






文章目录
一、提出任务
- 单词计数是学习分布式计算的入门程序,有很多种实现方式,例如MapReduce;使用Spark提供的RDD算子可以更加轻松地实现单词计数。
- 在IntelliJ IDEA中新建Maven管理的Spark项目,并在该项目中使用Scala语言编写Spark的WordCount程序,最后将项目打包提交到Spark集群(Standalone模式)中运行。
- 预备工作:启动集群的HDFS与Spark
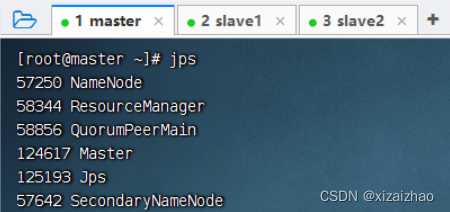
- HDFS上的单词文件 - words.txt
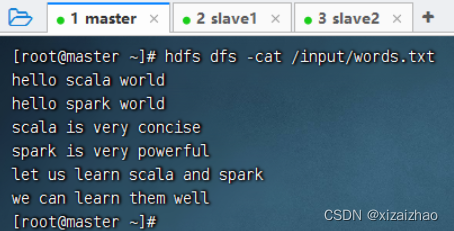
二、完成任务
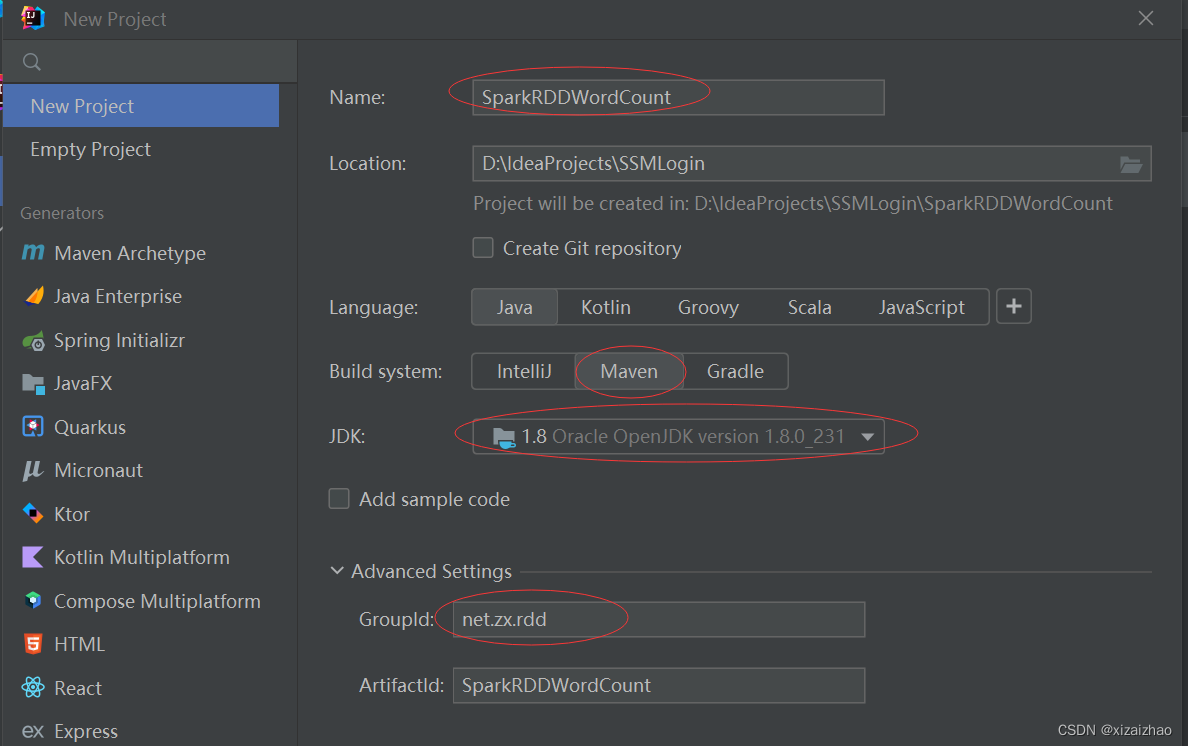
(一)新建Maven项目
-
新建Maven项目,基于JDK1.8
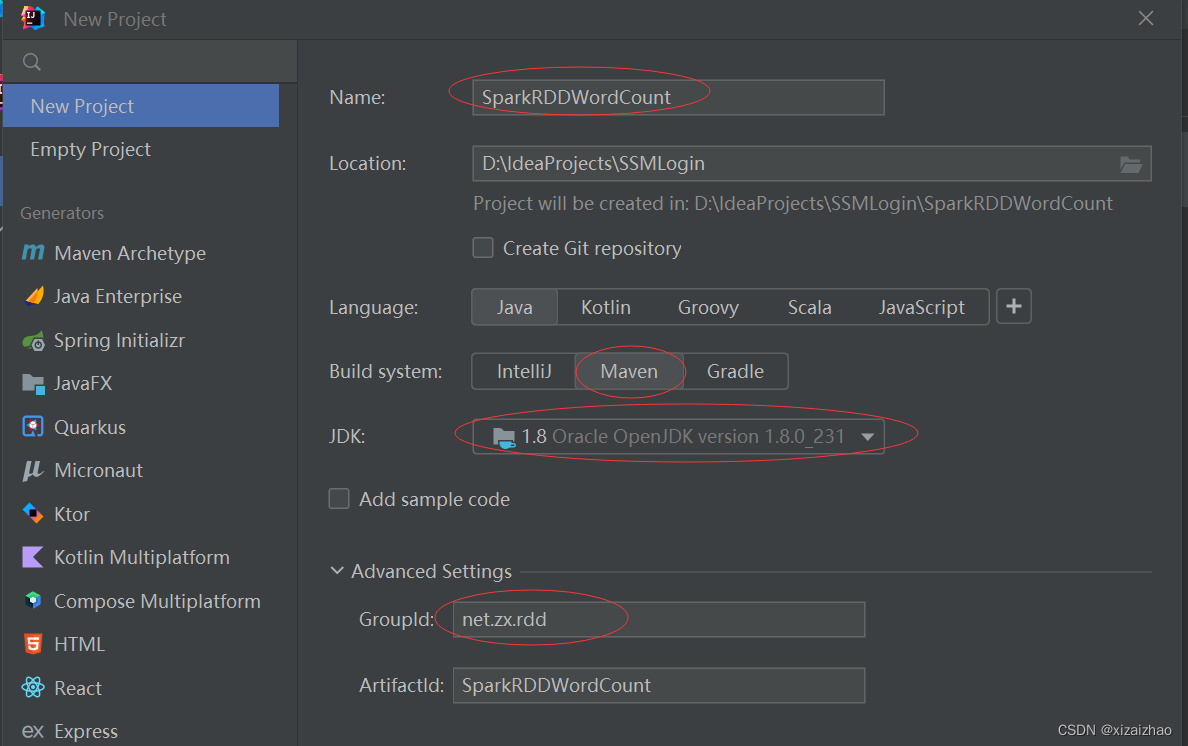
-
设置项目信息(项目名称、保存位置、组编号以及项目编号)
-
单击【Finish】按钮
-
将java目录改成scala目录
(二)添加相关依赖和构建插件
- 在pom.xml文件里添加依赖与Maven构建插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.zx.rdd</groupId>
