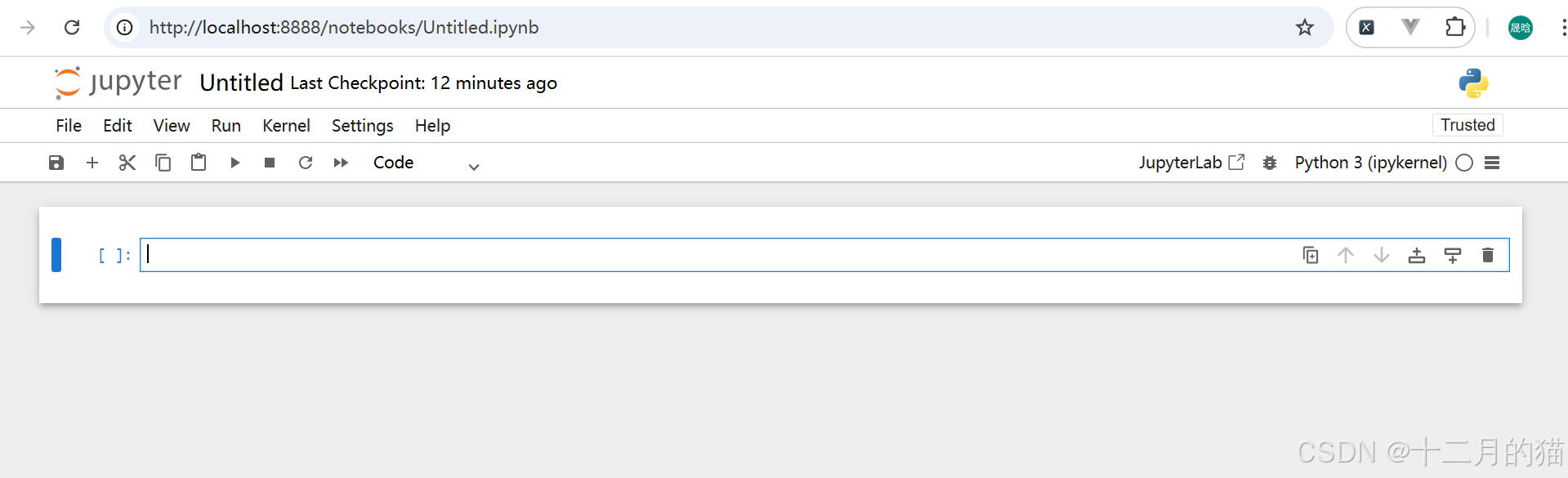
4、如果您返回笔记本管理中心,您应该会看到创建了一个名为 Untitled.ipynb 的新文件。绿色标签表明它正在运行:
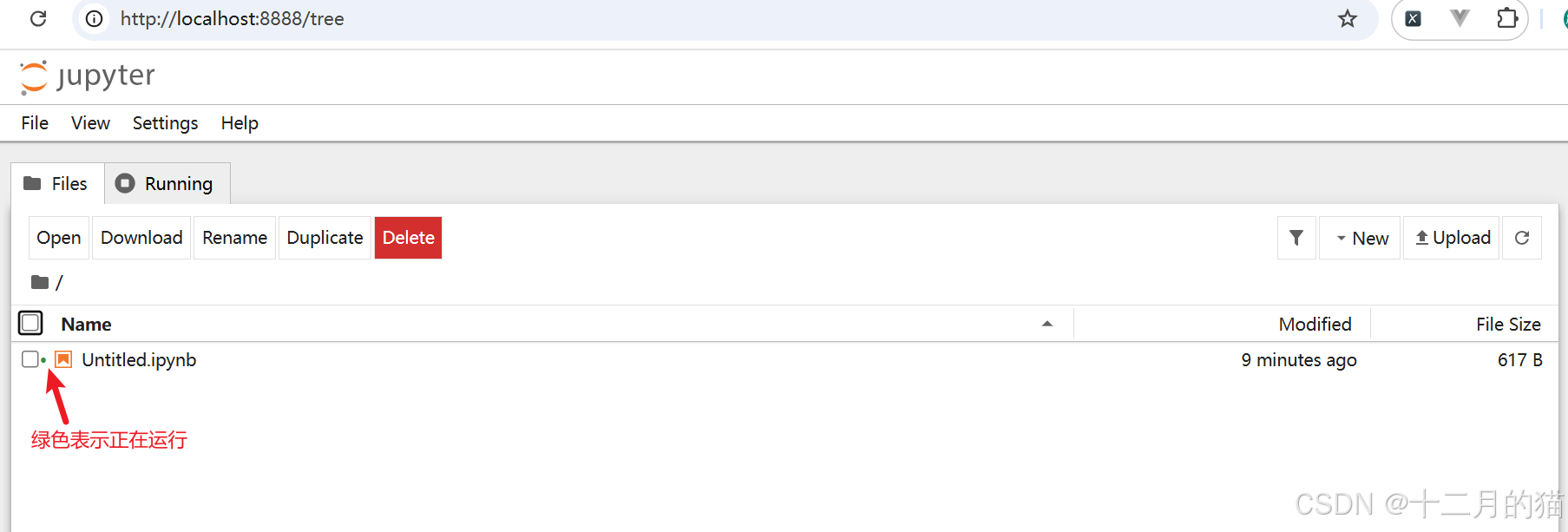
2.2 新建文件夹
1、从顶部菜单中选择new > New Folder。这将创建您的第一个文件夹:
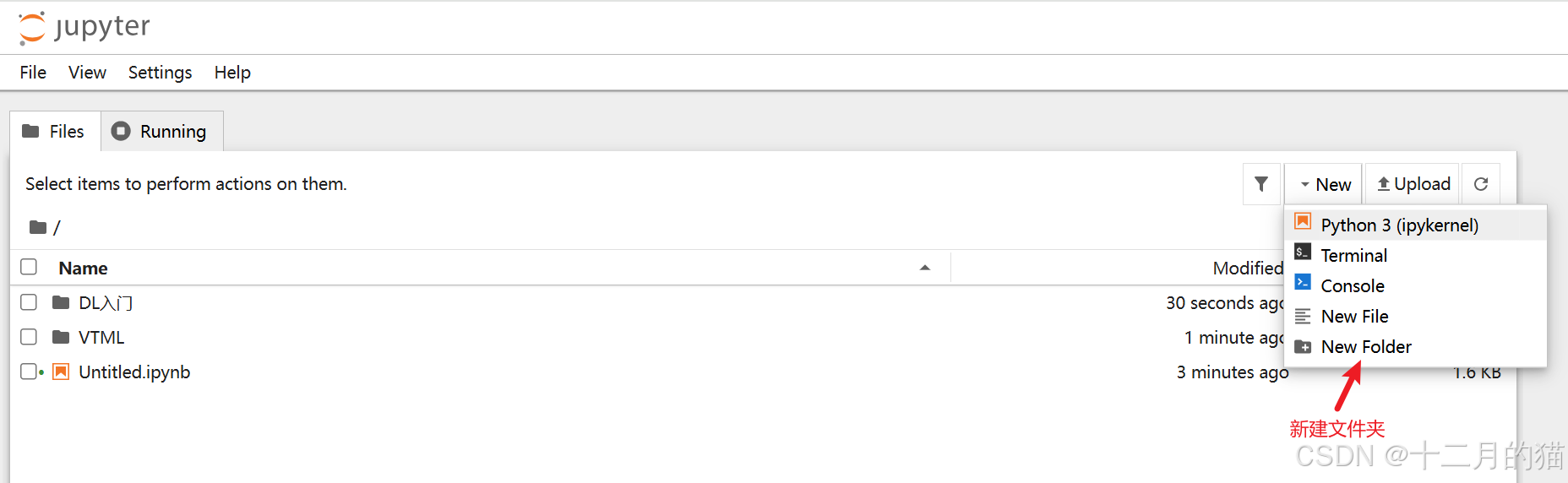
2、右键单击文件夹,选择Rename对文件夹进行更名:
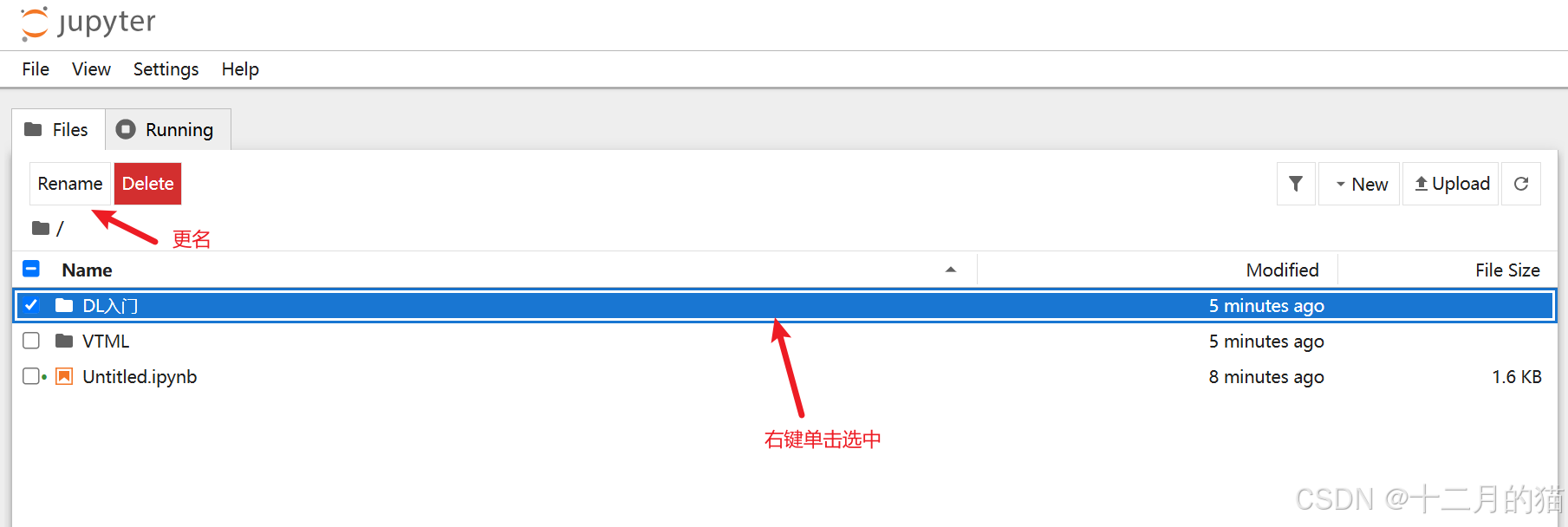
2.3 图解Files页面(必看)
3. 什么是 .ipynb 文件?
