







机器学习(Machine Learning, ML)是一种通过算法让计算机从数据中学习规律、预测未来的方法。是人工智能的一个重要分支,是实现人工智能的基础之一。线性回归模型是一种常用的有监督机器学习算法,它可以用来预测连续的数值型数据。今天,我们将使用波士顿房价数据集来介绍线性回归模型的应用。
在这个项目中,我们将利用马萨诸塞州波士顿郊区的房屋信息数据训练和测试一个模型,并对模型的性能和预测能力进行评估。通过该数据训练后的好的模型可以被用来对房屋做特定预测--尤其是对房屋的价值。对于房地产经纪等人的日常工作来说,这样的预测模型被证明非常有价值。
一.准备工作
1.导入模块
导入numpy,pandas,matplotlib,scikit-learn库,此处方法同之前,此处略过
import numpy as np import pandas as pd import matplotlib matplotlib.use('TkAgg') import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split #注释:内置的拆分数据函数 from sklearn.linear_model import LinearRegression #注释:线性回归模型 from sklearn.metrics import mean_squared_error , r2_score #注释:回归预测评估函数,MSE,R2 import seaborn as sns plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体 plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题2.数据展示
序列 数据名 说明 数据类型 1 CRIM 城镇人均犯罪率 float64 2 ZN 占地面积超过25,000平方英尺的住宅用地比例 float64 3 INDUS 每个城镇非零售商业用地的比例
