







一.前言
1.在学习本文之前您需要学会python基础,以及他的三个库,numpys,pandas,matplotlib。
2.本节是通过python对双十一美妆销售数据对数据进行处理,如数据清洗,数据去重,分列,数据查询等常见的操作,希望您在看这篇文章的时候,可以一遍看一遍和我进行实操,希望最后你能从中有所收获,一起加油,一起努力。
二.项目介绍
1.项目背景
该数据为某平台2016年双十一的数据,并进行分析,化妆品和护肤品等大类中各个品牌在双十一期间的销售,GMV,热度等的数据变化,并多个维度系统的分析数据,探寻数据之间的关系,并得出相应的结论,并提供给店铺运营,内容策划部等相关部门提出确实可行的建议。
2.项目数据介绍
update_time:指统计时间
id:指产品编号
title:产品标题
price :成交价格
sale_count :产品销量
comment_count:用户评论数
店名:品牌名称
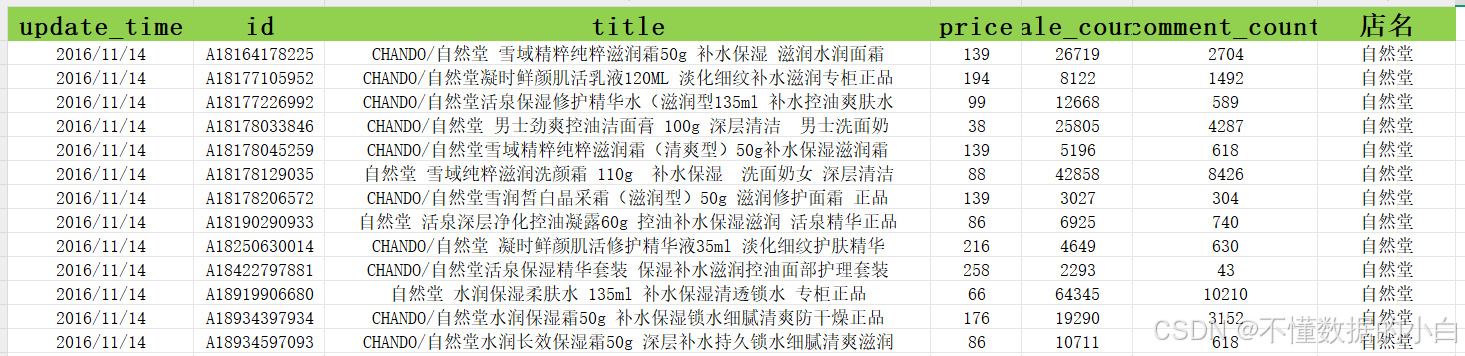
3.项目数据部分展示
注:该数据一共有2W7599条数据,只展示部分以供参考
4.解决的问题
1.购买化妆品的客户的关注度(评论数)是多少?谁的热度(评论数)最高?
2.各产品销量分布情况? 哪些产品的卖得最好,哪些牌子最受欢迎,哪些化妆品是大家最需要的?
3.判断男性最偏爱的产品是什么?
....
5.关键词:
python数据分析,numpy,pandas数据清洗
三.数据分析
一.数据处理前准备
(1)导入numpy,pandas等模块
1、找到pip3.exe所在的文件夹,复制路径(我的是pip3.12)
我的路径是:C:\Users\ZMQ\Desktop\python_test\sunxinghua1\.venv\Scripts
2、按Win+R,输入CMD确定,如下图
3、进入后,先输入cd 路径 回车,如下图
注释:cd和路径之间有个空格
4、输入 pip3.12 install pandas 回车
注释:我已经安装过了,我这里就不展示,numpy同理,多试几次
5、回到Python编译器,或者pycharm 输入import pandas 只要不报错就成功了
6、安装numpy,方法同上

(2)读取数据
注释:该数据为csv文件用pd.read_csv('路径'), 若为excel文件,则pd.read_excel('路径')
import pandas as pd import numpy as np data = pd.read_csv(r'C:\Users\ZMQ\Desktop\双十一美妆数据.csv') #注释:这里的r即为转义字符 print(data.head(5)) #注释:这里导入数据,并输出前五行

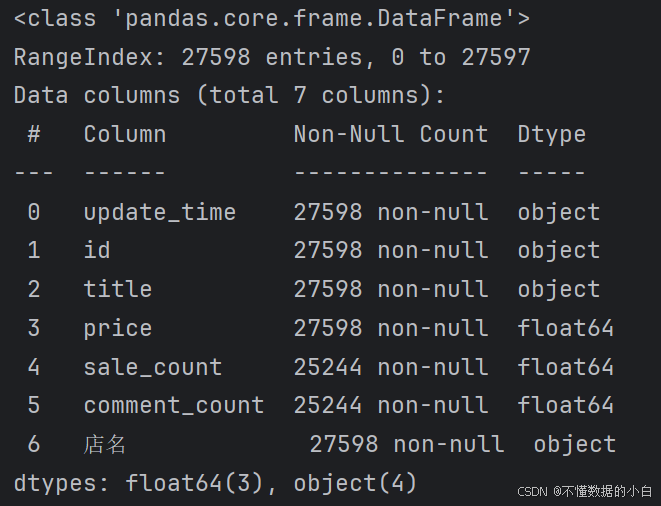
(3)数据基本信息
print(data.info()) # 查看各字段信息,并输出字段,字段类型等,最后输出各种类型的数量
(4)统计不同品牌的出现的次数
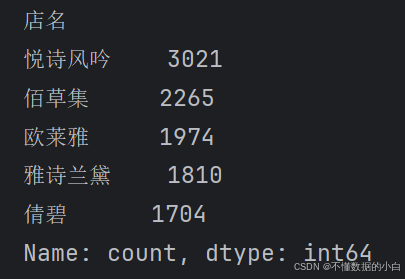
