






 本文介绍了如何使用KNN算法对电影类型进行预测,通过给出的训练数据集,对老友记进行预测,结果显示其属于喜剧片类别。
本文介绍了如何使用KNN算法对电影类型进行预测,通过给出的训练数据集,对老友记进行预测,结果显示其属于喜剧片类别。
实验目的
- 掌握KNN算法原理;
2.编程实现KNN算法,并应用与具体案例
实验内容
- 使用KNN进行电影类型预测:
给定训练样本集合如下:

求解:testData={"老友记": [29, 10, 2, "?片"]}。
实验步骤及实验结果
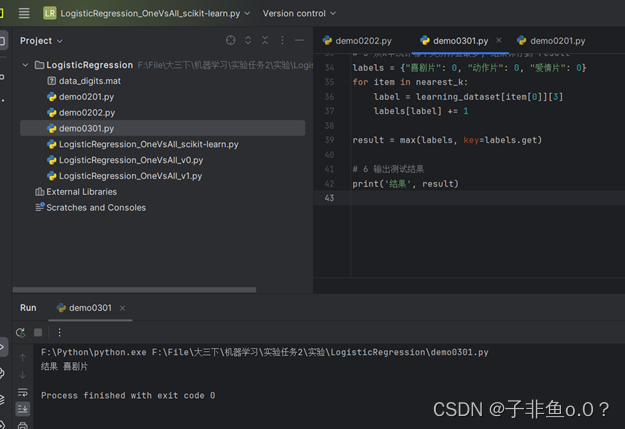
#encoding=UTF-8
import numpy as np
# 1 给定训练数据集
learning_dataset = {"宝贝当家": [45, 2, 9, "喜剧片"],
"美人鱼": [21, 17, 5, "喜剧片"],
"澳门风云3": [54, 9, 11, "喜剧片"],
"功夫熊猫3": [39, 0, 31, "喜剧片"],
"谍影重重": [5, 2, 57, "动作片"],
"叶问3": [3, 2, 65, "动作片"],
"伦敦陷落": [2, 3, 55, "动作片"],
"我的特工爷爷": [6, 4, 21, "动作片"],
"奔爱": [7, 46, 4, "爱情片"],
"夜孔雀": [9, 39, 8, "爱情片"],
"代理情人": [9, 38, 2, "爱情片"],
"新步步惊心": [8, 34, 17, "爱情片"]}
# 2 给定测试数据,利用KNN判断所属类别,令k=6
testData = {"老友记": [29, 10, 2, "?片"]}
k = 6
# 3:计算测试样本与数据集中所有数据的距离,保存在disList
disList = []
dataPoint = list(testData.values())[0][0:3]
for key, value in learning_dataset.items():
dis = np.sqrt(np.sum(np.square(np.array(dataPoint) - np.array(value[0:3]))))
disList.append((key, dis))
# 4:按照距离大小进行排序,取出前k个距离最小样本
disList.sort(key=lambda x: x[1])
nearest_k = disList[:k]
# 5 从k中统计哪个类别标签最多, 结果保存到 result
labels = {"喜剧片": 0, "动作片": 0, "爱情片": 0}
for item in nearest_k:
label = learning_dataset[item[0]][3]
labels[label] += 1
result = max(labels, key=labels.get)
# 6 输出测试结果
print('testdata belong to', result)















 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