float64 4 CHAS 查尔斯河虚拟变量(如果土地靠近查尔斯河则为1,否则为0) float64 5 NOX 一氧化氮浓度(每千万份) float64 6 RM 每栋住宅的平均房间数 float64 7 AGE 1940年之前建成的自用房屋比例 float64 8 DIS 到波士顿五个就业中心的加权距离 float64 9 RAD 辐射状公路的可达性指数 float64 10 TAX 每10,000美元的全值财产税率 float64 11 PTRATIO 城镇师生比例 float64 12 B 1000(Bk - 0.63)^2,其中Bk是城镇中黑人的比例 float64 13 LSTAT 人口中地位较低人群的百分比 float64 14 MEDV 自住房的中位数价值(以千美元计),这是目标变量 float64 3.导入数据
此项目是数据来自UCI机器学习知识库,波士顿房屋这些数据与1978年开始统计,共506个数据点,涵盖了麻省波士顿不同郊区房屋14种特征的信息
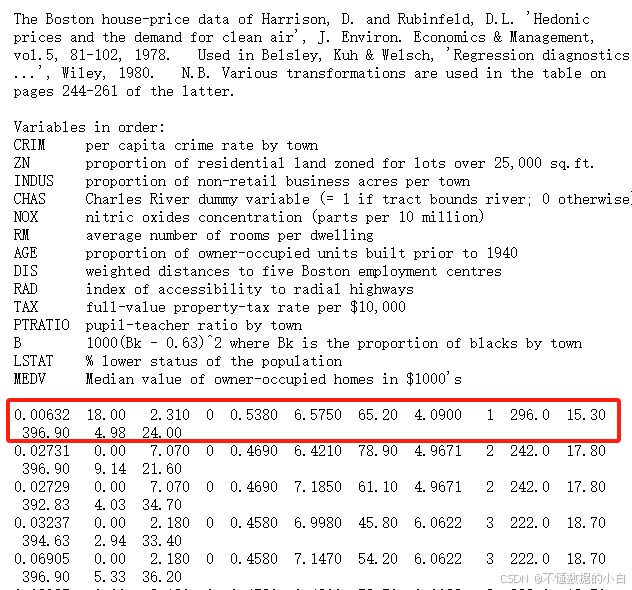
原数据:此处的红框为一条数据,在数据源离分为两行存储,因此这里需要特殊处理下
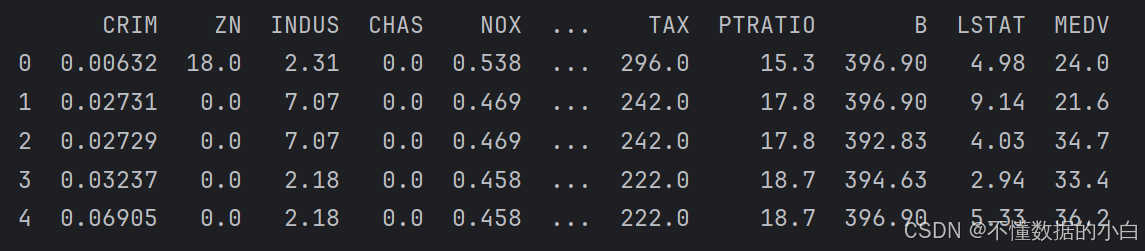
# 通过数据集的源地址读取Boston房价数据 data_url = "http://lib.stat.cmu.edu/datasets/boston" raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None) print(raw_df.head()) # 数据分为多行显示,每一行包含不完整的记录, 需要合并两行才能形成完整的记录。如下图。 