print(data['店名'].value_counts().head()) #注释:统计不同店名出现的次数,并进行计数,并默认按照从大到小进行排序 #注释:索引为店名,值为对应出现的次数
二.数据清洗
(1)对数据进行去重处理
1.对重复数据进行去重 drop_duplicates
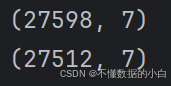
print(data.shape) #注释:输出数据是几行几列的,数据为27598行,7列 data = data.drop_duplicates(subset=None,inplace=False) # #注释:此处subset=None即为不指定列名时,即为所有列,即删除数值完全一样的数据,只保留一个 # inplace=False即在会生成新的一个DataFrame,原表不进行修改 print(data.shape)
注释:这里对重复数据进行去重后,没有对索引进行改变,因此需要重新排序
2.对数据的索引进行重新排序 reset_index
# 此处虽然删除了重复值,但索引未变,因此应用以下方法进行重置索引 print(data.index) data = data.reset_index(drop=True) #注释:reset_index(drop=True) 指的是对原来的索引进行重新排序,然后舍弃之前的索引 print('新索引:',data.index)

(2)对缺失值进行处理
1.查看缺失值 isnull,notnull
注释:这里的any指的是只要这一行有缺失值不管有几个缺失值,都输出True,all即为这一行都为缺失值,才输出True
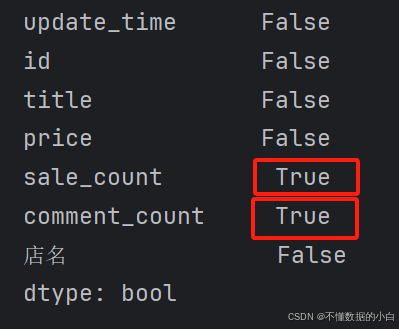
# 查看缺失值 print(data.isnull().any()) #注释:查找任意行存在null,若有null即输出True
从结果可知:sale_count和comment_count这两列都含有缺失值
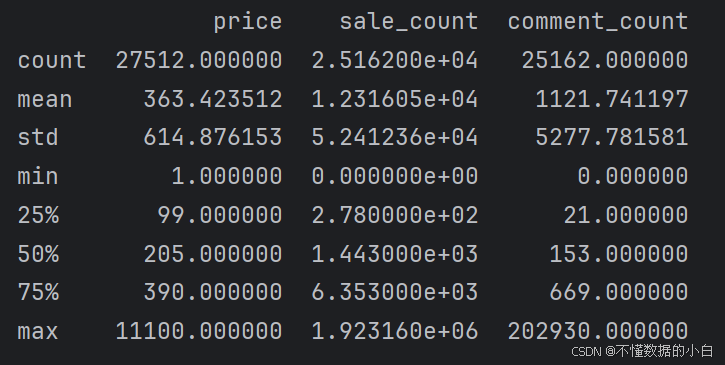
2.查看数据的结构 describle
count:每列中非缺失值(即非NaN)的数量。
mean:每列数据的平均值。
std:每列数据的标准差,用于衡量数据的离散程度。
min:每列数据中的最小值。
25%:每列数据的下四分位数,即数据排序后处于 25% 位置的值。
50%:每列数据的中位数,即数据排序后处于 50% 位置的值。
75%:每列数据的上四分位数,即数据排序后处于 75% 位置的值。
max:每列数据中的最大值。# 查看数据结构 print(data.describe()) #注释:describle()括号中无参数一般是对数值型进行统计分析 #加上including='all',则也会对非数值型进行统计分析,一般不用
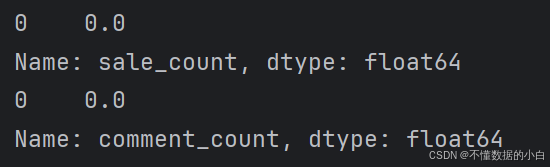
3.查看sale_count和comment_count的众数 mode