<artifactId>SparkRDDWordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.15</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 由于源程序目录改成了scala,在元素里必须添加子元素,指定目录src/main/scala
(三)创建日志属性文件
- 在资源文件夹里创建日指数型文件 - log4j.properties
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
(四)创建词频统计单例对象
- 在net.huawei.rdd包里创建WordCount单例对象
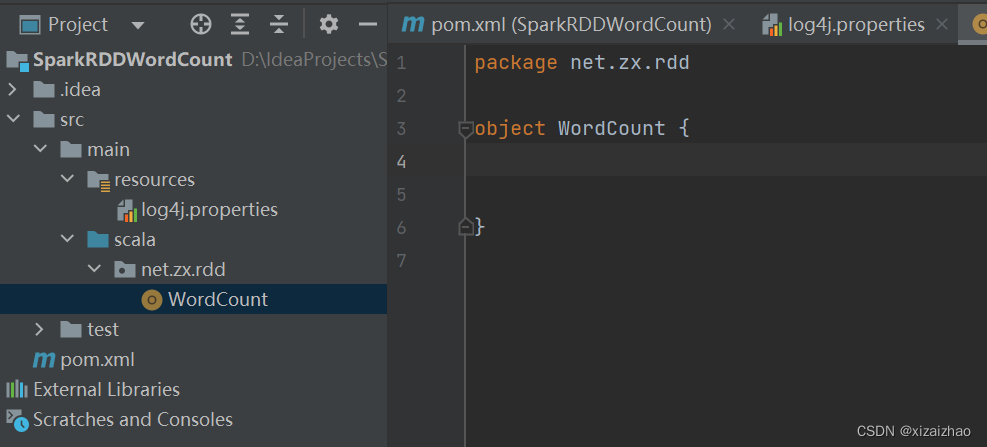
package net.zx.rdd
import org.apache.spark.{SparkConf, SparkContext}
/**
* 功能:利用RDD实现词频统计
* 作者:xizaizhao
* 日期:2022年06月14日
*/
object WordCount {
def main(args: Array[String]): Unit = {
// 设置系统属性HADOOP_USER_NAME为root用户,否则对HDFS没有写权限
System.setProperty("HADOOP_USER_NAME", "root")
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("SparkRDDWordCount") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(目前本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf);