data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) #注释:raw_df.values,即将DataFrame转变为numpy #注释:raw_df.values[::2,:]指选取raw_df数组中所有偶数行的所有列 #注释:raw_df.values[::2,:2]指选取raw_df数组中所有奇数行,前两行 #注释:np.hstack(),为numpy中水平堆叠函数,将上述两个数组进行拼接,列方向 target = raw_df.values[1::2, 2] #注释:选取raw_df数组中奇数行的第三列,索引为2,将目标值存储在target中 #拼接特征data和预测目标target complete_data = np.column_stack([data, target]) #注释:numpy中用于拼接的函数,拼接后,data在前面,target在最后 columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV'] # 创建DataFrame,方便数据分析和特征处理 boston = pd.DataFrame(complete_data, columns=columns) #注释:将numpy类型的complete_data转变为DataFrame类型,并添加列名 # print(boston.head())
二.数据分析
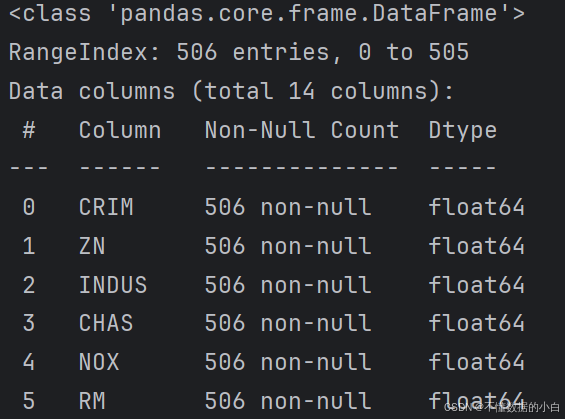
1.查看数据基本信息
#查看数据字段,数据类型等 print(boston.info())
截取部分数据
#注释:可知14个字段都是float64数据类型,数据中没有空值
2.查看数据分布特性
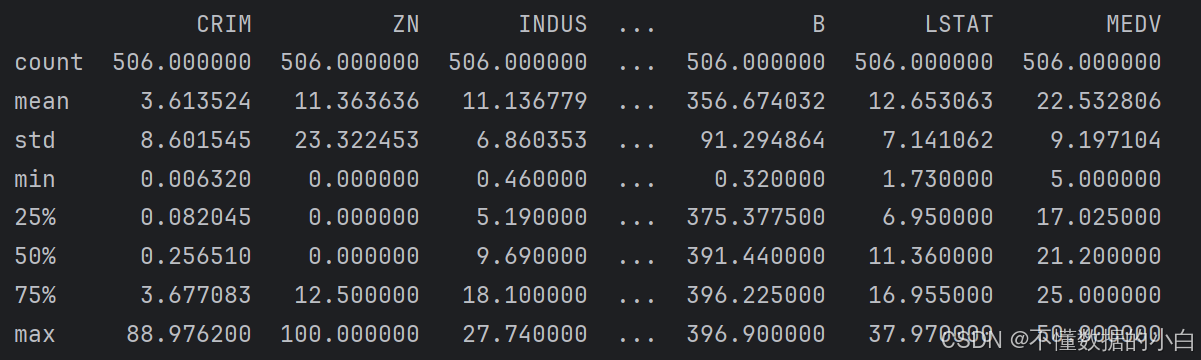
描述性统计:得到每个字段的计数,均值,标准差,最大最小值,分位数等统计特征,可初步识别异常数据
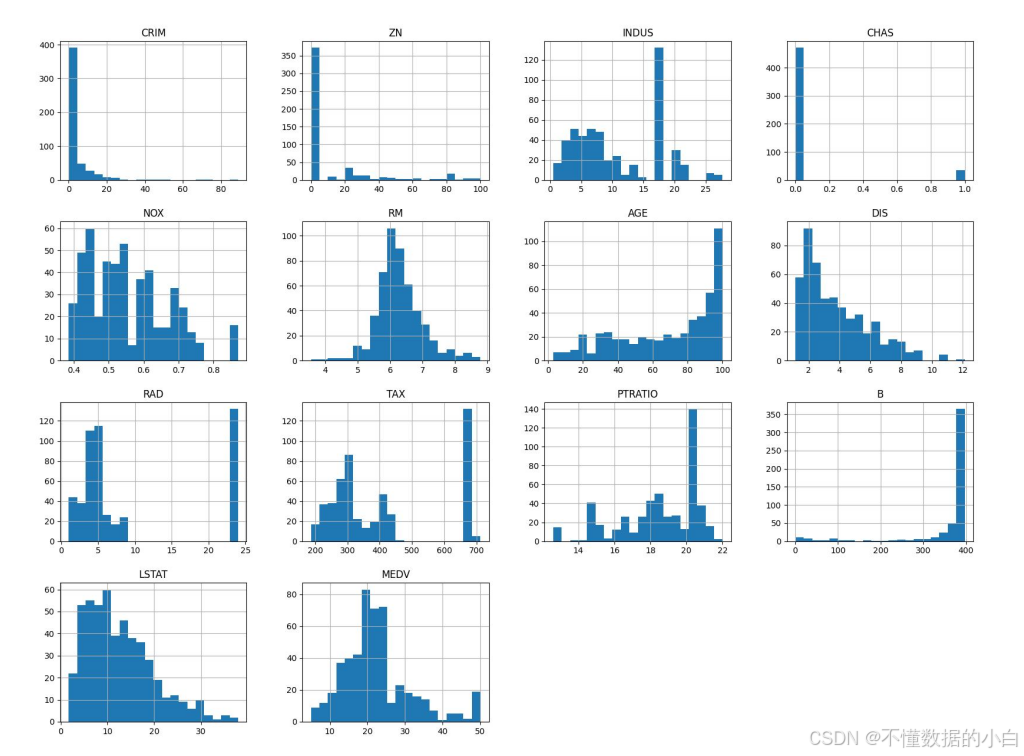
直方图:可以直观的看到数据的分布特征(正态分布,偏态分布等)
#描述性统计 print(boston.describe())
