






七 .神经学习
神经学习是一种基于人工神经网络的学习方法。神经学习主要是神经网络的训练过程,其主要表现为联结权值的调整。本节主要讨论感知器学习、BP网络学习和Hopfield学习。
1.感知器学习
感知器模型是由美国学者F. Rossenblatt于1957年提出的一种早期的神经网络模型,其第一次引入了学习的概念,可以用基于符号处理的数学方法来模拟人脑所具备的学习功能。根据网络中所拥有的网络节点的层数,将其分为单层感知器和多层感知器。本节主要讨论单层感知器的学习模型。
·单层感知器学习算法思想:
单层感知器学习基于迭代的思想,通常采用误差校正学习规则的学习算法,其主要思想是利用神经网络的期望输出与实际输出之间的偏差作为联结权值和阈值调整的参考。
2.反向传播网络学习
反向传播网络(Back Propagation Network,简称BP\网络)学习算法也称误差反向传播算法,是由Rumelhart和Meclelland于1985年提出的,实现了明斯基的多层网络设想,解决了前馈神经网络的学习问题,即自动调整网络全部权值问题。
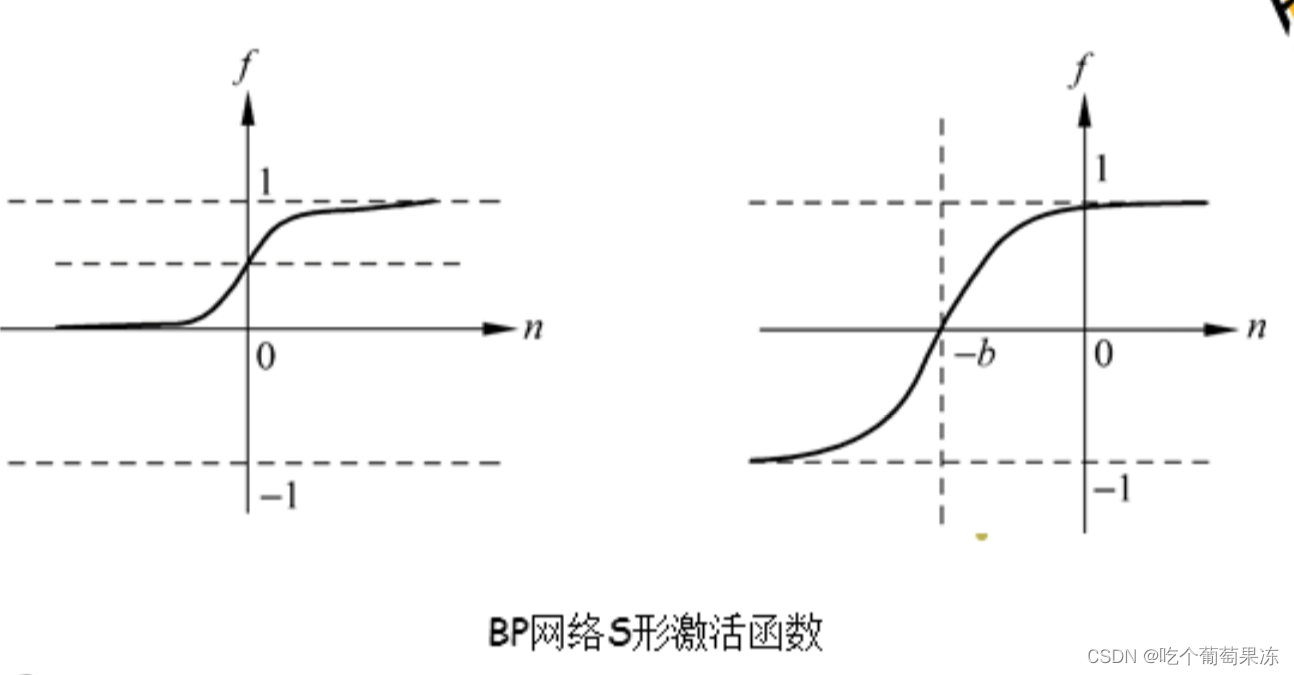
BP网络是将W-H学习规则一般化,对非线性可微分函数进行权值训练的多层网络。BP网络是一种多层前向神经网络,其神经元的变换函数是S型函数,因此输出量为O到1之间的连续量,它可以实现从输入到输出的任意非线性映射。
由于其权值的调整采用反向传播的学习算法,因此称为反向传播网络。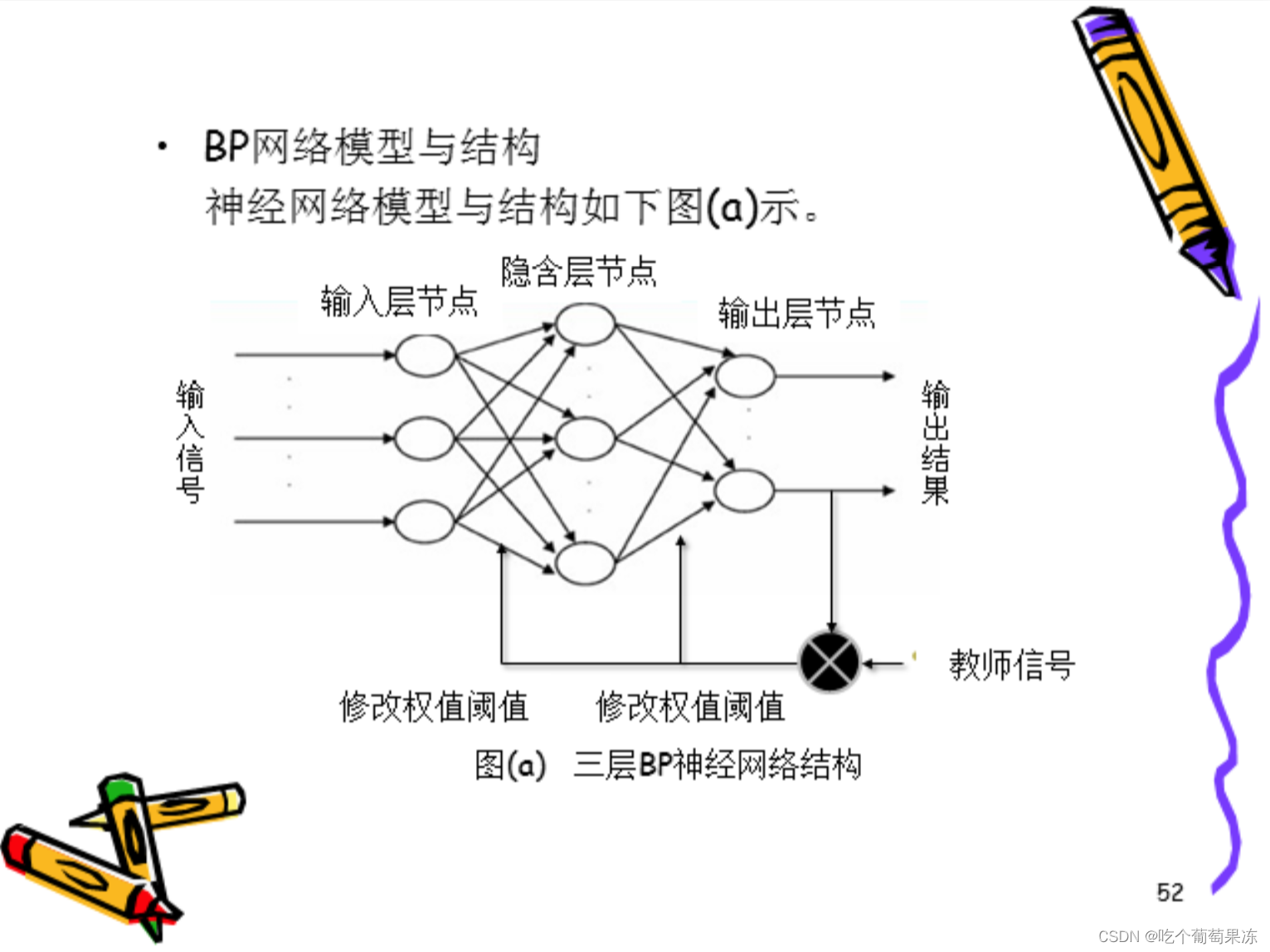
.BP学习规则
BP算法属于é算法,是一种监督式算法。主要由两部分组成:信号的正向传播与误差的反向传播。