// 判断命令行参数个数
var inputPath = "";
var outputPath = "";
if (args.length == 0) {
inputPath = "hdfs://master:9000/input/words.txt";
outputPath = "hdfs://master:9000/wc_result";
} else if (args.length == 1) {
inputPath = args(0); // 用户指定
outputPath = "hdfs://master:9000/wc_result";
} else if (args.length == 2) {
inputPath = args(0); // 用户指定
outputPath = args(1); // 用户指定
} else {
println("温馨提示:参数不能多于两个~")
inputPath = args(0); // 用户指定
outputPath = args(1); // 用户指定
}
// 进行词频统计
val wc = sc.textFile(inputPath) // 读取文件,得到RDD
.flatMap(_.split(" ")) // 扁平化映射,得到单词数组
.map((_, 1)) // 针对每个单词得到二元组(word, 1)
.reduceByKey(_ + _) // 按键进行聚合(key相同,value就累加)
.sortBy(_._2, false) // 按照单词个数降序排列
// 输出词频统计统计
wc.collect.foreach(println)
// 词频统计结果保存到指定位置
wc.saveAsTextFile(outputPath);
// 停止Spark容器,结束任务
sc.stop()
}
}
(五)本地运行程序,查看结果
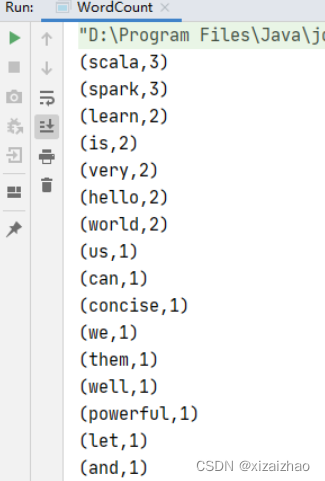
-
首先看控制台输出结果
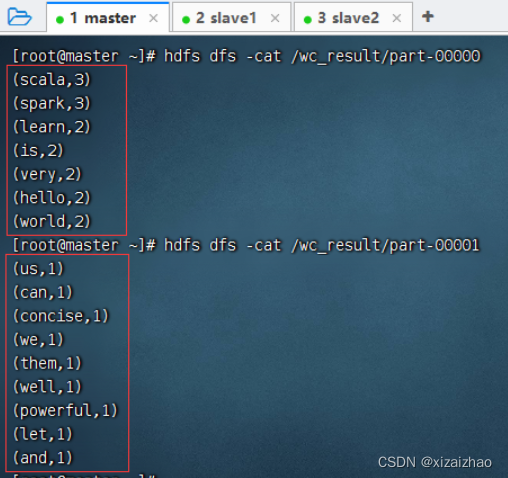
-
然后查看HDFS上的结果文件内容

-
有两个结果文件,我们可以分别查看其内容
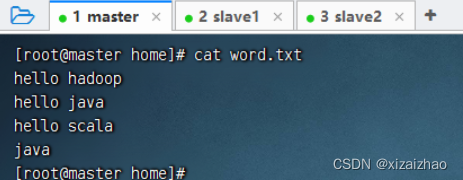
-
创建文本文件 - word.txt
-
上传到HDFS的/input目录
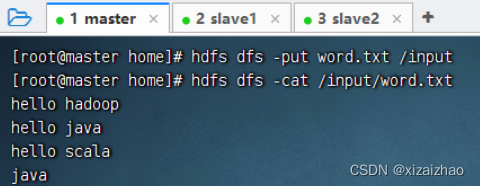
-
给程序设置命令行参数(注意两个参数之间必须有空格)
-
运行程序,查看控制台输出结果
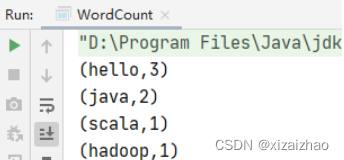
-
查看HDFS上的结果文件内容

(六)对于程序代码进行解析
SparkConf对象的setMaster()方法用于设置Spark应用程序提交的URL地址。若是Standalone集群模式,则指Master节点的访问地址;若是本地(单机)模式,则需要将地址改为local或local[N]或local[*],分别指使用1个、N个和多个CPU核心数。本地模式可以直接在IDE中运行程序,不需要Spark集群。
-
