







数据源:
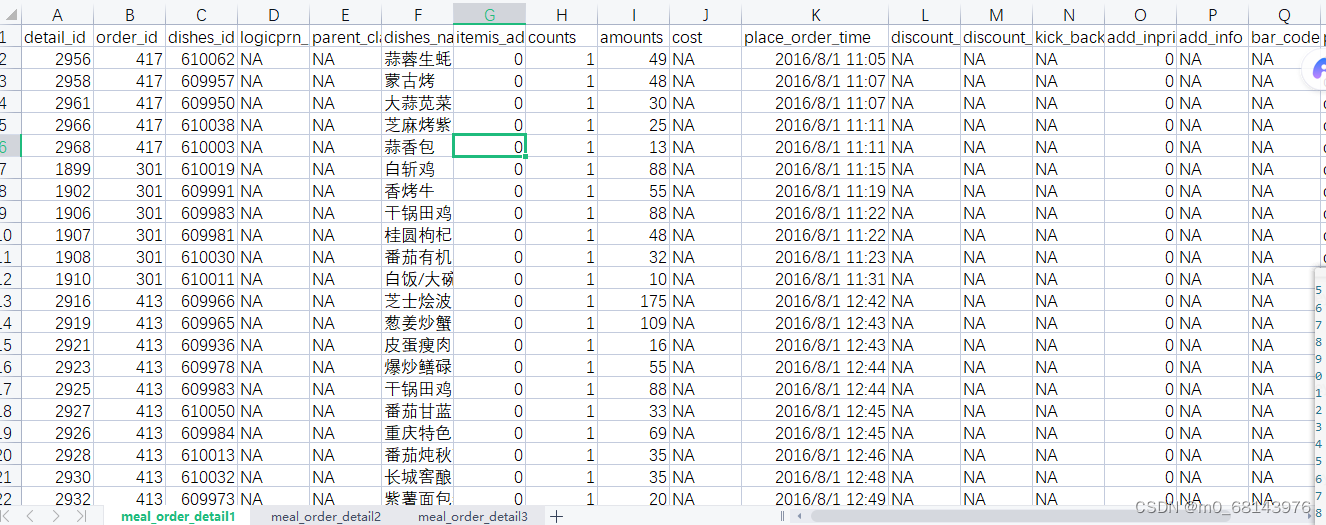
有用数据字段:
# 加载数据
# 1.订单的长度,shape,columns
# 2. 统计菜名的平均价格(amounts)
# 3.什么菜最受欢迎
# 4.那个订单ID点的菜最多
import pandas as pd
import numpy as np
import xlrd
import matplotlib.pyplot as plt
pd.options.display.max_rows = 100000
data1 = pd.read_excel('meal_order_detail.xlsx',sheet_name='meal_order_detail1',nrows= 100)
data2 = pd.read_excel('meal_order_detail.xlsx',sheet_name='meal_order_detail2',nrows= 100)
data3 = pd.read_excel('meal_order_detail.xlsx',sheet_name='meal_order_detail3',nrows= 100)
# 数据预处理(合并数据,NA的处理),分析数据
data = pd.concat([data1,data2,data3],axis=0)#将文件中的三个sheet按照行进行拼接在一起
# data.head(5)
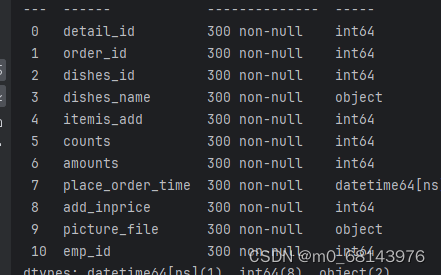
data.dropna(axis=1,inplace=True)#按照列删除na值,inplace=True在原始的data上进行修改
data.info()#查看数据信息
# 统计八月份卖出菜品的平均价格
df1=round(data['amounts'].mean(),2) #方法一:pandas自带函数mean()平均值函数
df2=round(np.mean(data['amounts']),2) # 方法二:numpy函数处理比pandas快
print(df1)
# 频数统计,什么菜最受欢迎,(对菜名进行频数统计,取最大的前十名)
dishes_count = data['dishes_name'].v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