#对每个字段画直方图 boston.hist(bins=20, figsize=(20,15)) #注释:bins 参数指定了直方图的区间数量即20,bins 值越大,区间越窄,直方图越能反映数据的细节 plt.show()
3.特征相关性分析
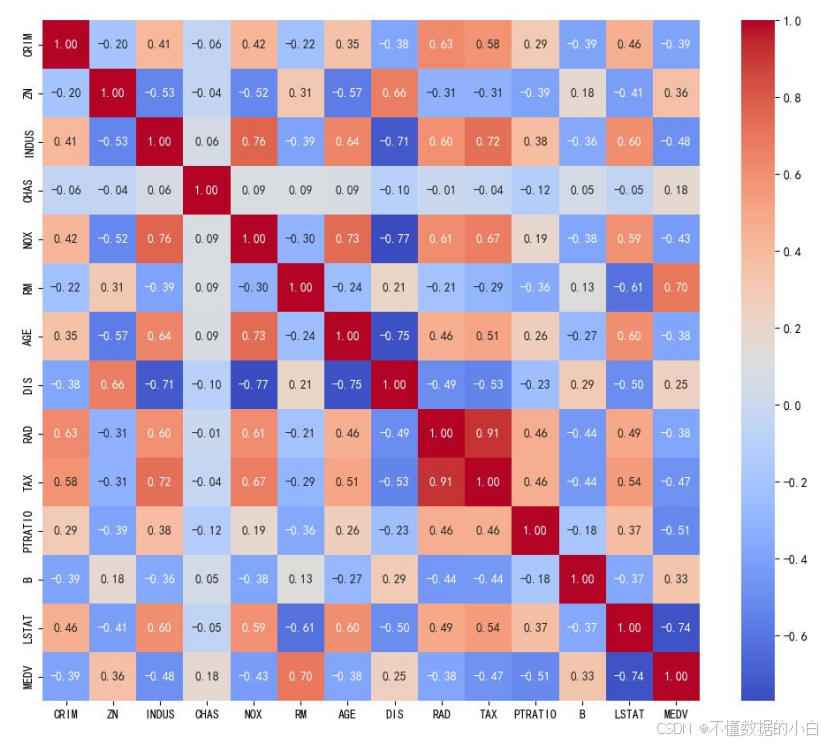
结论:上图是表示目标变量MEDV与各个特征变量之间的相关性,由图可知,MEDV与RM相关系数为0.70,即为中度正相关性,MEDV与LSTAT相关系数为-0.74,称中度负相关
绘制各个特征与房价的关系
# 计算相关矩阵 # corr()是 Pandas 库中的一个方法,用于计算数据框(DataFrame)中各列之间的相关系数矩阵。 # 相关系数用于衡量两个变量之间的线性关系,其值介于 -1 和 1 之间 correlation_matrix = boston.corr() # 可视化相关矩阵 plt.figure(figsize=(12, 10)) sns.heatmap(correlation_matrix, annot=True, fmt=".2f", cmap='coolwarm') #注释:heatmap是绘制热力图,annot=True指会在热力图的方格子上显示数值 # fmt=".2f"指的是小数点位数,cmap指颜色映射,coolwarm指红蓝表示数值,蓝表示负,红表示正 plt.show()
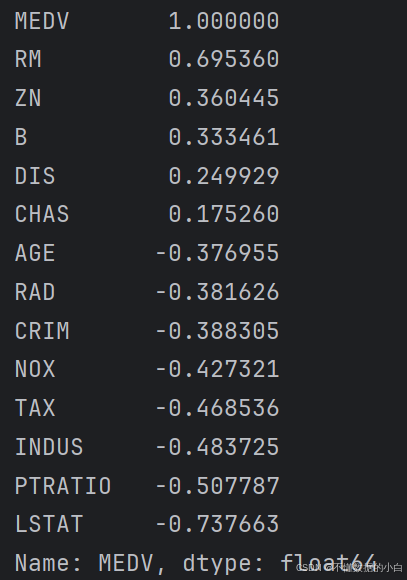
查看与目标变量相关性最高的特征
#查看与目标变量相关性最高的特征变量 correlation_with_target=correlation_matrix['MEDV'].sort_values(ascending=False) #注释:对MEDV列进行降序排列 print(correlation_with_target)
可视化房价与相关性高的特征的关系
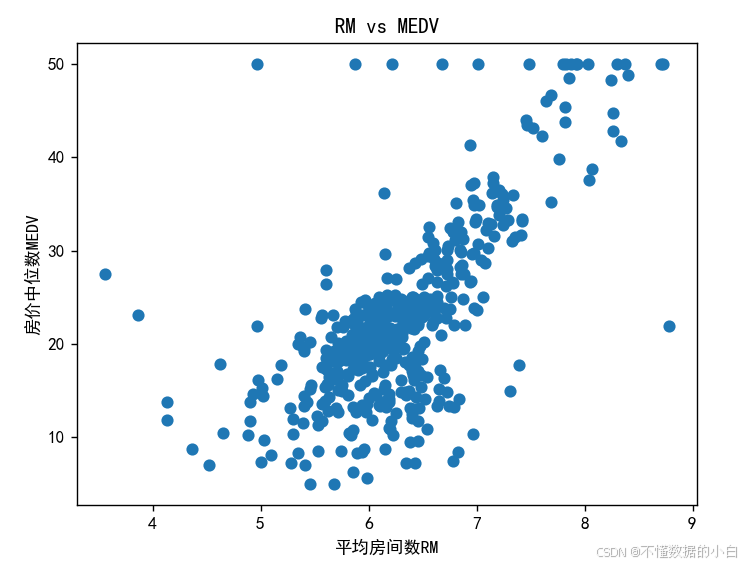
绘制RM与房价的散点图
结论:由散点图可知,RM与MEDV呈现正相关
