






 本文介绍了如何使用Python的sklearn库实现支持向量机(SVM)算法,包括随机样本的二分类、线性SVM的应用以及对葡萄酒数据集进行分类时不同核函数的性能评估。
本文介绍了如何使用Python的sklearn库实现支持向量机(SVM)算法,包括随机样本的二分类、线性SVM的应用以及对葡萄酒数据集进行分类时不同核函数的性能评估。
实验目的
- 掌握支持向量机SVM算法原理;
- 编程实现SVM算法,并进行样本数据二分类
实验内容
1.使用sklearn的SVM算法对样本数据进行分类,要求:
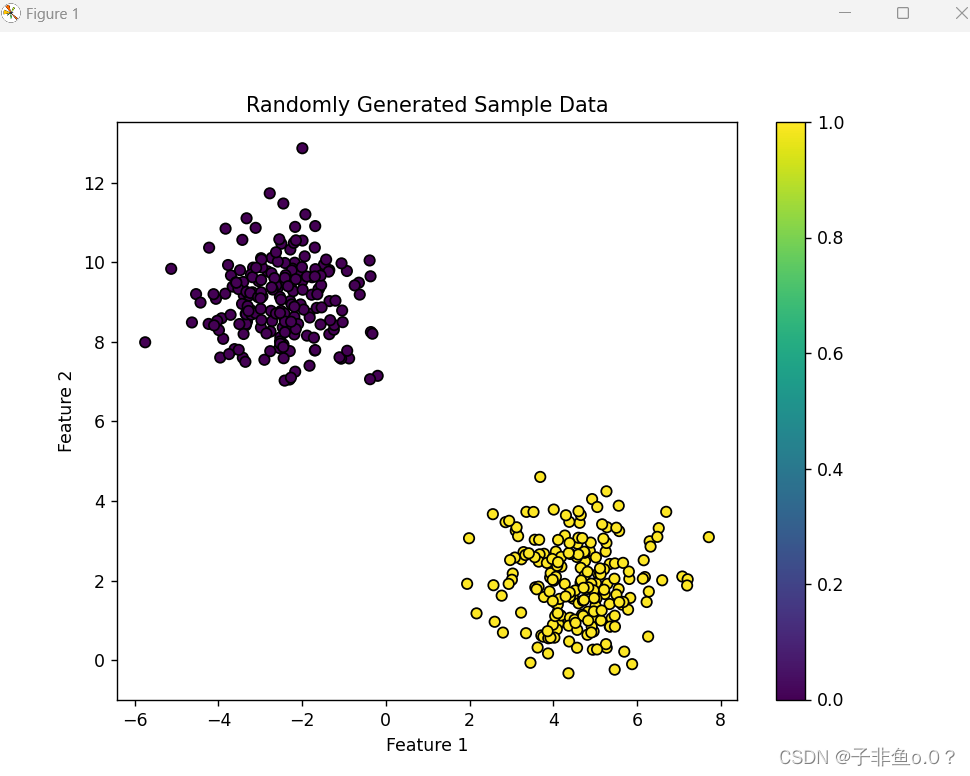
(1)使用sklearn生成随机分布的400个样本点;
(2)对样本点进行显示;
(3)使用线性SVM进行二分类;
(4)评价模型并画出分类边界
2.使用sklearn中SVM算法对葡萄酒数据集进行分类,要求:
(1)对数据集进行分割,20%用于测试;
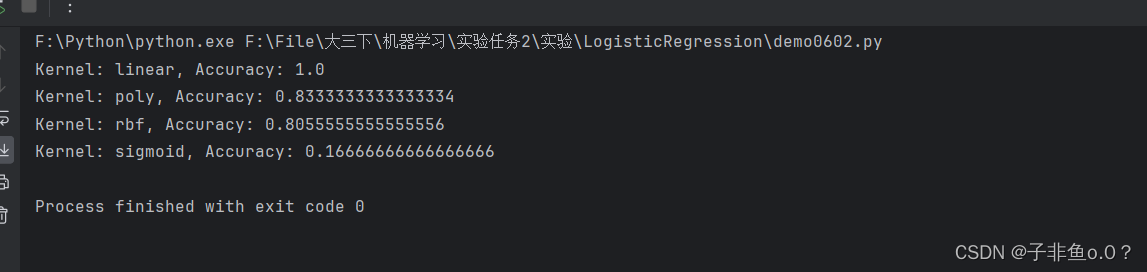
(2)对核函数进行选择(linear、poly、rbf、sigmod),比较不同核函数的分类精度。
实验代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 生成随机分布的400个样本点
X, y = make_blobs(n_samples=400, centers=2, random_state=42)
# 显示样本点
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', edgecolors='k')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Randomly Generated Sample Data')
plt.colorbar()
plt.show()
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用线性SVM进行二分类
svm_model = SVC(kernel='linear', random_state=42)
svm_model.fit(X_train, y_train)
# 评价模型
y_pred = svm_model.predict(X_test)
print(classification_report(y_test, y_pred))
# 画出分类边界
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', edgecolors='k')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Linear SVM Classification')
plt.colorbar()
# 画出决策边界
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx = np.linspace(xlim[0], xlim[1], 30)
yy = np.linspace(ylim[0], ylim[1], 30)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
Z = svm_model.decision_function(xy).reshape(XX.shape)
ax.contour(XX, YY, Z, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--'])
ax.scatter(svm_model.support_vectors_[:, 0], svm_model.support_vectors_[:, 1], s=100, linewidth=1, facecolors='none', edgecolors='k')
plt.show()
import numpy as np
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 加载葡萄酒数据集
wine = load_wine()
X = wine.data
y = wine.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义不同核函数的SVM模型
kernels = ['linear', 'poly', 'rbf', 'sigmoid']
for kernel in kernels:
svm_model = SVC(kernel=kernel)
svm_model.fit(X_train, y_train)
y_pred = svm_model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f"Kernel: {kernel}, Accuracy: {acc}")

















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