此处也可不设置。若将其省略,则使用spark-submit提交该程序到集群时必须使用–master参数进行指定。
-
SparkContext对象用于初始化Spark应用程序运行所需要的核心组件,是整个Spark应用程序中很重要的一个对象。启动Spark Shell后默认创建的名为sc的对象即为该对象。
-
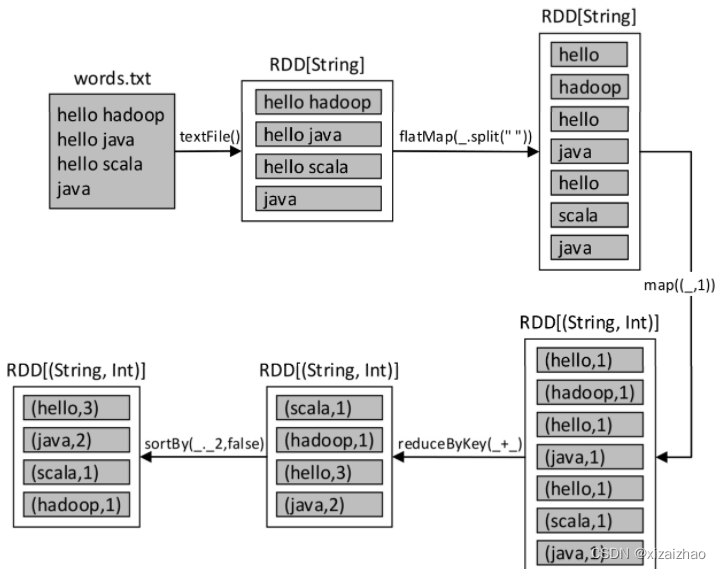
textFile()方法需要传入数据来源的路径。数据来源可以是外部的数据源(HDFS、S3等),也可以是本地文件系统(Windows或Linux系统),路径可以使用以下3种方式:
(1)**文件路径:**例如textFile(“/input/data.txt “),此时将只读取指定的文件。
(2)**目录路径:**例如textFile(”/input/words/”),此时将读取指定目录words下的所有文件,不包括子目录。
(3)**路径包含通配符:**例如textFile(“/input/words/*.txt”),此时将读取words目录下的所有TXT文件。 -
该方法将读取的文件中的内容按行进行拆分并组成一个RDD集合。假设读取的文件为words.txt,则上述代码的具体数据转化流程如下图所示。
(七)将Spark项目编译和打包
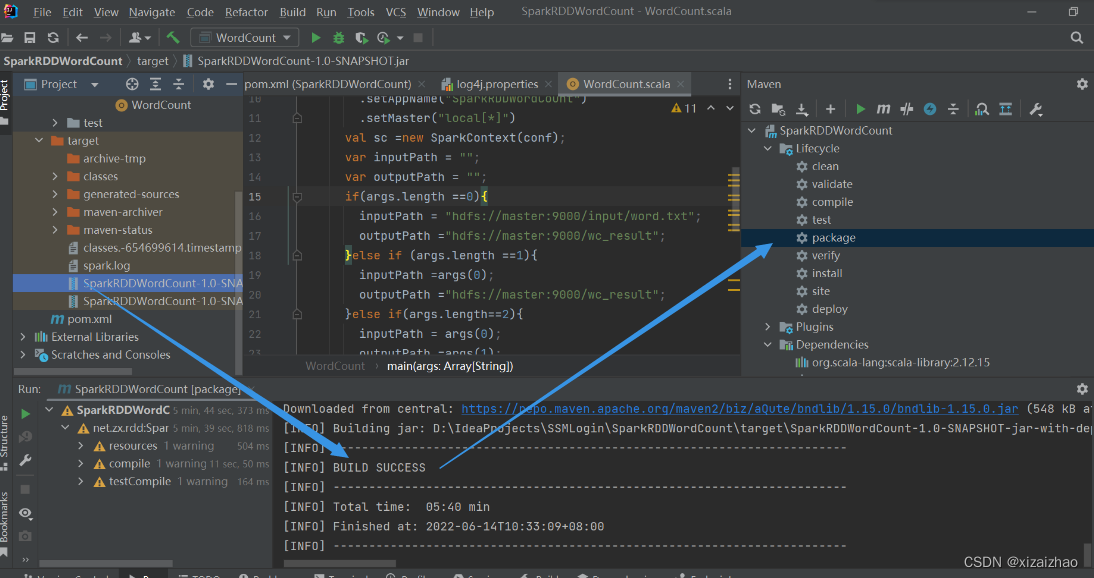
-
展开IDEA右侧的Maven窗口,双击其中的package项,将编写好的SparkRDDWordCount项目进行编译和打包
-
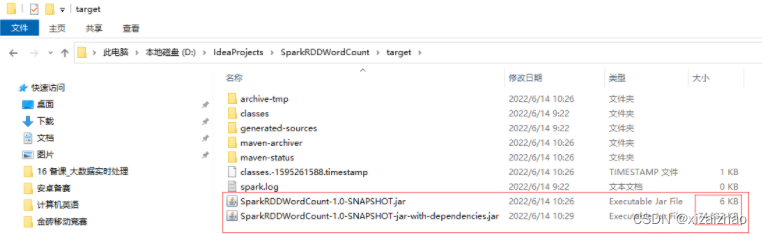