# 查看sale_count列的众数 mode_01=data['sale_count'].mode() print(mode_01) # 查看comment_count列的众数 mode_02=data['comment_count'].mode() print(mode_02)
注释:由众数为0,其最小值为0,说明数据有0,计算众数时会忽略缺失值
4.用0填充缺失值 fillna
# 填充缺失值 data = data.fillna(0) print(data.isnull().any())
、
(3)对数据进行增列处理
1.将产品分为子类别,主类别(难点)
将title进行分段,并添加到item_name_cut中,形成新的一列
#注释:处理的目的是提取item_name_cut中的关键词与后面由字符串生成的字典的键进行配对,若配对上即说明该类商品属于特定的子类别和主类别,若配对不上,即为其他类
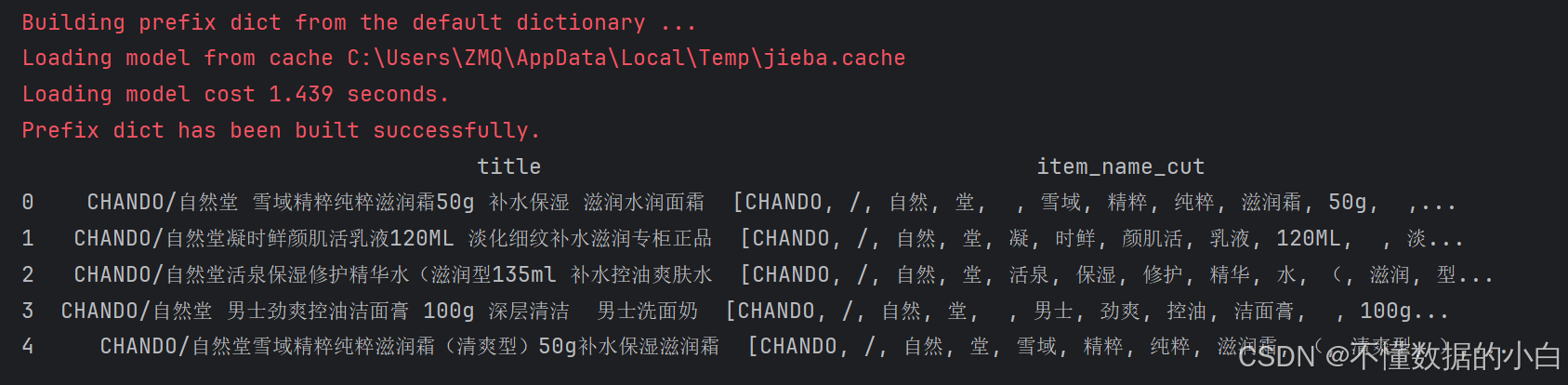
####分列 import jieba #导入结巴分词库 title_cut = [] for i in data.title: j = jieba.lcut(i) #这是直接出列表 #j=list(jieba.cut(i)) title_cut.append(j) data['item_name_cut'] = title_cut print(data[['title','item_name_cut']].head())
将下述字符串的每个关键字进行归类,形成字典
#注释:该分类是网上找的分类,将以下数据分为关键词:(主类别,子类别)
# 第一列为大类即为主类别,第二列为小类即为子类别,后面为关键词 basic_data = """护肤品 套装 套装 护肤品 乳液类 乳液 美白乳 润肤乳 凝乳 柔肤液' 亮肤乳 菁华乳 修护乳 护肤品 眼部护理 眼霜 眼部精华 眼膜 护肤品 面膜类 面膜 护肤品 清洁类 洗面 洁面 清洁 卸妆 洁颜 洗颜 去角质 磨砂 护肤品 化妆水 化妆水 爽肤水 柔肤水 补水露 凝露 柔肤液 精粹水 亮肤水 润肤水 保湿水 菁华水 保湿喷雾 舒缓喷雾 护肤品 面霜类 面霜 日霜 晚霜 柔肤霜 滋润霜 保湿霜 凝霜 日间霜 晚间霜 乳霜 修护霜 亮肤霜 底霜 菁华霜 护肤品 精华类 精华液 精华水 精华露 精华素 护肤品 防晒类 防晒霜 防晒喷雾 化妆品 口红类 唇釉 口红 唇彩 化妆品 底妆类 散粉 蜜粉 粉底液 定妆粉 气垫 粉饼 BB CC 遮瑕 粉霜 粉底膏 粉底霜 化妆品 眼部彩妆 眉粉 染眉膏 眼线 眼影 睫毛膏 化妆品 修容类 鼻影 修容粉 高光 腮红 其他 其他 其他"""# #将上述字符串的每个关键字进行归类,归类形式(字典形式):{关键词:(主类别,子类别)} category={} category_list=basic_data.split('\n') print(category_list) #注释:对basic_data的数据进行换行切割,用逗号分割,生成列表 for i in category_list: main_category=i.strip().split()[0] #将category_list每个值遍历,去除空行,并将每个i按照空格进行分割提取第一个值命名为main_category sub_category=i.strip().split()[1] #同上,并将每个i按照空格进行分割提取第二个值命名为sub_category unit_category_list=i.strip().split()[2:-1] #将剩下的生成列表,命名为unit_category_list for j in unit_category_list: #对以上列表进行遍历,值提取为j category[j]=(main_category,sub_category) #这里将j为字典的键,(main_category,sub_category)作为值,添加到字典category中 print(category)
注释:截取部分,{'乳液': ('护肤品', '乳液类'), '美白乳': ('护肤品', '乳液类')....}
将item_name_cut中的值与之前字典进行匹配,生成主,子类别
注释:exist的作用(有点绕)
1.一开始设置exist=False,如果j在字典category里面则进行以下操作,如果j不在字典category里面,则exist=True,又break则退出这个循环,此时的exist为True,不是一开始的False,所以,if not exist 开始执行
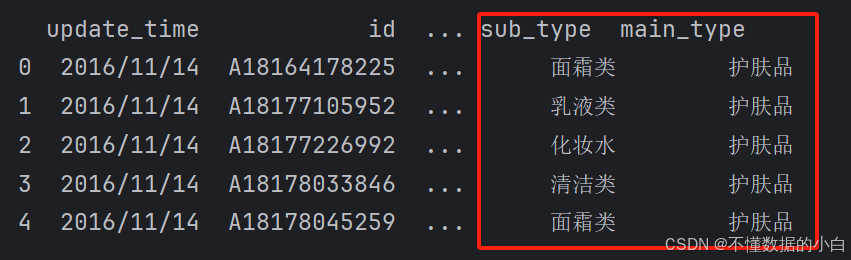
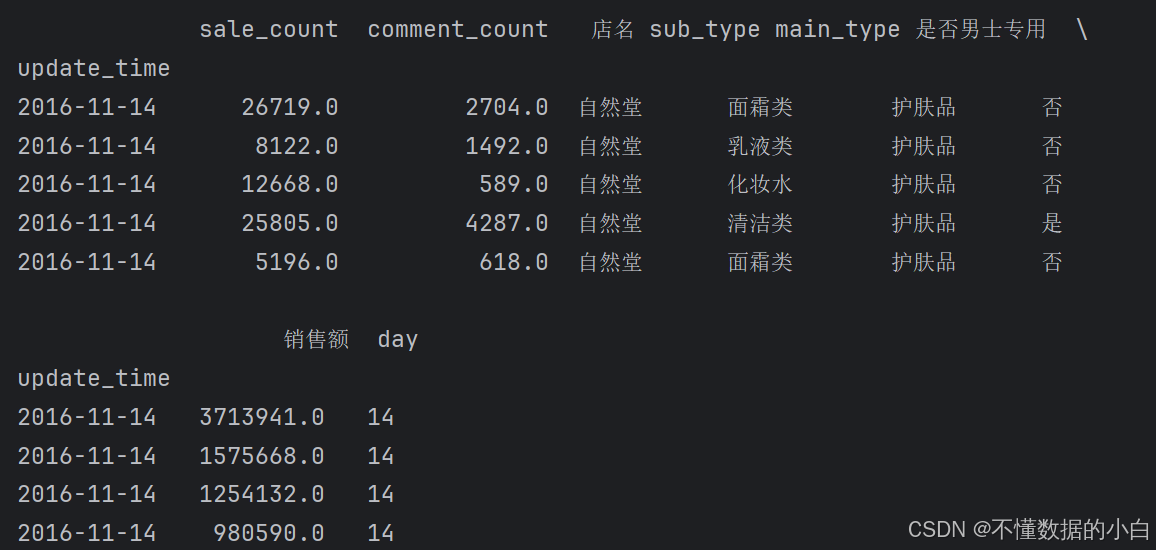
main_type=[] #主类别 sub_type=[] #子类别 for i in range(data.shape[0]): #遍历data行数,生成0到data.shape[0]-1的数组进行遍历 exist = False #设置个开关 for j in data['item_name_cut'][i]: #遍历对title分割后item_name_cut列i行的每个元素(列表) if j in category: sub_type.append(category[j][1]) #注释:若j在字典的关键词中,则它的子类别对应字典中的子类别,并添加到sub_type的列表中 main_type.append(category[j][0]) # 注释:若j在字典的关键词中,则它的主类别对应字典中的主类别,并添加到sub_type的列表中 exist=True break if not exist: sub_type.append('其他') #若j不存在字典中,子类别添加为其他类目 main_type.append('其他') #若j不存在字典中,主类别添加为其他类目 #给data添加两个新列 data['sub_type']=sub_type data['main_type']=main_type print(data.head())
2.提取是否为男性专用并生成一列
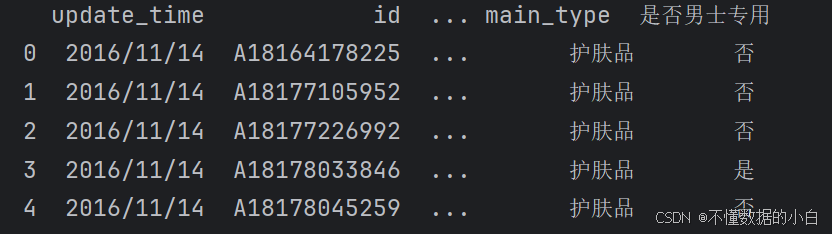