#分析房间数RM与房价的关系 x1=boston['RM'] y1=boston['MEDV'] plt.scatter(x1,y1) plt.xlabel('平均房间数RM') plt.ylabel('房价中位数MEDV') plt.title('RM vs MEDV') plt.show()
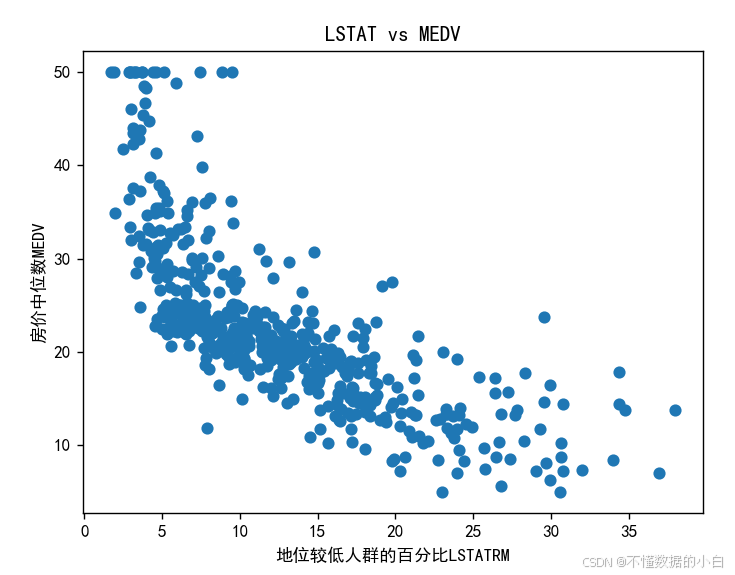
绘制LSTAT与房价的散点图
结论:由散点图可知,LSTAT与MEDV呈现负相关
#分析人口中地位较低人群的百分比LSTATRM与房价的关系 x2=boston['LSTAT'] y2=boston['MEDV'] plt.scatter(x2,y2) plt.xlabel('地位较低人群的百分比LSTATRM') plt.ylabel('房价中位数MEDV') plt.title('LSTAT vs MEDV') plt.show()
4.特征变量的处理
特征选择
选择与目标变量高度相关的特征变量,同时去除共线性特征,从相关性图可以看出['RM','LSTAT','TAX','INDUS','AGE']这几个特征变量与目标变量的相关性绝对值都超过了0.5,正常情况下可以删除其他相关性不强的特征,但Boston数据量较小,这里就不做特征选择
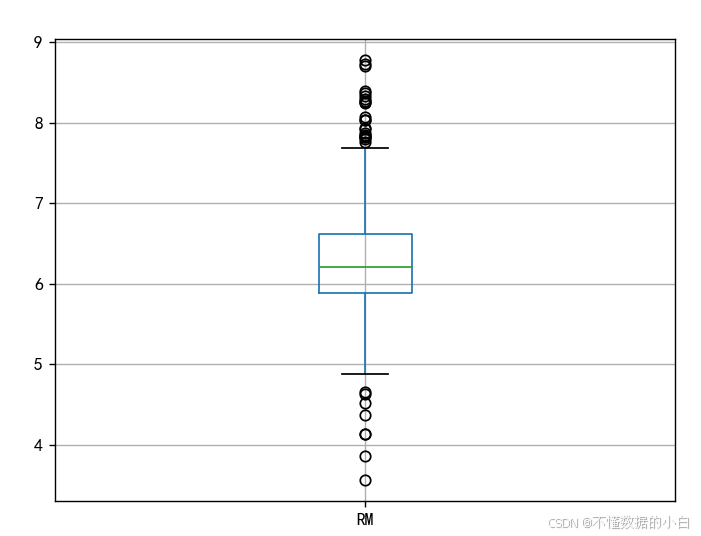
异常值处理(箱线图)
boston.boxplot(column=['RM']) plt.show()
删除异常值,超过上界的正常业务情况可以认为是异常值,异常值可以替换,可以删除
boston.loc[boston['RM']>8,'RM']=8 #注释:将RM列数值超过8的替换为8
三.模型训练和评估
线性回归模型假设多个影响房价的因素和房价之间是线性关系,属于多元线性回归,可以用线性方程来表示
线性回归模型训练的目的是找到一组参数使得模型预测的误差最小,这里面用到了损失函数,最小二乘法,正则化等理论,这里不一 一证明
线性模型