在target目录里生成了两个jar包,一个没有带依赖,一个带了依赖,我们使用没有带依赖的jar包 -
SparkRDDWordCount-1.0-SNAPSHOT.jar
(八)将词频统计应用上传到虚拟机
-
在master虚拟机上新建目录/app

-
将SparkRDDWordCount-1.0-SNAPSHOT.jar上传到master虚拟机/app目录

(九)在集群上执行词频统计应用
- 先把HDFS上存放结果文件的目录/wc_result删除

1、提交应用程序到集群中运行
(1)不带参数运行程序
-
执行命令:spark-submit --master spark://master:7077 --class
net.huawei.rdd.WordCount SparkRDDWordCount-1.0-SNAPSHOT.jar

-
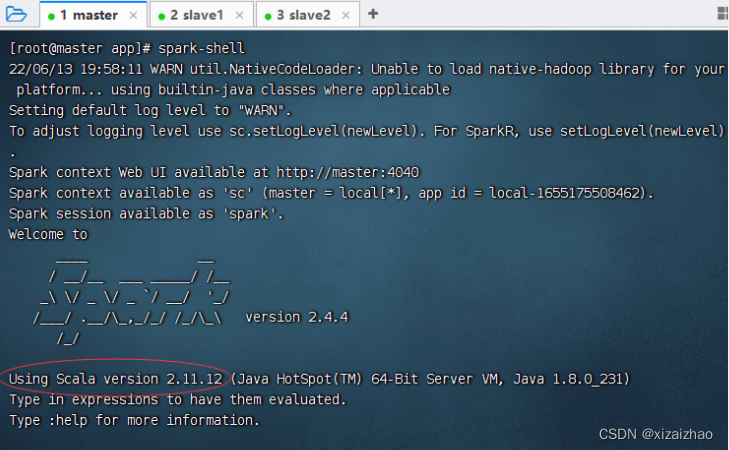
运行报错

-
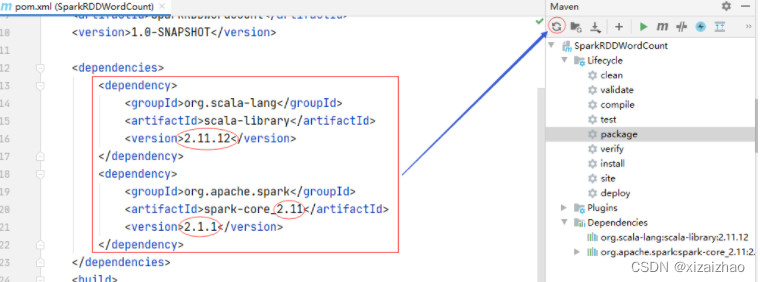
原因是Maven项目里依赖的Scala版本问题
-
在pom.xml文件里修改Scala依赖的版本以及Spark依赖的版本
-
在项目结构对话框里修改scala-sdk的版本

-
再次本地运行,看能否得到结果
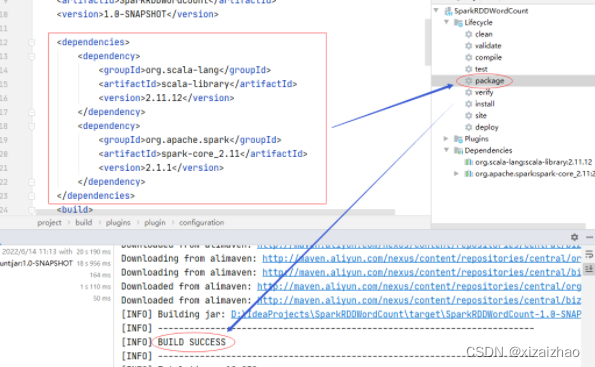
-
从新打包
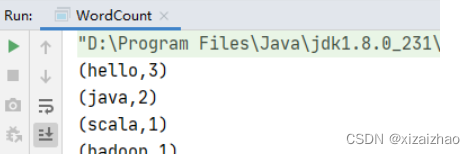
-
再次上传jar包 - SparkRDDWordCount-1.0-SNAPSHOT.jar
