






文章目录
写在前面:Deepseek简介:
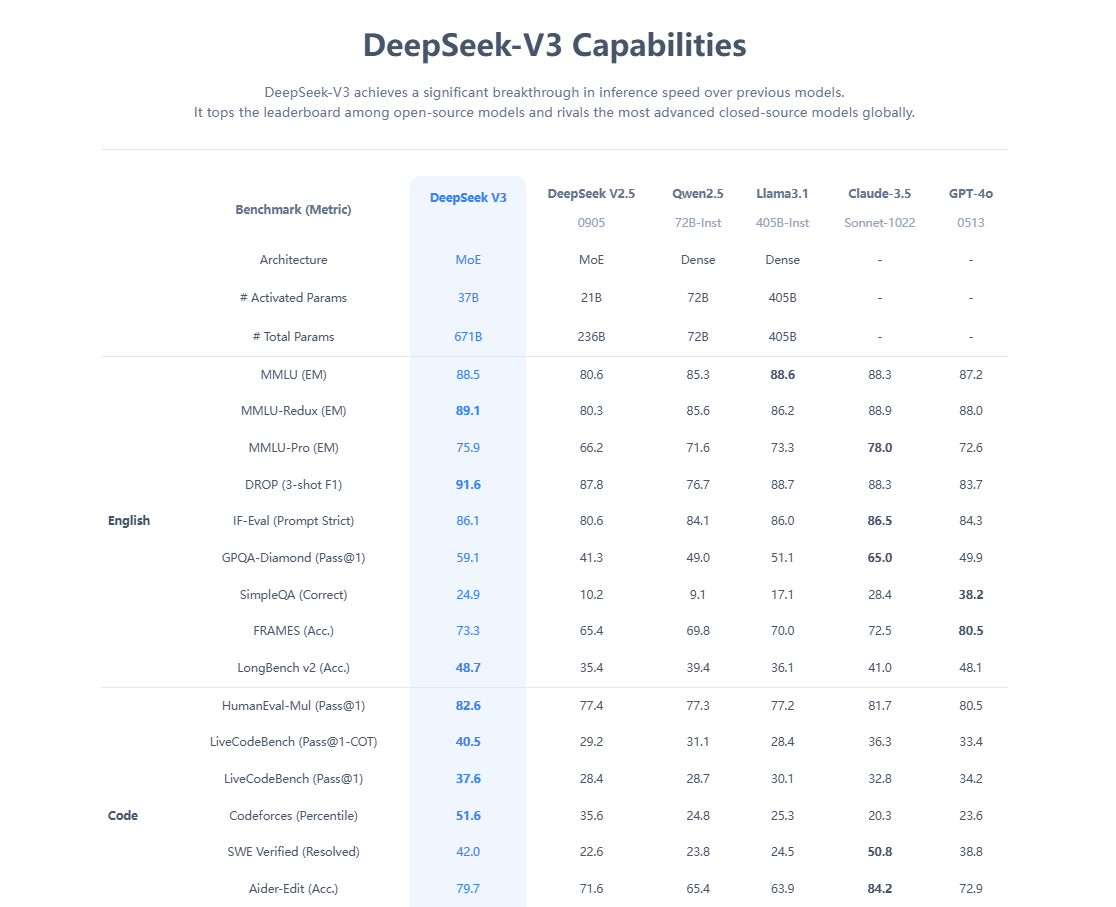
DeepSeek是一款由国内人工智能公司研发的大型语言模型,拥有强大的自然语言处理能力,能够理解并回答问题,还能辅助写代码、整理资料和解决复杂的数学问题。一经发布,DeepSeek开发的移动应用程序超越OpenAI的ChatGPT,登顶苹果手机应用商店美国区、中国区免费应用榜单。
与OpenAI开发的ChatGPT相比,DeepSeek不仅率先实现了媲美OpenAI-o1模型的效果,还大幅降低了推理模型的成本。其新模型DeepSeek-R1以十分之一的成本达到了GPT-o1级别的表现,引发海外AI圈的广泛讨论。
那么,DeepSeek到底是什么?为什么能“引爆”美国科技圈?大家关注近几天的新闻就可一探究竟,本期主要带着大家一键部署自己的DeepSeek服务,一起来看看吧!
官网:https://www.deepseek.com
GitHub:https://github.com/deepseek-ai
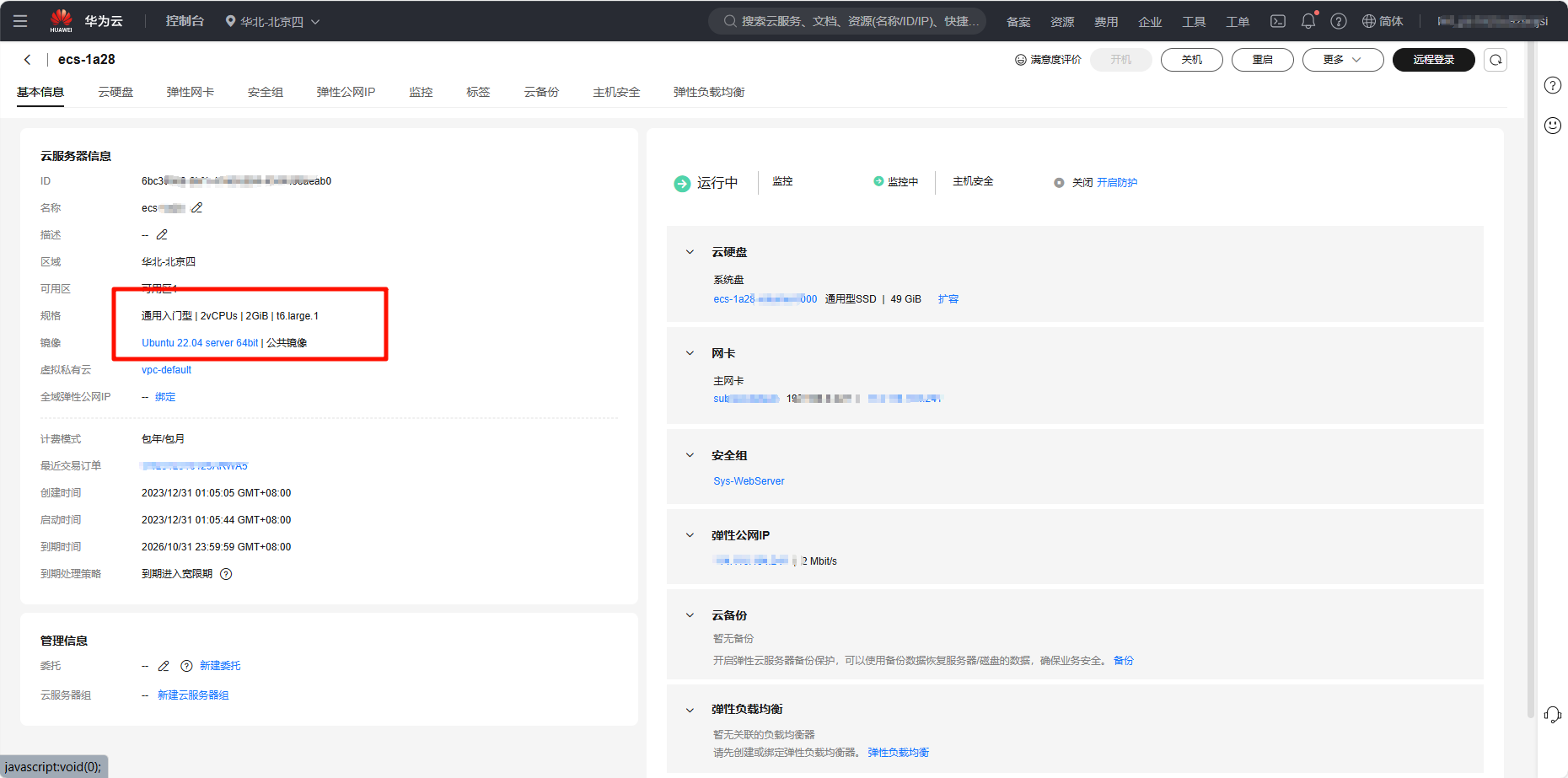
准备工作:为什么选择2核2G ECS服务器?
因为我记得我好像有台四核八G的服务器一直没用过,这两天刷抖音逛b站都是各种博主本地部署Deepseek R1模型,我转头想想我的“破电脑”还能造吗???