创建新笔记本时,会创建一个扩展名为 ipynb 的新文件。该文件本质上是一个文本文件,使用 JSON 格式来描述笔记本的内容。它包括每个单元格及其内容,以及已转换为文本字符串和一些元数据的任何图像附件。您可以通过从仪表板控件中选择“编辑”来查看笔记本的内容,但不建议您自行编辑元数据。
3.1 笔记本核心
当您打开 .ipynb 文件时,将为该文件打开笔记本界面。您可以环顾四周并感受一下用户界面、菜单和命令。您可以单击每个菜单项来查看可用选项。所有菜单项基本上都是笔记本命令,可以使用小“键盘”图标进行访问。您应该了解的两个关键菜单项是“kernel”和“cell”。
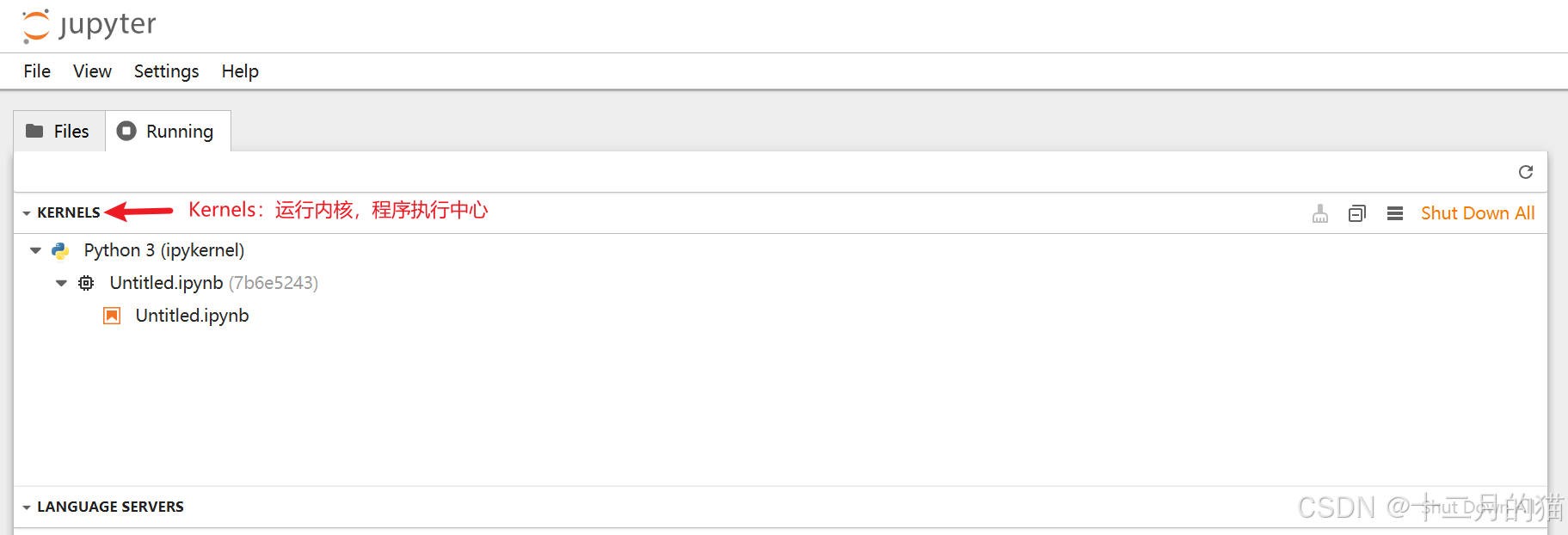
- 内核是在笔记本中运行代码的计算引擎。
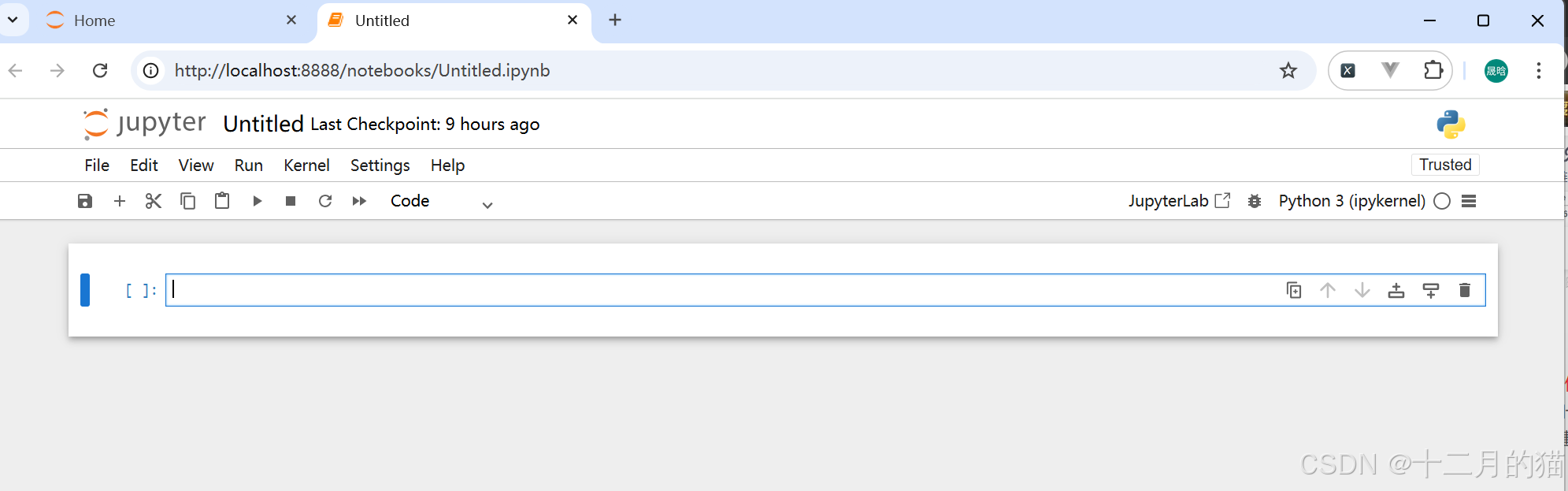
- 单元格包含笔记本中要执行的文本或代码。
Kernels(内核) :
