






读入pandas的DataFrame有俩种方式
1、逗号分隔csv可以使用read_csv将其读入一个DataFrame
2、使用read_table,指定分隔符
并非所有文件都有标题行,在读取文件的时候可以用header为文件指定标题行
example:
df=pd.read_table('Project/example/ex1.csv',sep=',',header=None)
df=pd.read_table('Project/example/ex1.csv',sep=',',names=(['a','b','c','message']))
可以指定文件中某一列作为文件的索引,使用index_col='指定列':
names=(['a','b','c','d','message'])
df=pd.read_csv('Project/example/ex1.csv',names=names,index_col='message')
print(df)
out:
a b c d
message hello 1 2 3 4 world 5 6 7 8 foo 9 10 11 12
分层索引:
需指定包含的序列号或列名
parsed =pd.read_csv('Project/example/csv_mindex',
index_col=['key1','key2'])#指定序列号
ex3.txt原始数据
A B C aaa 0.264438 -1.026059 -0.619500 bbb 0.927272 0.302904 -0.032399 ccc -0.264273 -0.386314 -0.217601 ddd -0.871858 -0.348382 1.100491
list(open('examples/ex3.txt'))
out:
[' A B C\n',
'aaa -0.264438 -1.026059 -0.619500\n',
'bbb 0.927272 0.302904 -0.032399\n',
'ccc -0.264273 -0.386314 -0.217601\n',
'ddd -0.871858 -0.348382 1.100491\n']
可以使用正则表达式\s+规范数据输出:
result=pd.read_table('Project/example/ex3.txt',sep='\s+')
print(result)
out:
A B C
aaa 0.264438 -1.026059 -0.619500 bbb 0.927272 0.302904 -0.032399 ccc -0.264273 -0.386314 -0.217601 ddd -0.871858 -0.348382 1.100491
列名数量比数据的列少一个,read_table推断第一列应当作为DataFrame的索引。
ex4原始数据:
# hey! a,b,c,d,message # just wanted to make things more difficult for you # who reads CSV files with computers, anyway? 1,2,3,4,hello 5,6,7,8,world 9,10,11,12,foo
这里使用skiprows=[0,2,3]跳过1、3、4行的数据
obj=pd.read_csv('Project/example/ex4.csv',
skiprows=[0,2,3])
缺失值处理:
Python一般使用NA和NULL或者空白字符串来表示缺失值:
ex5.csv原始数据:
something,a,b,c,d,message
230one,1,2,3,4,NA
two,5,6,,8,world
three,9,10,11,12,foo
out:
something a b c d message 0 230one 1 2 3.0 4 NaN 1 two 5 6 NaN 8 world 2 three 9 10 11.0 12 foo
使用is_null(pd.is_null(obj),obj.is_null(obj))来返回数据是否缺失的布尔值
字典中可以指定不同的缺失值标识
IN:
result = pd.read_csv('Project/example/ex5.csv',
na_values={'message':['foo','NA'],'something':['two']})
print(result)
out:
something a b c d message
0 one 1 2 3.0 4 NaN
1 NaN 5 6 NaN 8 world
2 three 9 10 11.0 12 NaN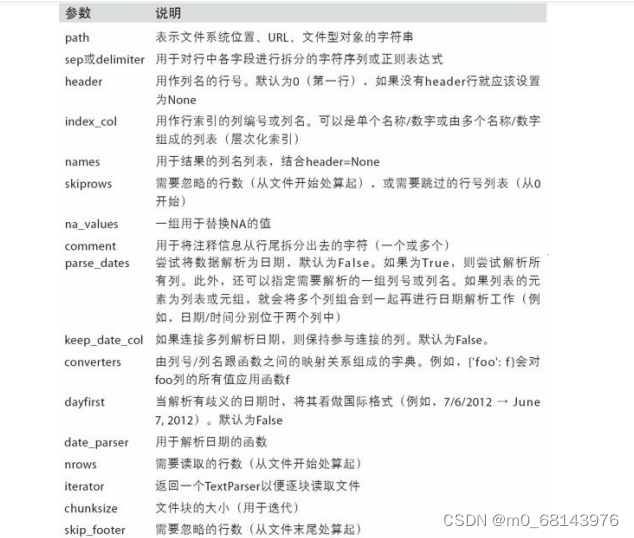

