







-
缓存雪崩
-
缓存击穿
-
缓存穿透
相信这三个问题,网上已经有很多的伙伴讲过了,但是今天我还是想说下,会多画图,让大家加深印象,这三个问题也高频的面试题,但是能把这几个问题说清楚,也是需要技巧的。
再说这三个问题的时候,先说下正常的请求流程,看图说话:
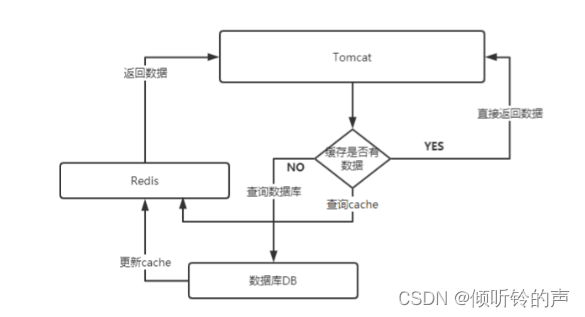
上图的意思大致如下:
首先会在你的代码中,可能是 tomcat 也可以是你的 rpc 服务中,先判断缓存 cache 中是否存在你想要的数据,如果存储了,那么直接返回给调用端,如果不存在,那么就需要查询数据库,查询出结果来,再继续缓存到 cache 中,然后返回结果给调用方,下次再来的查询的时候,也就命中缓存了。
缓存雪崩
定义
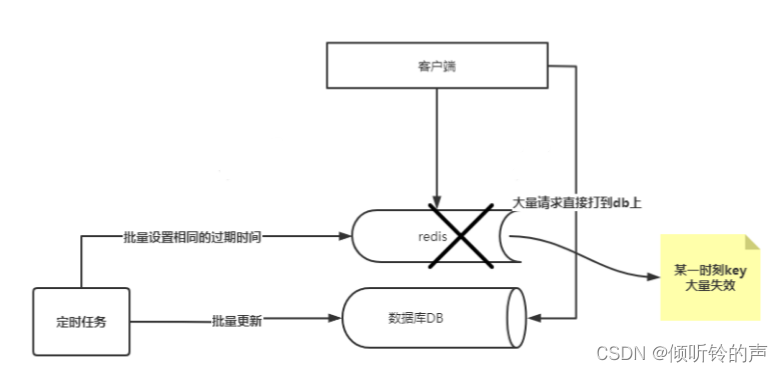
记得之前在做推荐系统的时候,有些数据是离线算法算出来的,需求是看了这个商品会推荐哪些相似的商品,这个算出来之后会存储到 hbase,同时存储到 redis,由于都是批量算法出来的,再存储到 redis 的时候,如果过期时间设置相同,那么就会造成大批量的 key ,在同一时刻失效,那么就会有大批量的请求会被打到后台的数据库上,因为数据库的吞吐量是有限的,很有可能会把数据库打垮的,这种情况就是缓存雪崩,看图说话:
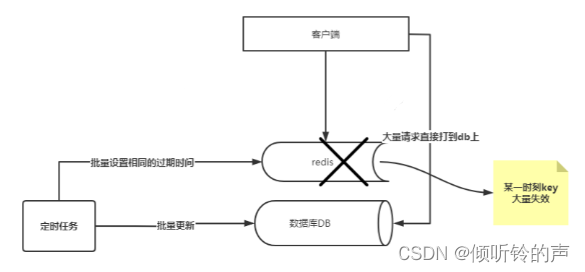
这个主要是说明一个缓存雪崩出现的场景,尤其是定时任务在批量设置 cache 的时候,一定要注意过期时间的设置。
如何预防雪崩
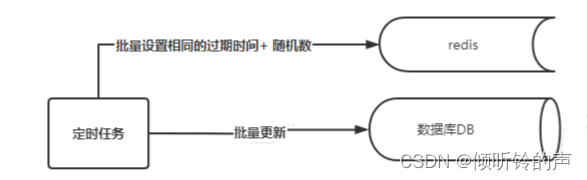
其实也很简单,就是在你批量设置 cache 的缓存时间的时候,给设置的缓存时间,设置一个随机数(如随机数可以 10 分钟内的数字,随机数的生成可以用 java 的 Random 生成),这样,就不会出现大量的 key,再同一时刻集体失效了,看图说话:
如果真的发生了雪崩怎么办?