##线性模型 #拆分特征和目标变量 x= boston.drop(columns='MEDV',axis=1) y= boston['MEDV'] #数据分割,拆分出模型训练集和测试数据集 x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.1,random_state=42) #注释:将数据集分为训练集和测试集, #注释:test_size=0.1即测试集数据占比为10%,训练集为90%,random_state=42即用于控制数据分割的随机性 #创建模型 model=LinearRegression() #调用训练模型参数,传入训练数据集 model.fit(x_train,y_train) #模型预测,传入测试数据集,输出预测值 y_pred=model.predict(x_test) # 通过预测值和测试值来计算均方误差 mse = mean_squared_error(y_test,y_pred) # 通过预测值和测试值来计算决定系数 r2=r2_score(y_test,y_pred) # print(f"均方误差 (MSE): {np.sqrt(mse)}") # print(f"决定系数 (R^2): {r2}")
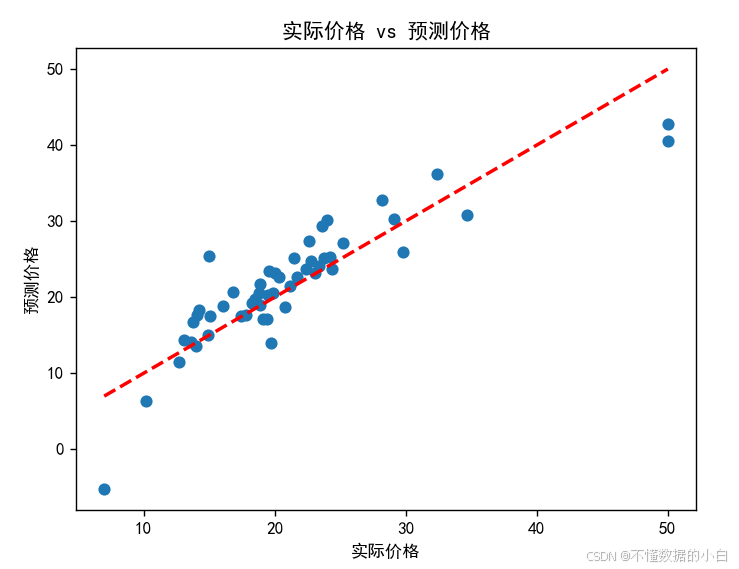
结果可视化
判断实际价格与预测价格的偏差
结论:预测点越接近对角线,说明预测值和实际值,越接近
画散点图判断预测值与测试值偏差 plt.scatter(y_test,y_pred) plt.xlabel('实际价格') plt.ylabel('预测价格') plt.title('实际价格 vs 预测价格') #辅助线 plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', lw=2) plt.show()


















 2267
2267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