分块读入文本文件:
pd.options.display.max_rows = 10# 对pandas的显示设置进行调整,使之变得宽松或者紧凑
result=pd.read_csv('Project/example/ex6.csv',nrows=5)
nrows=int,用于限制读取文件的特定行数
如果您遇到了"TextFileReader' object has no attribute 'columns'"的报错,这是因为
read_csv 函数返回的是一个
TextFileReader 对象而不是一个DataFrame对象。您需要使用
get_chunk() 方法来获取数据块并转换为DataFrame对象,然后再查看列名。以下是一个示例代码:
import pandas as pd
# 读取CSV文件
reader = pd.read_csv('your_file.csv', chunksize=1000) # 指定chunksize为1000或其他适当大小
# 获取第一个数据块并转换为DataFrame对象
df_chunk = next(reader)
# 查看所有列名
columns_list = df_chunk.columns
# 打印所有列名
print(columns_list)chunksize可以作为每一块的行数
# 读取CSV文件
reader = pd.read_csv('Project/example/ex6.csv', chunksize=1000) # 指定chunksize为适当大小
# 初始化一个空的Series对象
tot = pd.Series()
# 遍历数据块
for piece in reader:
# 统计每个数据块中'key'列中每个值的出现次数并累加到tot中
tot = tot.add(piece['key'].value_counts(), fill_value=0)
# 打印最终结果
print(tot)
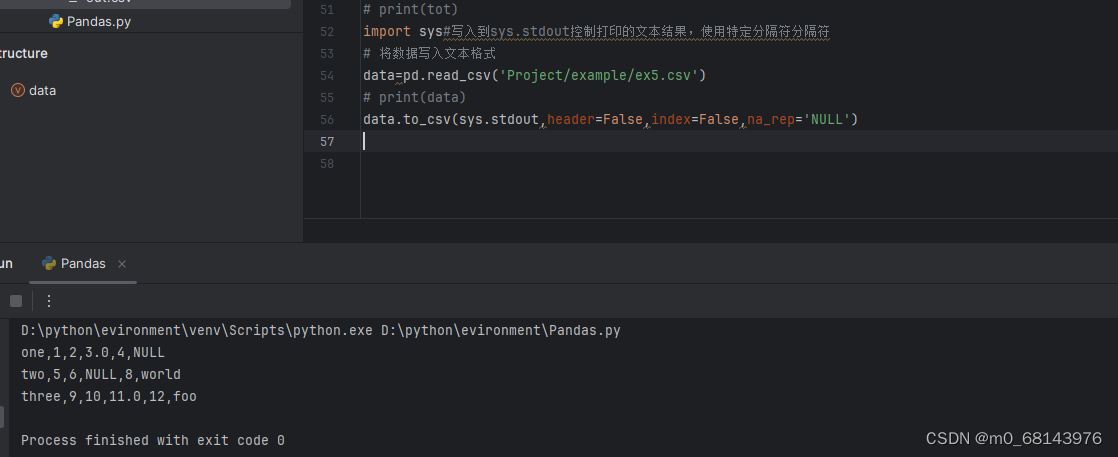
使用DataFrame的to_csv方法,可以将数据导出为逗号分隔的文件
ex5文件数据:
something,a,b,c,d,message one,1,2,3,4,NA two,5,6,,8,world three,9,10,11,12,foo
to_csv方法:将数据导出为逗号分隔的文件:
data=pd.read_csv('Project/example/ex5.csv')
print(data)
data.to_csv('Project/example/out.csv')
out.csv文件:
,something,a,b,c,d,message 0,one,1,2,3.0,4, 1,two,5,6,,8,world 2,three,9,10,11.0,12,foo 也可以使用其他分隔符,sys.stdout
如果不想显示行列标签,则可以设置header和index的值;缺失值读出文件时,会以空字符串出现,如果想用某些标识符或数字对缺失值进行标注,可以使用na_rep='NULL'(NULL是任意标识符或则数字)
可以选择性的写入列的子集,按照你所选定的顺序写入

Series的to_csv方法:
import sys#写入到sys.stdout控制打印的文本结果,使用特定分隔符分隔符
# 将数据写入文本格式
# data=pd.read_csv('Project/example/ex5.csv')
# # print(data)
# data.to_csv(sys.stdout,columns=['a','b','c','message'])
import numpy as np
dates=pd.date_range('1/1/2000',periods=7)#使用 pandas 的 date_range() 函数生成一个包含从 '2000年1月1日' 开始的连续7天日期的日期索引。
ts=pd.Series(np.arange(7),index=dates)#创建一个 pandas Series 对象,其中包含从 0 到 6 的连续整数作为数据,使用上一步生成的日期索引作为索引。
ts.to_csv(sys.stdout)
ex7文件数据:
"a","b","c" "1","2","3" "1","2","3"
import csv
# f = open('Project/example/ex7.csv')
# reader=csv.reader(f)
# for lines in reader:
# print(lines)
with open('Project/example/ex7.csv') as f:
lines=list(csv.reader(f))
header,values = lines[0],lines[1:]
data_dict = {h: v for h,v in zip(header,zip(*values))}
print(data_dict)
使用字典推导式和表达式zip(*values)生成一个包含数据列的字典,字典字典转置成列
out:
{'a': ('1', '1'), 'b': ('2', '2'), 'c': ('3', '3')}
















 1655
1655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