流量不是很大,数据库能抗住,ok,恭喜你逃过一劫。
流量很大,超过了数据库所能处理的请求数的极限,数据库 down 机了,也恭喜你领了一个 P0 事故单。
流量很大,如果你的数据库有限流方案,当达到了限流设置的参数,那么就会拒绝请求,从而保护了后台 db。这里对限流多说几句。
可以通过设置每秒请求数,来限制大量的请求到达 db 端,注意这里的每秒请求数,或者说是并发数,并不是数据当前的每秒请求数,可以设置为查询某个 key 对应的每秒请求数量,这样做的目的,是防止大量相同 key 的请求到达后端数据库,这样就能拦截了大部分请求了。
看图说话:
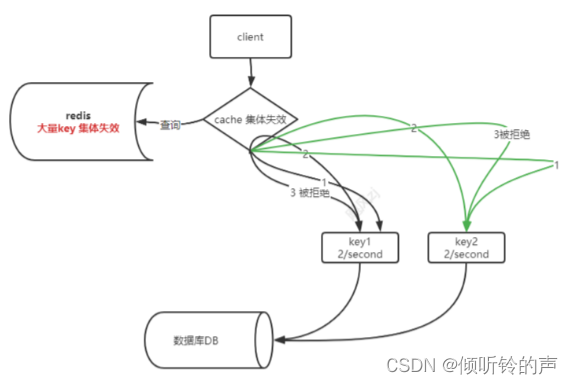
这样相同的 key,就会被限流了大部分请求,从而保护了数据库 db。
其实限流还分为本地限流和分布式限流两种,后面的文章里,我会 介绍本地限流和 redis 实现的分布式限流。
缓存击穿
定义
比如在某网站在进行双十一或者在搞秒杀等运营活动的时候,那么此时网站流量一般都会很大的,某个一个商品因为促销会成为爆品,流量超级的大,如果这个商品,在这个时候,由于某种原因,在 cache 内失效了,那么就瞬间这个 key 的流量都会涌向数据库了,那么 db 最终挺不住了,down 了,后果可想而知啊,正常其他的数据也查询不了。
看图说话:
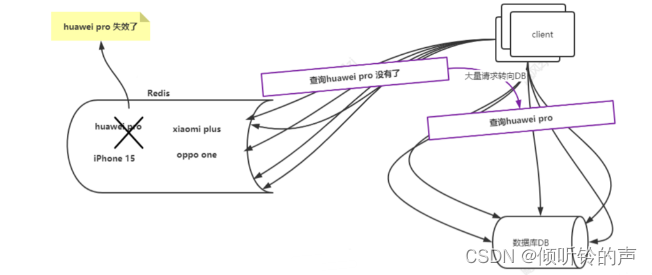
redis 中的 huawei pro 这个 key 突然失效了,可能是到期了,可能是内存不够被淘汰了,那么就会有大流量的请求到达 redis ,发现 redis 没有这个 key,那么这些流量,就会转到 DB 上去,查询对应的 huawei pro,此时 DB 挺不住了,down 了。
如何解决
其实归根到底还是不能让更多的流量到达 DB 就行了,所以我们就是要限制到达 db 的流量就可以了。
1、限流
和上面说的类似,主要是限制某个 key 的流量,当这个 key ,被击穿后,限制只有一个流量进入到 db,其他都被拒绝,或者等待重试查询 redis。
限流的图可以参考缓存击穿限流的图。
这里也会分本地限流和分布式限流 。
何为本地限流,就是在本地单个实例范围内,限制这个 key 的流量多少,只对当前实例有效。何为分布式限流呢,就是在分布式的环境下,多个实例的范围内,这个 key 的限制流量的累加是来自多个实例的流量,达到限制,所有的实例都会限制流量到达 DB。
2、利用分布式锁
这里简单说下分布式锁的定义,在并发场景下,需要使用锁对共享资源互斥访问来保证线程安全;同样,在分布式场景下,也需要一种机制来保证对多节点共享资源的互斥访问,实现机制就是分布式锁。
在这里共享资源就是例子中的 huawei pro,也就是在访问 db 中的 huawei pro 的时候,要保证只有一个线程或者一个流量去访问,就达到了分布式锁的效果。
看图说话:
去抢锁:
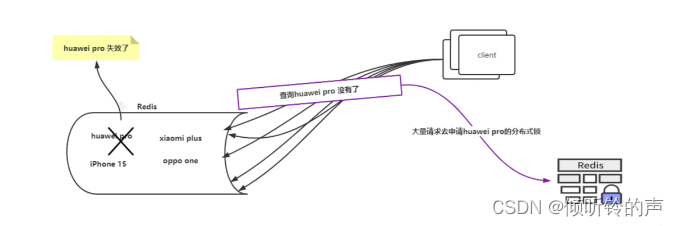