正向传播时,
输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。误差反传是将
杉侈梦
种形孙一.从而获得合后据这种信号止进行的。权的所有单元,从而获得各层单元的误差信号
即作为修正各单元权值的依据。这种信号正向传播与误差反向传播的各层权值调整过程,是周而复始地进行的。权值不断调整的过程,也就是网络的学习训练过程。此过程一直进行到网络输出的误差减少到可接受的程度,或进行到预先设定的学习次数为止。
八. 贝叶斯学习

 (3)由于P(X)对于所有类为常数,只需要P(XIc;)P(C;)大即可,如果类的先验概率未知,则通常假定这些类是等概率的,此时只需要P(XICz)最大即可。注意,类的先验概率可通过类中的训练样本数/训练样本总数得到。(4)给定具有许多属性的数据集,计算P(XIC)的开销可能非常大。为降低计算开销,可以作类条件独立的朴素假定。给定样本的类标号,假定属性值相互条件独立,即P(XIC)= I=1P(xilCt)。其中P(x;ICt)可由训练样本估值。
(3)由于P(X)对于所有类为常数,只需要P(XIc;)P(C;)大即可,如果类的先验概率未知,则通常假定这些类是等概率的,此时只需要P(XICz)最大即可。注意,类的先验概率可通过类中的训练样本数/训练样本总数得到。(4)给定具有许多属性的数据集,计算P(XIC)的开销可能非常大。为降低计算开销,可以作类条件独立的朴素假定。给定样本的类标号,假定属性值相互条件独立,即P(XIC)= I=1P(xilCt)。其中P(x;ICt)可由训练样本估值。
(5)为对未知样本X分类,对每个类C;计算
P(X\C)P(C).