那我就想着在服务器部署吧,但是服务器哪来的GPU,那不得吧CPU干冒烟,那我就想那就试试最小的1.5b参数的模型吧,刚开始就只当头一棒,卧槽,记错啦,服务器怎么成了2核2g???这还搞个头呢?
但是开弓哪有回头箭,硬着头皮干就完事啦!
环境准备
官方推荐配置
DeepSeek R1 模型参数和显存需求:
| 模型名称 | 参数量 | 显存需求 | 推荐显卡型号(最低) |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | 4-6 GB | GTX 1660 Ti、RTX 2060 |
| DeepSeek-R1-Distill-Qwen-7B | 7B | 12-16 GB | RTX 3060、RTX 3080 |
| DeepSeek-R1-Distill-Llama-8B | 8B | 16-20 GB | RTX 3080 Ti、RTX 3090 |
| DeepSeek-R1-Distill-Qwen-14B | 14B | 24-32 GB | RTX 3090、RTX 4090 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 48-64 GB | A100、H100 |
| DeepSeek-R1-Distill-Llama-70B | 70B | 80-128 GB | A100、H100、MI250X |
小落配置
一台2核2g ECS云服务器,没啦!
其他环境准备:
操作系统:Ubuntu 22.04 或类似的 Linux 发行版。
软件:Python 3.8 或更高版本,并且您的系统上安装了 Git。
可用磁盘空间: 对于较小的模型,至少 10 GB;
话说CPU、内存就没要求吗,当然有,但我们这就配置还怎么要求,就用点魔法啦!
DeepSeek R1 模型的获取与部署
要成功运行 DeepSeek R1 模型,首先需要安装并配置好一些基础工具。这里我们将通过 Ollama 工具来下载和运行 DeepSeek 模型。Ollama 是一款专为在本地运行 AI 模型而设计的工具,它能够帮助你快速部署和管理模型,确保顺利完成 AI 服务的搭建。
第 1 步:安装 Ollama
Ollama 提供了一个简单的安装脚本,你可以通过以下命令在终端中直接安装:
curl -fsSL https://ollama.com/install.sh | sh
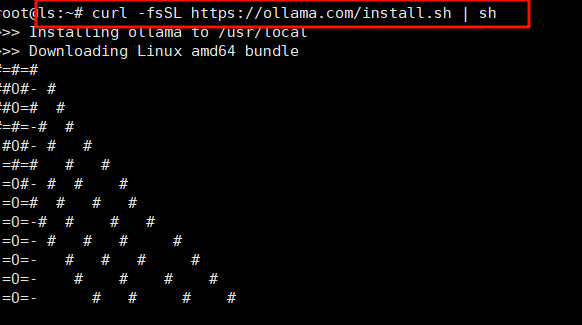
此命令将自动下载并执行 Ollama 安装脚本,在安装过程中,Ollama 会自动配置所需的服务并完成安装。安装完成后,你可以通过以下命令检查 Ollama 是否已成功安装:
ollama --version

