






参考资料:
LLaMA-Factory的github下data目录的Readme文件
LLaMA-Factory/data/README_zh.md at main · hiyouga/LLaMA-Factory (github.com)
数据集:
1、截图自官方界面

2、LLaMA-Factory一共支持两种数据集格式
(1)Alpaca
令监督微调数据集
在指令监督微调时,instruction 列对应的内容会与 input 列对应的内容拼接后作为人类指令,即人类指令为 instruction\ninput。而 output 列对应的内容为模型回答。
如果指定,system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
(2)Sharegpt 格式
指令监督微调数据集
相比 alpaca 格式的数据集,sharegpt 格式支持更多的角色种类,例如 human、gpt、observation、function 等等。它们构成一个对象列表呈现在 conversations 列中。
注意其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置。
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "function_call",
"value": "工具参数"
},
{
"from": "observation",
"value": "工具结果"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}
数据集转换
(1)原始数据集部分截图

(2)使用python脚本转换为Alpaca格式(两种)
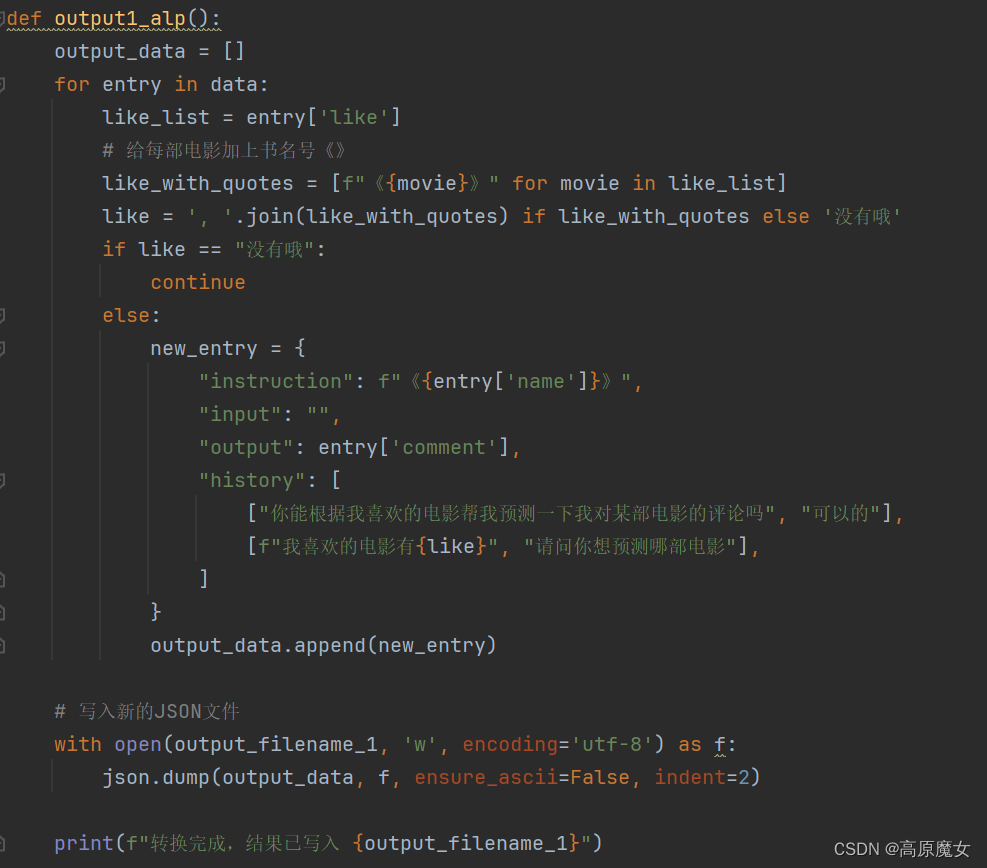
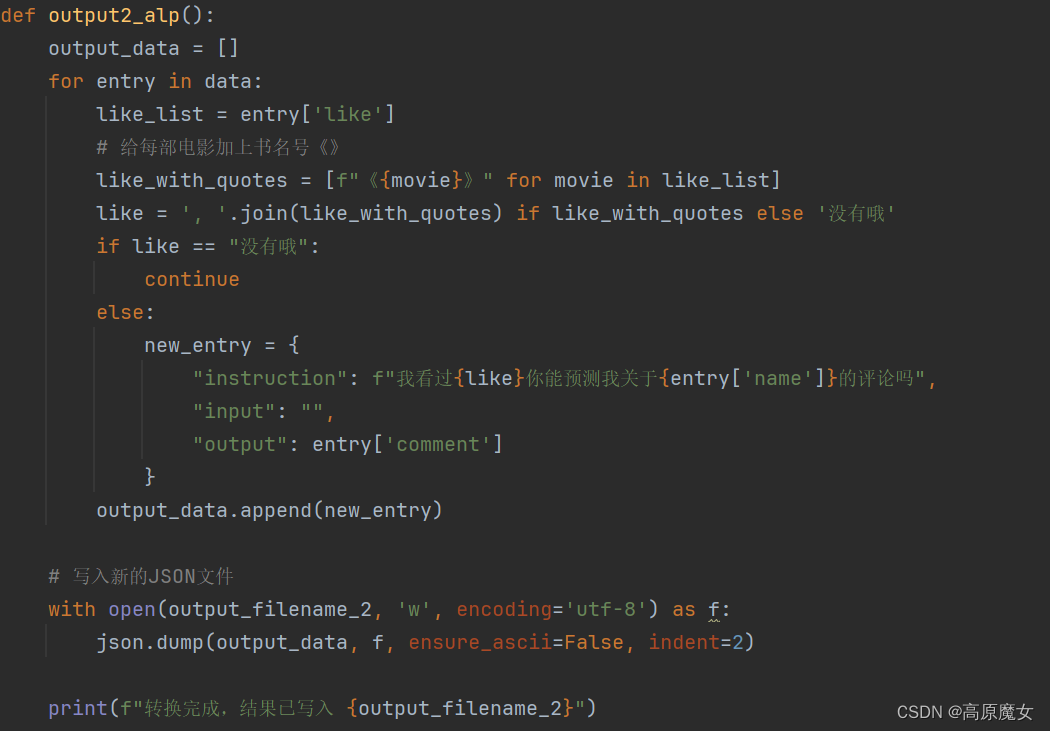
(3)转换后数据集部分示例
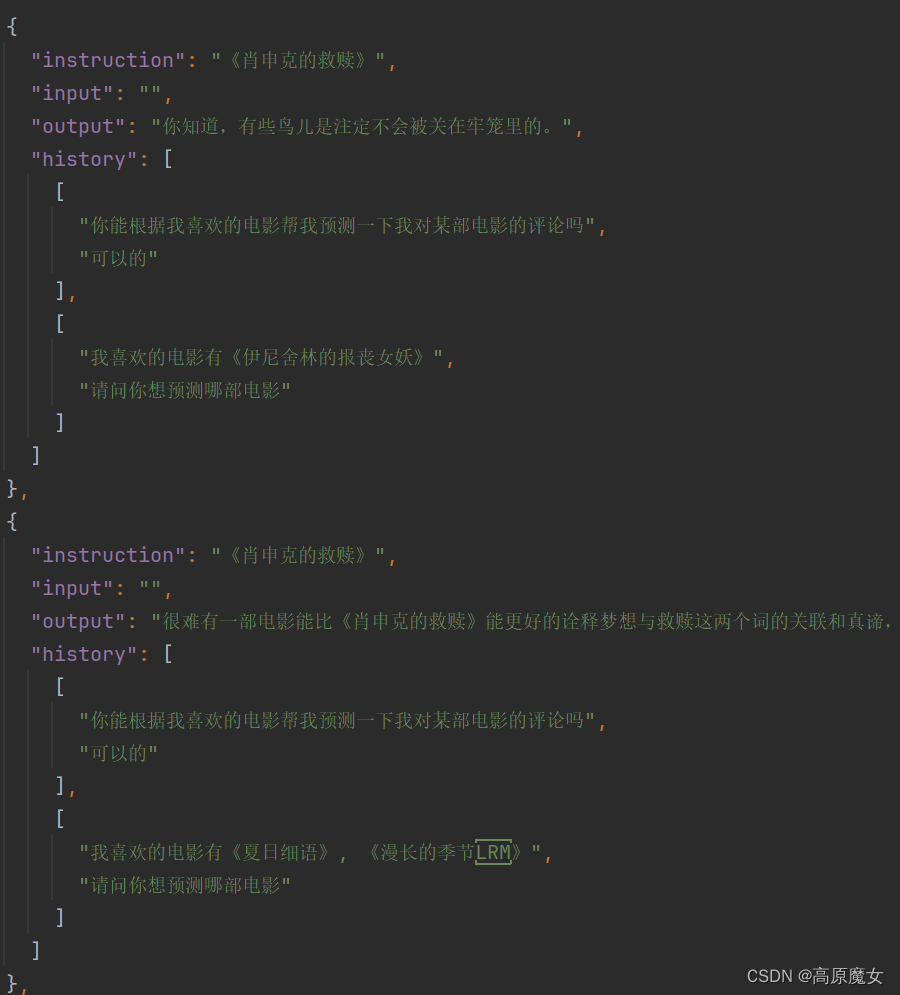



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