Cell(单元格 ):
3.2 单元
单元是任何笔记本的支柱。它可能包含您的代码或任何 Markdown 文本。因此,Code 单元格包含可由 Python 内核执行的代码。运行代码时,输出将显示在生成它的单元格下方。
因为Cell中包含代码或者文本,因此用Jupyter做代码笔记相当地方便
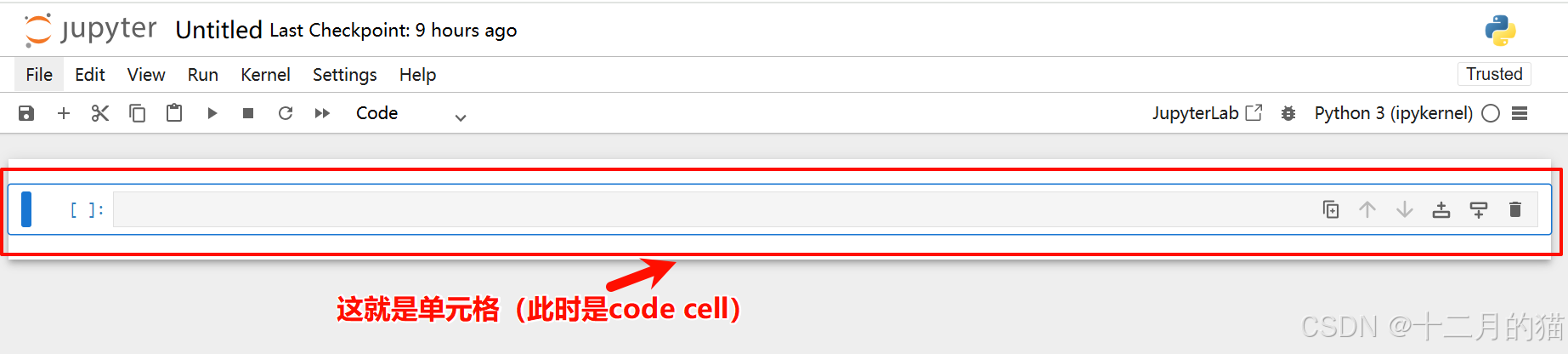
空单元格标记为蓝色(命令行模式)
Markdown 单元格包含格式化文本,并在运行 Markdown 单元格时在同一位置显示其输出。Markdown 单元格可能包含 H1、H2 等标题或任何基本文本格式。因此,您还可以使用笔记本来准备代码文档。它在该用例中非常有用。让我们在代码单元中尝试一个基本的 Python 语句。在示例笔记本文件中键入以下内容,然后单击工具栏中的“运行”按钮。您还可以按 SHIFT+ENTER 或左 CTRL+ENTER 来运行它。