样本X被指派到类C,当且仅当
P(XIC)P(C)>P(X|C)P(C)1≤j s m,j≠i
九. 在线机器学习
在线机器学习是指每来一个样本,就用迭代方法更新模型变量,使得当前的期望损失最小,因此需要及时处理收集的数据,并给出预测或建议结果,更新模型。
现在的在
线机器学习常用到逻辑回归(logistic regression),在线机器学习算法中主要用到在线梯度下降(OGB)和随机梯度下降(SGD)。
本节介绍几种提升模型稀疏性的在线最优化
求解算法,
包括截断梯度法、前向后向切分算法、正则对偶平均算法、FTRL算法。
1.截断梯度法(Truncated Gradient,TG)
为了得到稀疏的特征权重W,最简单的一个方式就是设定一个阈值,当W某纬度上系数小于这个阈值时将其设置为0。这种方法简单且易于实现,但在实际中W的某个系数比较小有可能是因为该维度训练不足而引起的,简单进行截断会造成这部分特征的丢失。
截断梯度法是对简单截断的一种改进。
在描述截断梯度法之前,首先描述L1正则化和简单截断的方法。.L1正则化法权重更新方式为wt+1)= wt)-n(t)c(t)-7(t)sgn(w(t))
入∈R是一个标量,且入≥0,为L1正则化参数。sgn为符号函数。t为学习率,通常将其设置为1/√t的函数。G(t)= v..l(w t),z())代表了第t次迭代中损失的梯度。


十. 增强学习
增强学习(reinforcement learning,RL
又叫做强化学习,是近年来机器学习和智能控制领域的主要方法之一。相比其他学习方法,增强学习更接近生物学习的本质,因此有望获得更高的智能,这一点在棋类游戏中已经得到体现。
增强学习已经取得了很多骄人的成绩,如第一个击败人类围棋世界冠军的人工智能机器人AlphaGo,目前增强学习已经广泛的应用到了各个领域,如:机器人、计算机视觉、计算机系统、管理系统、推荐系统、自动驾驶以及自然语言处理等领域。
1.增强学习的定义
增强学习又称强化学习,是属于机器学习领域的一类算法。增强学习的学习过程可以归纳为输入
到决策的映射,增强学习的日的炬坦过s Ht选让模型可以获得最大化的收益。增强学习模型在学
习的过程中并不会获得先验知识的指导,而是通过尝试学习的方式为了获得最大化收益不断的试错。增强学习关注的是根据环境为了获取最大化收益进行决策的过程,我们把这个从环境到决策的映射过程称之为策略。
增强学习主要由参与学习的本体和与本体进行交互的环境两个主要部分组成,增强学习的决策过程。
3.数学原理
在增强学习的系统中,有一个状态集合S,行为集合A,策略t,有了策略t,就可以根据当前的状态,来选择下一刻的行为,α = T(s).对于状态集合当中的每一个状态s,都有相应的回报值R(s)与之对应;对于状态序列中的每下一个状态,都设置一个衰减系数y 。
对于每一个策略t ,设置一个相应的权值函数:VT(so)=E[R(so)+ yR(si)+y2R(s2)+这个表达式应该满足Bellman-Ford Equation,可以写成:V T(so) = E[R(so)+yVT(si)]
4.增强学习的策略
假设现在有这样一个场景。在一个游戏中某一个状态下有四种选择,可以向前后左右四个方向走。求解往哪个方向走收益最大主要有一下三种方法。·蒙特卡洛方法
简单而言,蒙特卡洛方法就是对这个策略所有可能的结果求平均。向前走了以后,再做一个决策,根据这个式子,直到迭代结束,求出收益的和,就是向前走这个动作的一个采样。再不断地在这个状态采样,然后来求平均。等到采样变得非常非常多的时候,结果的统计值就接近期望值了。
5.用神经网络来对状态进行估算
整个系统在运作过程中,通过现有的策略,产生了一些数据,获得的这些数据在计算回报值的时候会有所修正。然后用修正的值和状态,作为神经网络进行输入,再进行训练。最后的结果显示,这样做是可以收敛的。所以在加入了神经网络之后,各个部分之间的关系就变成了:神经网络的运用包括训练和预测两部分,训练的时候输入是状态和这个状态相应的数值,预测的时候输入是状态,输出是这个数值预估的数值。
十一. 迁移学习
在许多机器学习和数据挖掘算法中,一个重要的假设就是目前的训练数据和将来的训练数据,一定要在相同的特征空间并且具有相同的分布。然而,在许多现实的应用案例中,这个假设可能不会成立。比如,我们有时候在某个感兴趣的领域有个分类任务,但是我们只有另一个感兴趣领域的足够训练数据,并且两者的数据处于与不同的特徙手"→的公卷任务就需要重新收集数括果我们想要实现本领域的分类任务就需要重新收集数据。建立模型,.远然'5化我们将会通过避免花费大量昂贡知识的迁移做的成功,我们将会通过避免花的标记样本数据的代价,使得学习性能取得显著的提升。这也就是迁移学习提出的目的。















 1851
1851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