大量请求在没有获取到 huawei pro 这个 key 的值后,准备去 db 获取数据,此时获取 db 的代码加了分布式锁,那么每个请求,也是每个线程都会去获取 huawei pro 的分布式锁(图中利用 redis 实现了分布式锁,后面我会有单独一篇文章来介绍分布式锁的实现,不限于 redis)。
获取锁之后:
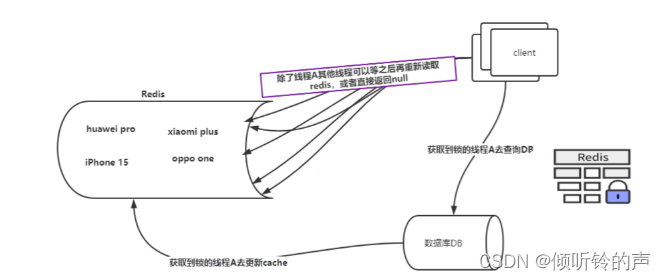
此时线程 A 获取了 huawei pro 的分布式锁,那么线程 A 就会去 DB 加载数据,然后由线程 A 将 huawei pro 再次设置到 cache 内,然后返回数据。
其他的线程就没有获取到,一种方式就是直接返回空值给客户端,还有一种等待 50-100ms ,因为查询 db 和放入 redis 会很快,此时等待,再次查询的时候,结果可能就有了,如果没有就直接返回 null,当然也可以重试,当然在大并发的场景下,还是希望能够快速的返回结果,不能发生太多次数的重试操作。
3、定时任务更新热点 key
这个就很好理解,说白了,就是一个定时任务定时地去监控某些热点 key 的超时时间,是否到期,再进行快到期了的时候延长 key 在 cache 中的缓存时间就可以了。
单个线程轮询的方式检查和更新失效时间,看图:
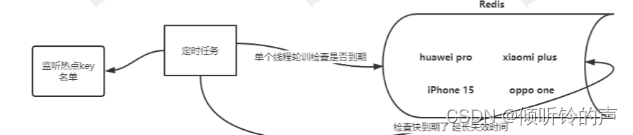
多线程的方式,注意热点的 key 不能太多,某个线程会开启很多,如果热点 key 很多,可以采用线程池的方式,看图:
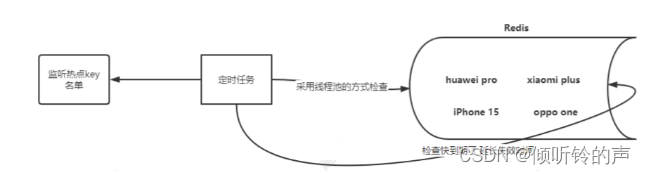
延迟队列实现
上面的方式说白了,无论是单个线程还是多个线程,都是会采用轮询的方式(每次白白浪费的 cpu),来检查是否 key 快到期了,这种方式检查会存在检查时间不准确,可能会造成时间的延迟或者不准确,你在等待进行下次检查的时候,这个 key 就没了,那么此时就已经发了击穿,这个情况的发生虽然概率低,但也是有的,那么我们怎么才能避免呢,其实咱们可以利用延迟队列(环形队列来实现,这里我不深入讲这个队列的原理了,大家可以自行百度或者 google),所谓的延迟队列就是你往这个队列发送消息,希望按照你设置的时间来进行消费,时间没到不会进行消费,时间到了就进行消费,好了,看图说话吧:
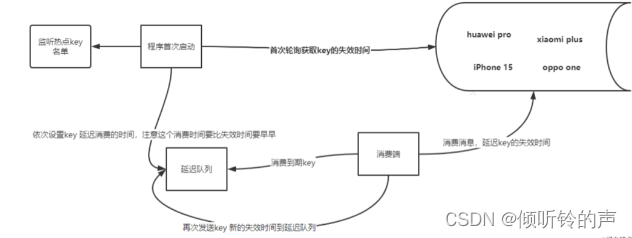
1、程序首次启动 获取名单内 key 的失效时间。2、依次设置 key 延迟消费的时间,注意这个消费时间要比失效时间要早。3、延迟队列到期,消费端进行消费 key。4、消费端消费消息,延迟 key 的失效时间到 cache。5、再次发送 key 新的失效时间到延迟队列,等待下次延迟 cache 的失效时间。
4、设置 key 不失效
这种其实也可能会因为内存不足,key 被淘汰,大家可以想想什么情况下,key 会被淘汰。
缓存穿透
定义
所谓穿透,就是访问了一个 cache 不存在,数据库里也不存在的 key,那么此时相当于流量直接到达了 DB 了,那么一些流氓就可以利用这个漏洞,疯狂地刷你的接口,进而把你的 DB 打垮,你的业务也就不能正常运行了。
如何解决呢?