-
提交到Spark集群上运行

-
可以查看到输出结果
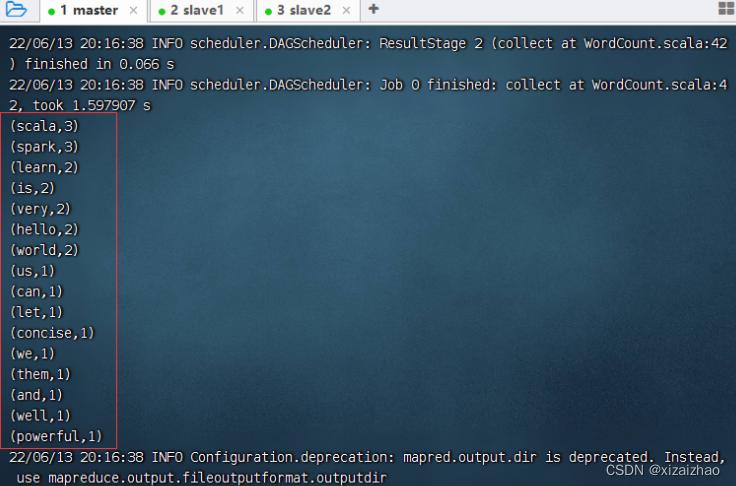
-
还可以查看HDFS的结果文件
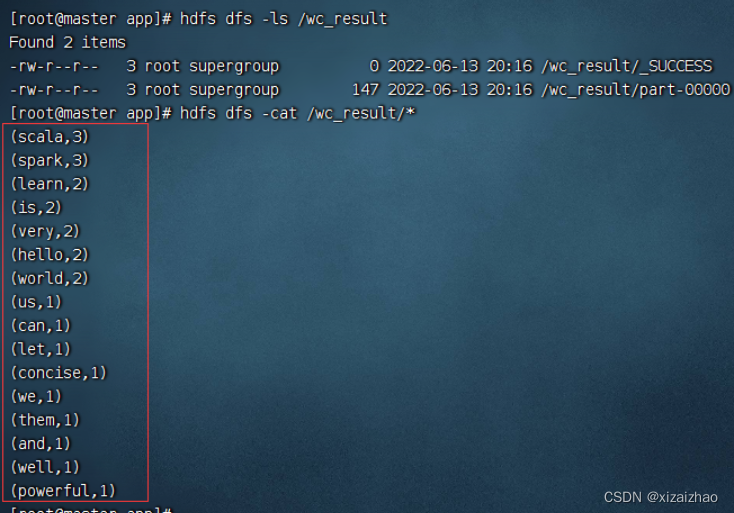
带参数运行程序 -
执行命令:spark-submit --master spark://master:7077 --class
net.huawei.rdd.WordCount SparkRDDWordCount-1.0-SNAPSHOT.jar
hdfs://master:9000/input/word.txt hdfs://master:9000/word_result
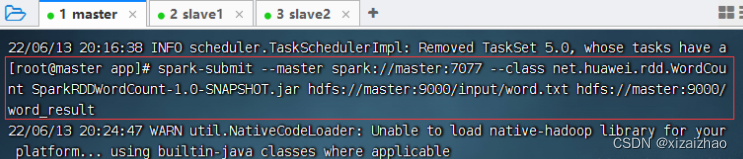
-
查看输出结果
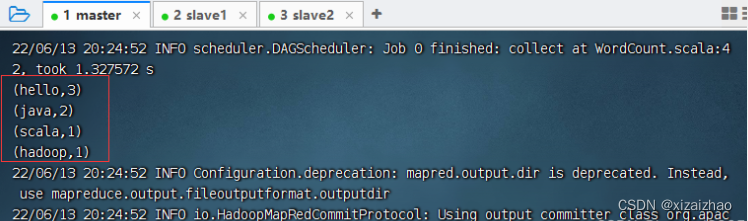
-
还可以查看HDFS上结果文件
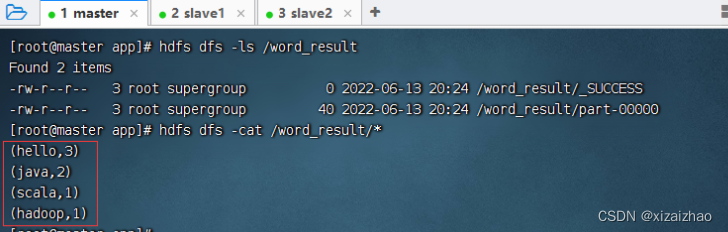
一、pandas是什么?
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、使用步骤
1.引入库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context














 7623
7623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