如果安装成功,系统将输出版本信息。接下来,我们需要确认 Ollama 服务是否正在运行:
systemctl is-active ollama.service

如果输出为 active,说明 Ollama 服务正在运行,接下来就可以跳过此步骤,继续进行下一步。如果输出不是 active,则需要手动启动 Ollama 服务:
sudo systemctl start ollama.service
为了确保 Ollama 服务在系统启动时自动运行,你可以使用以下命令:
sudo systemctl enable ollama.service
第 2 步:下载并运行 DeepSeek-R1 模型
DeepSeek-R1 模型包括了基于 Qwen 和 Llama 架构微调的多个提炼模型,这些模型已经针对不同的性能需求和资源限制进行了优化。你可以根据自己系统的资源情况选择适合的模型进行部署。
在安装并启动 Ollama 后,你可以使用以下命令下载并运行 DeepSeek-R1 模型:
ollama run deepseek-r1:1.5b
!!!敲桌子!!!
这里是重点
下载报错
pulling manifest
pulling aabd4debf0c8... 100% ▕██████████▏ 1.1 GB
pulling 369ca498f347... 100% ▕██████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕██████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕██████████▏ 148 B
pulling a85fe2a2e58e... 100% ▕██████████▏ 487 B
verifying sha256 digest
writing manifest
success
Error: model requires more system memory (1.6 GiB) than is available (1.3 GiB)
root@ecs-1a28:~#
root@ecs-1a28:~#
问题分析
内存限制: 你的服务器只有 2 GiB 内存,对于运行像 DeepSeek-R1:7B 这样的模型来说,显然是不足的。
你的2核2g服务器大概率是无法安装运行模型的,就连最小的1.5b参数也不行!
这里我们就要用魔法啦,直接造出来10个G的虚拟内存来运行我们的模型!
虚拟内存
虚拟内存 是操作系统提供的一种内存管理机制,它使计算机能够扩展其有效内存的大小。通过虚拟内存,操作系统能够将部分内存内容(不常用的部分)从 物理内存(RAM)迁移到 硬盘 或 SSD 上,形成一个 虚拟内存空间。
虚拟内存的关键概念:
物理内存:是计算机中的实际内存(RAM)。当系统运行程序时,它会将数据加载到物理内存中。
Swap 空间(交换空间):Swap 是硬盘上的一块空间,用作扩展内存的补充。当物理内存不够用时,操作系统会将不活跃的数据或进程从物理内存移动到 Swap 空间。
分页机制:操作系统使用分页机制将内存划分为固定大小的块(页),当物理内存不足时,操作系统会将一些页面数据交换到 Swap 中。
虚拟内存的工作原理:
内存管理:当程序需要更多内存时,操作系统会检查物理内存和 Swap 空间。如果物理内存不足,操作系统会把部分内容转移到 Swap 空间,释放出更多空间给当前运行的程序。
内存交换:当程序不再频繁使用某些数据时,它会被移动到 Swap 空间。当这些数据再次需要时,操作系统会把它们从 Swap 空间读取回来。
这里我大概推算的一个模型内存占比
我们可以通过 7B 模型内存需求与参数量的比例 来估算其他模型的 内存需求。假设 1.5B 模型 需要大约 1.2 GiB 的内存(按 7B 模型的 5.6 GiB 内存比例推算),我们将继续使用这个比例来推算其他模型的内存需求。
假设内存需求与参数量呈线性关系:
7B 模型内存需求: 5.6 GiB
1.5B 模型内存需求: 5.6×0.214≈1.25.6×0.214≈1.2 GiB
推算其他模型的内存需求
| 模型名称 | 参数量 | 内存需求估算(GiB) |
|---|---|---|
| DeepSeek-R1:1.5B | 1.5B | 1.2 GiB |
| DeepSeek-R1:3B | 3B | 2.4 GiB |
| DeepSeek-R1:7B | 7B | 5.6 GiB |
| DeepSeek-R1:14B | 14B | 11.2 GiB |
| DeepSeek-R1:32B | 32B | 25.6 GiB |
| DeepSeek-R1:70B | 70B | 56 GiB |
在你的 Ubuntu 22.04 服务器上,可以通过以下步骤再增加 10GB 的 Swap(虚拟内存):
步骤 1:创建新的 Swap 文件
- 创建一个 10GB 的 Swap 文件:
sudo fallocate -l 10G /swapfile2