##提取是否为男性专用的产品 gender=[] for i in range(len(data)): if '男' in data['item_name_cut'][i]: gender.append('是') elif '男士' in data.item_name_cut[i]: gender.append('是') elif '男生' in data.item_name_cut[i]: gender.append('是') else: gender.append('否') #以上是判断'男','男士','男生' 是否在每行的item_name_cut中 # 将“是否男士专用”新增为一列 data['是否男士专用'] = gender print(data.head())
3.新增一类销售额,购买日期(天)各为一列
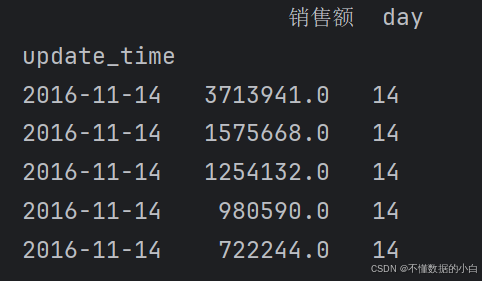
#新增一类销售额,购买日期(天)各为一列 销售额=data.sale_count*data.price data['销售额']=销售额 # 转换时间格式 data['update_time'] = pd.to_datetime(data['update_time']) #注释:利用pandas库中的to_datetime,将字符串格式的日期转化为日期格式 # 将时间设置为新的index data.set_index('update_time',inplace=True) #注释:将新的转换为日期格式的update_time,设置为索引,并通过inplace=True,在原数据进行修改 # 新增时间“天”为一列 data['day'] = data.index.day #注释:对设置为索引的日期提取天,并生成为一列 print(data[['销售额','day']])
4.删除之前生成的中文分列
del data['item_name_cut']5.所有列进行展示
#注释:将所有列都展示出来,列用columns,行用rows pd.set_option('display.max_columns', None) #注释:set_option展示最大列数,又为None说明没有限制 # 查看最终数据表格 print(data.head())
6.将数据清洗后的数据导出xlsx
# ###将清洗好的数据导出为xlsx文件 data.to_excel(r'C:\Users\ZMQ\Desktop\双十一美妆数据清洗后.xlsx')

四.总结
以上是该项目数据处理的所有内容,我认为的难点在于,将原数据中的标题信息进行提取,并将不同的产品归类为与之对应的子类别和主类别,为后面按照主类别or子类别分组,对不用的品牌进行可视化分析,还请大家敬请期待
最后,该部分项目全程自己创作,自己辛苦敲的,若有不懂的可以相互交流,若有错误地方,还请大佬们指出,一起加油,一起学习。

















 2602
2602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