1、设置 null 或者特殊值
我们可以通过设置 null 或者特定的值到 redis 内,且不过期,那么下次再来的时候,直接从 redis 获取这个 null 或者 特殊值就可以了。
这个方案不能解决根本性的问题,如果这个流量能仿造出大量的无用 key,你设置再多的 null 或者特殊的值都是没有用的,那么我们应该怎么解决呢?
2、布隆过滤器
布隆过滤器 英文为 bloomfiler,这里我们只是做简单的介绍,介于篇幅的原因,后面会有单独的文章做介绍。举个例子,如果我们数据库里存储着千万级别的 sku 数据,我们现在的需求是如果库有这个 sku,那么就查询 redis ,如果 redis 没有就查询数据库,然后更新 redis,我们最先想到的就是把 sku 数据放入到一 hashmap 内,key 就是 sku,因为 sku 的数量很多,那么这个 hashmap 占用的内存空间会很大,有可能会撑爆内存,最后得不偿失了,那么怎么来节省内存,我们可以利用一个 bit 的数组,来存储这个 sku 是否存在状态,0 代表不存在,1 代表存在,我们可以利用一个散列函数,算出 sku 的散列值,然后 sku 的散列值对 bit 数组进行取模,找到所在数组的位置,然后设置为 1,当请求来的时候,我们会算出这个 sku 散列值对应的数组位置是否为 1 ,为 1 说明就存在,为 0 说明就不存在。这样一个简单的 bloomfilter 就实现了,bloomfiler 是有错误率,可以考虑增加数组长度和散列函数的数量来提供准确率,具体可以百度或者 google,今天在这里就不讲了。
下面看看利用 bloomfiler 来防止缓存穿透的流程,看图说话:
bloomfiler 的初始化 可以通过一个定时任务来读取 db,初始化 bit 数组的大小,默认值都是为 0,表示不存在,然后每条都计算散列值对应的数组位置,然后插入到 bit 数组中。

请求流程,看图:
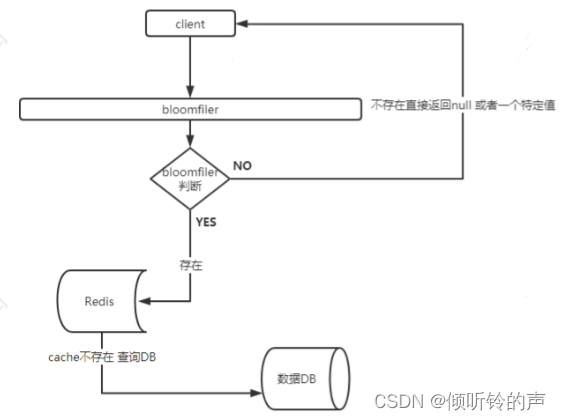
如果不利用 bloomfiler 过滤器,对于一个数据库里根本不存在的 key,其实白白浪费了两次 IO,一次查询 redis,一次查询 DB,有了 bloomfiler ,那么就节省了这两次无用的 IO,减少后端 redis 和 DB 资源的浪费。
总结
今天我们聊了 redis 缓存 的高频的面试和实战中遇到的问题以及解决方案。
-
缓存雪崩
解决方案:
-
在设置失效时间段的时候,加上一个时间的随机数,可以几分钟之内的都可以。
-
以及如果真的雪崩了怎么办的问题,可以采用限流的方式。
-
缓存击穿
解决方案:
-
限流
-
分布式锁
-
定时更新热点 key ,这里重点看下延迟队列。
-
设置时间不失效
-
缓存穿透
解决方案:
-
设置 null 或者特定的值到 redis
-
使用 bloomfiler 实现
今天的分享就到这里了,码字画图不易,期待你的点赞、关注、转发,谢谢。
















 837
837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