print('hello!')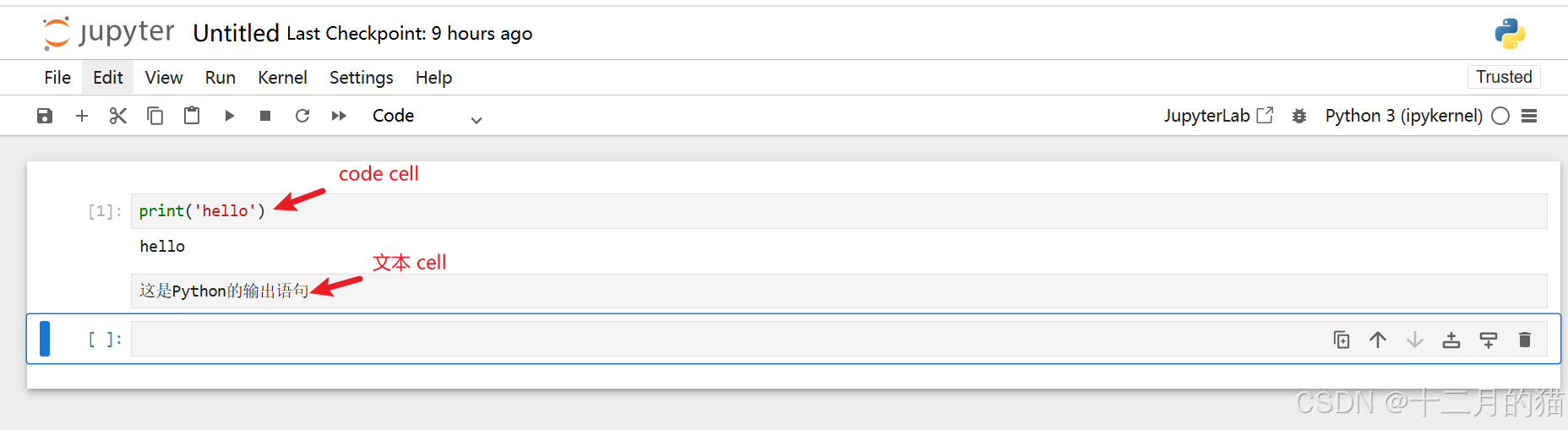
运行它时,可以看到输出将显示在单元格下方,并且标签 [ ] 更改为 [1]:
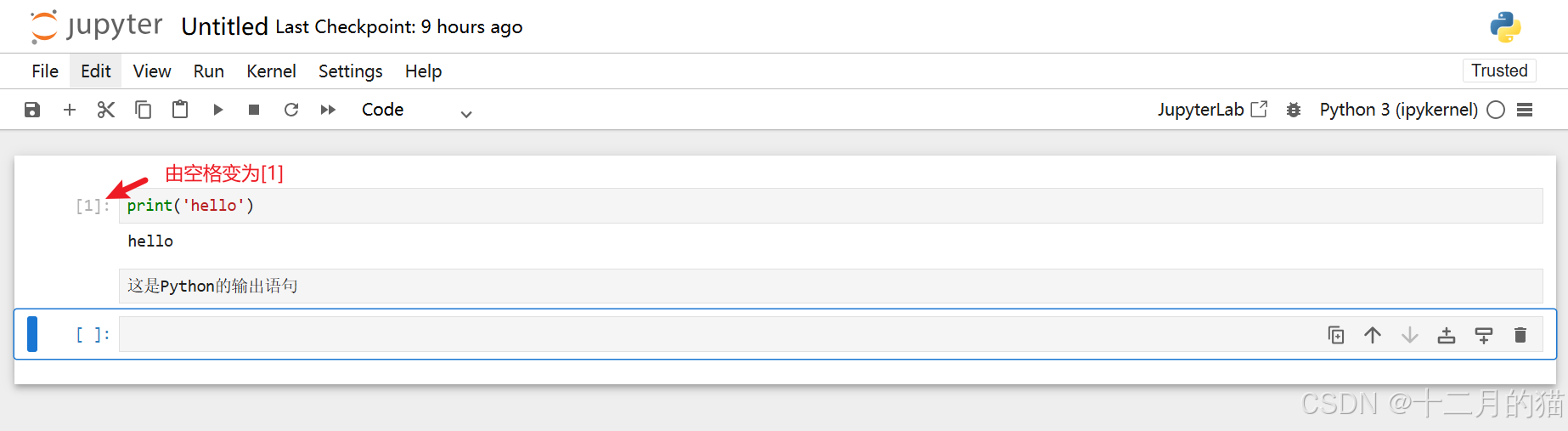
注意点:
- 这里其实省略了ln。完整应该是ln[1]、ln[]。
- 这里“In”表示“输入”,数字表示单元格执行的“时间”。
- 每次执行“时间”+1
当您重新执行代码单元时,输入数字会发生变化。例如,再次在同一个单元格执行运行,则标签改为:[2]
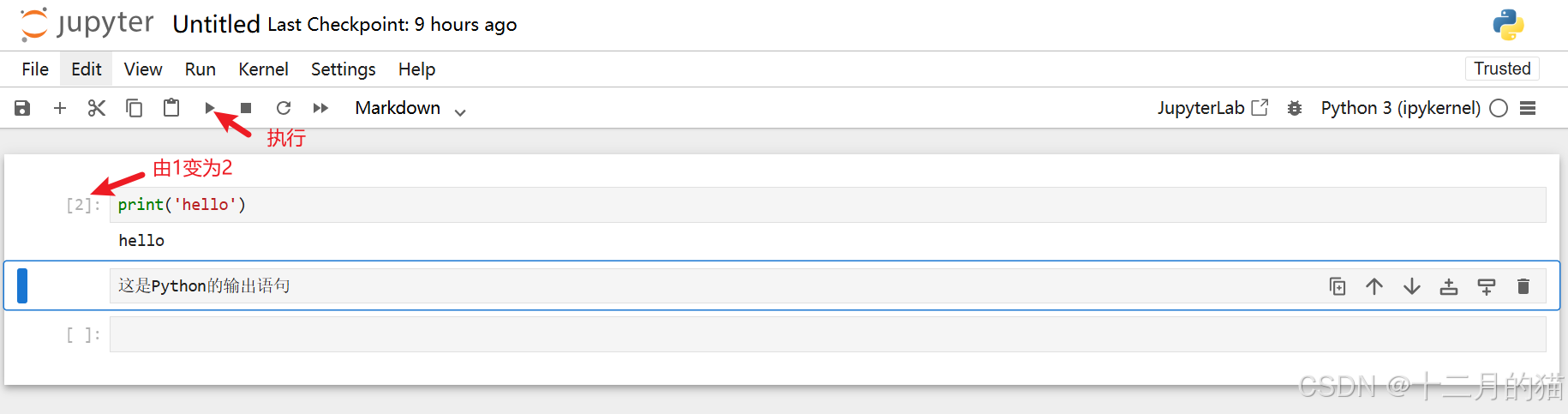
写一个 列表推导式 ,*表示单元格在执行中:
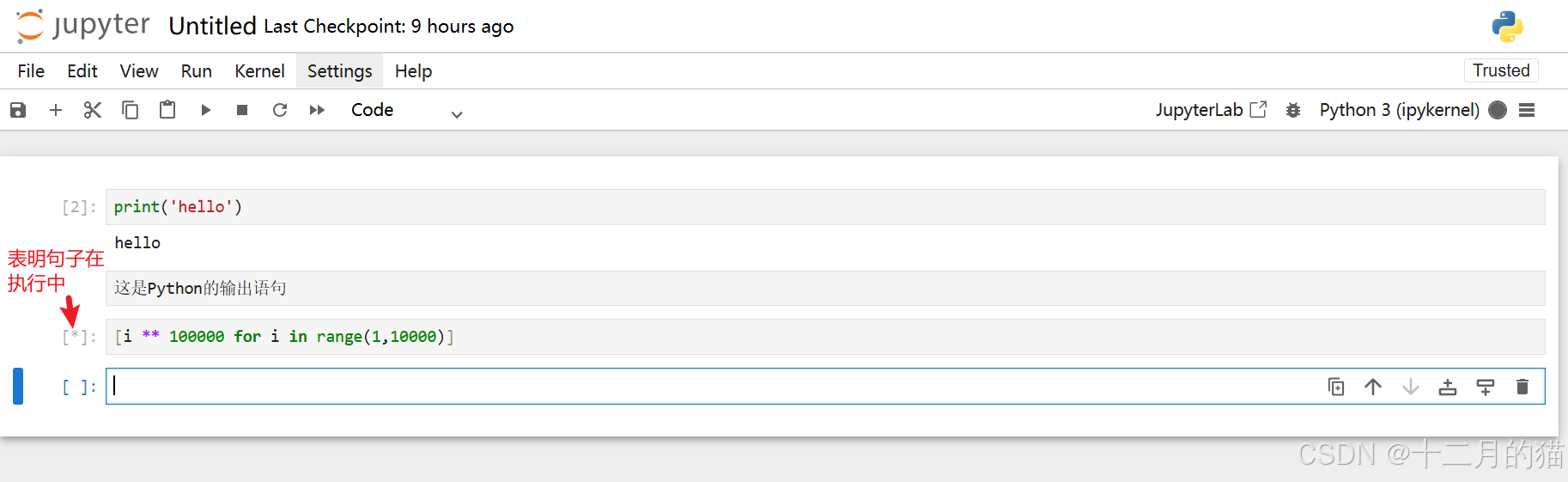
3.3 单元格的模式及模式切换(最新版没有蓝绿之分)
1. 编辑模式(点击Enter进入编辑模式)
单元格旁边是绿色(老版):
单元格仍然是蓝色,出现光标(新版):

2. 命令模式(点击Esc进入命令模式)
单元格旁边是蓝色:

3. 两个模式区别
编辑模式:只能用于编写代码,不能使用一些快捷命令。
命令模式:能够使用一些快捷命令,例如:
-
按下A:向上增加空白的cell
-
按下B:向下增加空白的cell
-
按下D两次(DD):删除该cell
-
按下X:剪贴该cell
-
按下V:粘贴该cell
-
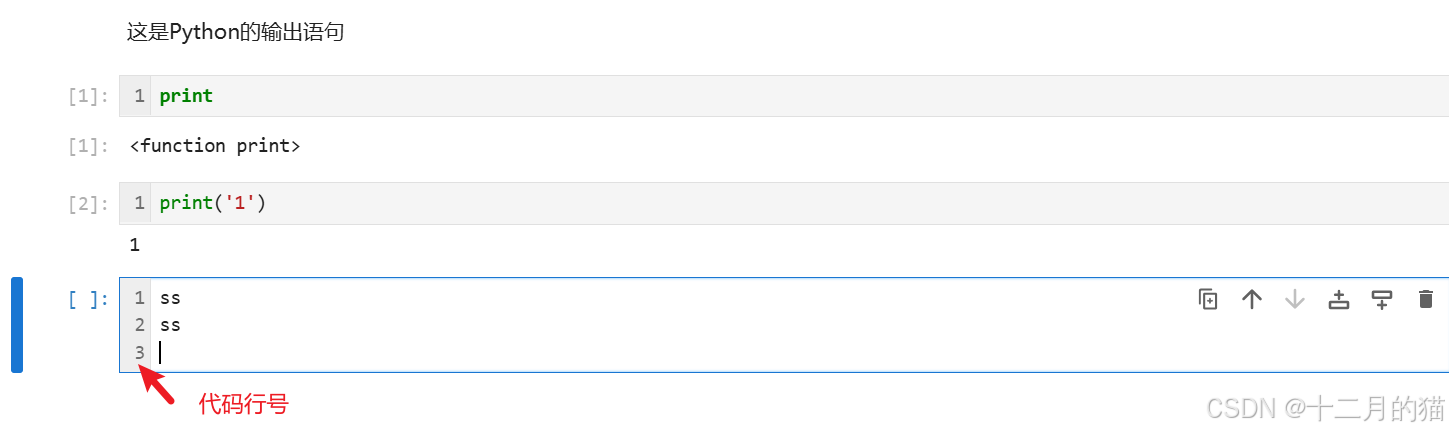
按下shift+L:打开、关闭行号
-
按下M:进入Markdown模式(当进入Markdown模式的时候,cell左边的 In【】会消失掉)