如果 fallocate 不可用,可以使用以下命令代替:
sudo dd if=/dev/zero of=/swapfile2 bs=1G count=10
-
设置文件权限:
确保 Swap 文件只有 root 用户可以访问:sudo chmod 600 /swapfile2 -
将文件设置为 Swap:
使用以下命令将文件设置为 Swap 空间:sudo mkswap /swapfile2 -
启用新的 Swap 文件:
sudo swapon /swapfile2
步骤 2:验证 Swap 是否增加
-
检查 Swap 空间:
free -h你应该看到总的 Swap 空间增加了 10GB。

-
显示所有启用的 Swap 文件:
swapon --show你应该看到
/swapfile2在列表中。

步骤 3:确保 Swap 文件在系统重启后仍然启用
-
编辑
fstab文件:sudo nano /etc/fstab -
在文件末尾添加以下内容:
/swapfile2 none swap sw 0 0 -
保存并退出。
接下来就可以重新运行以下命令下载安装模型
ollama run deepseek-r1:1.5b

通过这一过程,你已经完成了 DeepSeek R1 模型的获取与部署,接下来可以开始进行更复杂的任务,或者根据需要进一步优化配置。
Deepseek Web UI 部署
🟢 1. 安装 Docker
如果未安装 Docker,可使用以下命令安装:
sudo apt update
sudo apt install -y docker.io
sudo systemctl enable --now docker
sudo usermod -aG docker $USER
验证 Docker 是否正常运行:
docker --version
docker ps
🟢 2. 部署 Open WebUI
1️⃣ 拉取 WebUI 镜像
docker pull ghcr.io/open-webui/open-webui:main
2️⃣ 运行 WebUI
使用 --network=host 让 WebUI 直接访问 Ollama:
docker run -d --network=host -v open-webui:/app/backend/data \
-e OLLAMA_BASE_URL=http://127.0.0.1:11434 \
--name open-webui --restart always ghcr.io/open-webui/open-webui:main
参数说明:
--network=host使 WebUI 能直接访问本机127.0.0.1:11434。-v open-webui:/app/backend/data持久化 WebUI 数据。-e OLLAMA_BASE_URL=http://127.0.0.1:11434指定 Ollama 地址。
检查 WebUI 是否正常运行:
docker ps
如果成功,状态应为 Up (healthy):
CONTAINER ID IMAGE STATUS PORTS NAMES
abcd1234 ghcr.io/open-webui/open-webui:main Up (healthy) ... open-webui
查看 WebUI 日志(排查错误):
docker logs open-webui --tail 50
🟢 3. 确保 WebUI 端口可访问
1️⃣ 检查 WebUI 是否监听 8080 端口
ss -tulnp | grep 8080
如果未监听,尝试重新启动 WebUI:
docker restart open-webui
2️⃣ 确保防火墙开放 8080 端口
sudo ufw allow 8080/tcp
sudo ufw status
应看到:
8080 ALLOW Anywhere
3️⃣ 确保云服务器安全组开放 8080 端口
如果使用 阿里云 / 腾讯云 / 华为云,需在 云服务器安全组 中添加 入站规则:
- 协议: TCP
- 端口范围:
8080 - 来源:
0.0.0.0/0
🟢 4. 访问 WebUI
在本地浏览器打开:
http://<你的服务器公网IP>:8080
如果页面加载正常,说明部署成功 🎉。
接下来就是注册登录,可以把ip发给小伙伴一起使用啦!

🔴 如果仍然无法访问
1️⃣ 测试服务器本地访问
在服务器上运行:
curl http://127.0.0.1:8080
如果有返回 HTML 或 JSON,说明 WebUI 在本机运行正常,问题可能是 防火墙或安全组 导致的。
2️⃣ 检查 WebUI 日志
docker logs open-webui --tail 50
如果日志中有 Connection Refused,可能是:
OLLAMA_BASE_URL未正确设置。- WebUI 没有正确连接到 Ollama。
3️⃣ 确保 WebUI 连接到 Ollama
curl http://127.0.0.1:11434/api/tags
如果返回:
{"models":["deepseek-r1:1.5b"]}
说明 Ollama 正常运行。
如果 无法连接,尝试:
ollama serve &
docker restart open-webui


















 5116
5116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