-
按下Y:退出Markdown模式,回到代码编辑模式
3.4 图解笔记本基本操作(必看) 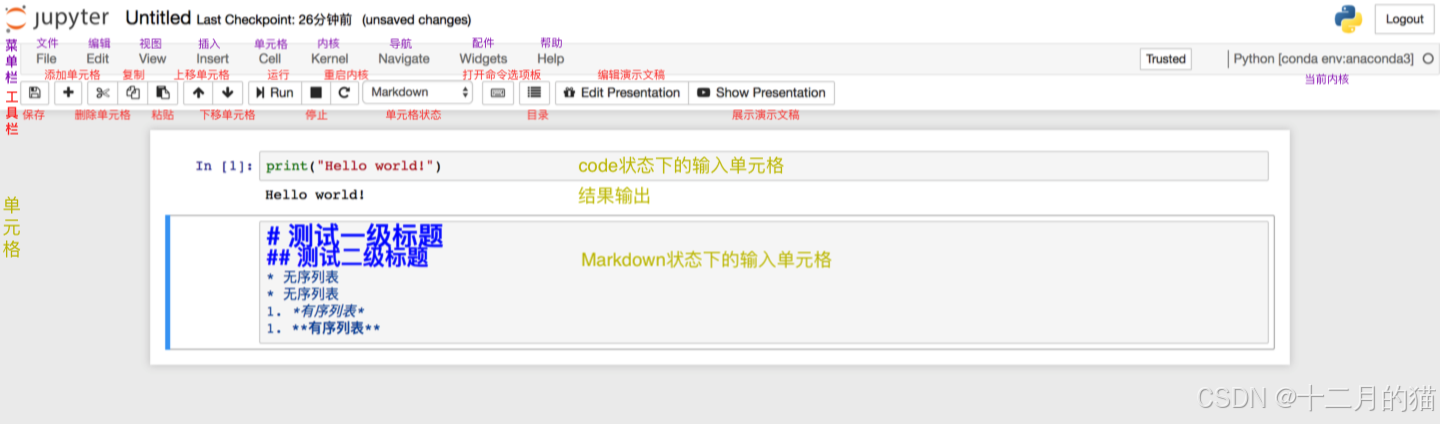
4. 常用Jupyter Notebook 的快捷键
4.1 命令模式(点击单元格非输入区域 或 Esc 开启)
- Enter : 转入编辑模式
- Shift-Enter : 运行本单元,选中下个单元(没有下一个单元则新插入一个)
- Ctrl-Enter : 运行本单元
- Alt-Enter : 运行本单元,在其下插入新单元
- Y : 单元转入代码状态(Markdown模式)
- M :单元转入markdown状态
- R : 单元转入raw状态
- A : 在上方插入新单元
- B : 在下方插入新单元
- X : 剪切选中的单元
- C : 复制选中的单元
- V : 粘贴到下方单元
- Shift-V : 粘贴到上方单元
- Z : 恢复删除的最后一个单元
- D,D : 删除选中的单元
- Shift-M : 合并选中的单元(向下合并一个单元)
- 1 : 设定 1 级标题(Markdown模式)
- 2 : 设定 2 级标题(Markdown模式)
- 3 : 设定 3 级标题(Markdown模式)
- 4 : 设定 4 级标题(Markdown模式)
- 5 : 设定 5 级标题(Markdown模式)
- 6 : 设定 6 级标题(Markdown模式)
4.2 编辑模式(Enter 键 或 点击单元格输入区域 启动)
- Tab : 代码补全或缩进
- Esc:进入命令模式
- Shift-Tab : 提示
- Ctrl-] : 缩进
- Ctrl-[ : 解除缩进
- Ctrl-Home : 跳到单元开头
- Ctrl-Down : 跳到单元末尾
- Ctrl-A : 全选
- Ctrl-Z : 复原
- Shift-Enter : 运行本单元,选中下一单元
- Ctrl-Enter : 运行本单元
- Alt-Enter : 运行本单元,在下面插入一单元
- Ctrl-Shift-Subtract : 分割单元(Subtract 就是键盘上的-)
5. 总结
如果想要学习更多环境配置、软件安装的知识
欢迎订阅:各种软件安装与配置_十二月的猫的博客-CSDN博客
你的点赞就是我更新的动力,如果觉得对你有帮助,辛苦友友点个赞,收个藏呀~~~




















 2915
2915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











