






如何训练计算机视觉模型进行安全帽识别
在许多工业和建筑行业中,确保员工佩戴安全帽是非常重要的。随着技术的进步,使用计算机视觉来自动监测工作场所的安全帽佩戴情况已经变得可行和普遍。这篇博客将探讨如何利用深度学习特别是卷积神经网络(CNN)来训练一个模型,以便自动识别图像中是否有人佩戴安全帽。
第1步:数据收集
收集包括佩戴安全帽和未佩戴安全帽的人员的大量图像。这些数据应涵盖各种类型的安全帽、不同的环境和不同的角度。可以从公开的数据集中获取图像,或者在实际工作环境中进行拍摄。
第2步:数据预处理
- 调整图像尺寸:将所有图像调整为YOLOv5适合的统一尺寸。
- 标注图像:在图像上标记出头部和安全帽的边界框。可以使用如CVAT或LabelImg这样的工具来完成标注。
- 数据增强:通过翻转、旋转、缩放等技术增强数据集,以提高模型对新场景的泛化能力。
第3步:选择模型架构
使用YOLOv5,这是一个针对实时对象检测任务优化的强大模型。根据需要可以修改模型的配置,比如改变层的大小或者增减特定的层,以适应安全帽识别的需求。
第4步:模型训练
使用深度学习框架,如PyTorch,来训练YOLOv5模型。在训练过程中,选择合适的损失函数和优化器(例如使用交叉熵损失和Adam优化器)。同时,确保监控训练过程中的准确率和损失,利用验证集来调整超参数和防止过拟合。
第5步:模型评估与部署
训练完成后,使用测试集评估模型的性能,检验模型是否能有效区分佩戴和未佩戴安全帽的情况。之后,可以将模型部署到实际的应用中,如工作场所的监控摄像头,以实时监测安全帽的佩戴情况。
第6步:持续优化
随着时间推移,可能需要根据新的数据或在新环境中的表现对模型进行调整。持续收集新的数据和反馈,重新训练和优化模型,确保其持续的有效性。
总结
利用计算机视觉进行安全帽识别可以大大提高工作场所的安全监测效率。虽然这个过程可能挑战重重,需要大量的数据和精心的模型调试,但一旦成功实施,其带来的安全益处是显而易见的。通过不断的学习和适应,这些系统将变得更加智能和有效。
对安全帽识别项目进行测试
在优化好的yolov5模型里进行训练后会得到一个权重文件helmet_head.pt
将这个权重文件放入优化好的yolov5文件夹内
执行下面的命令,打开本地摄像头进行测试: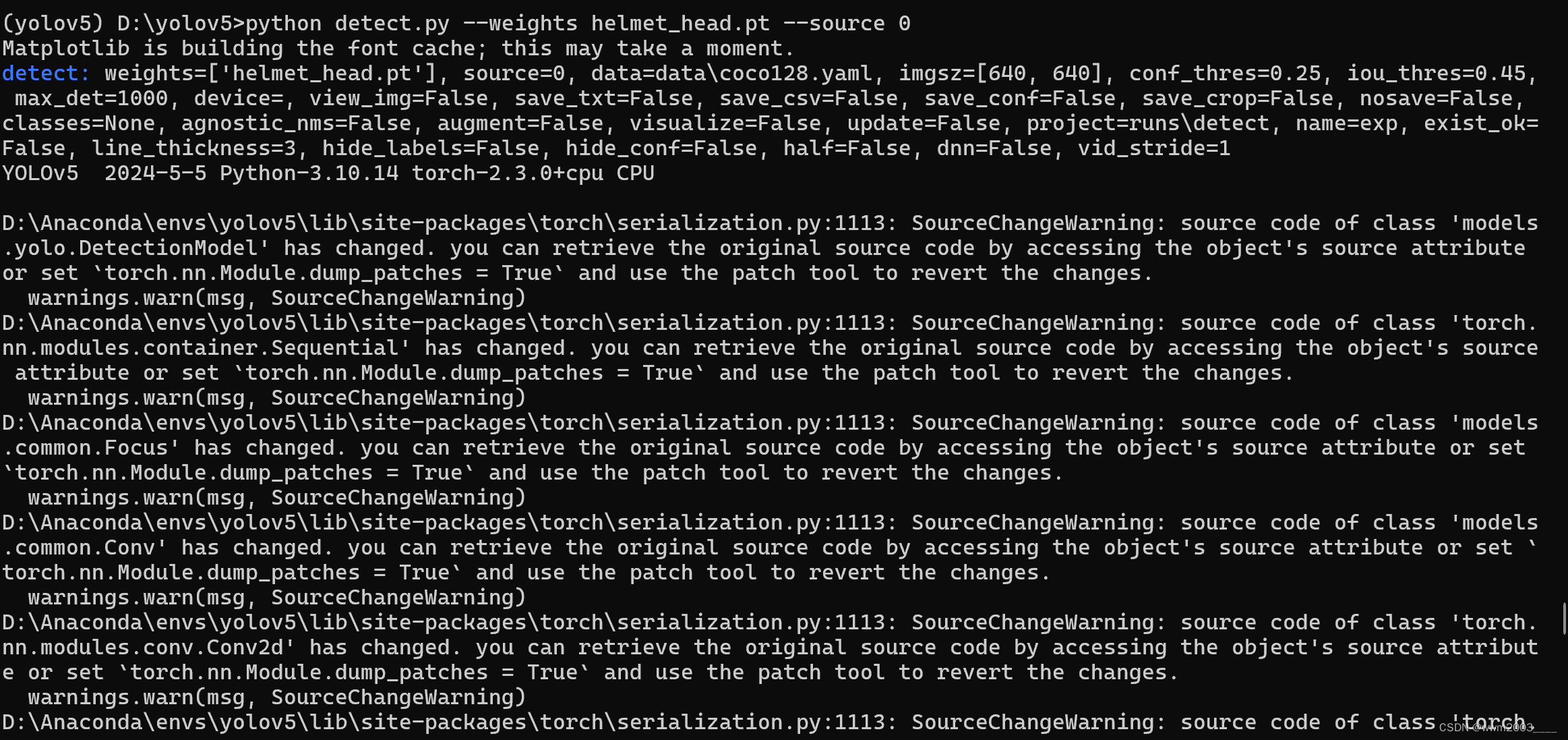
运行成功后即可发现摄像头时时打开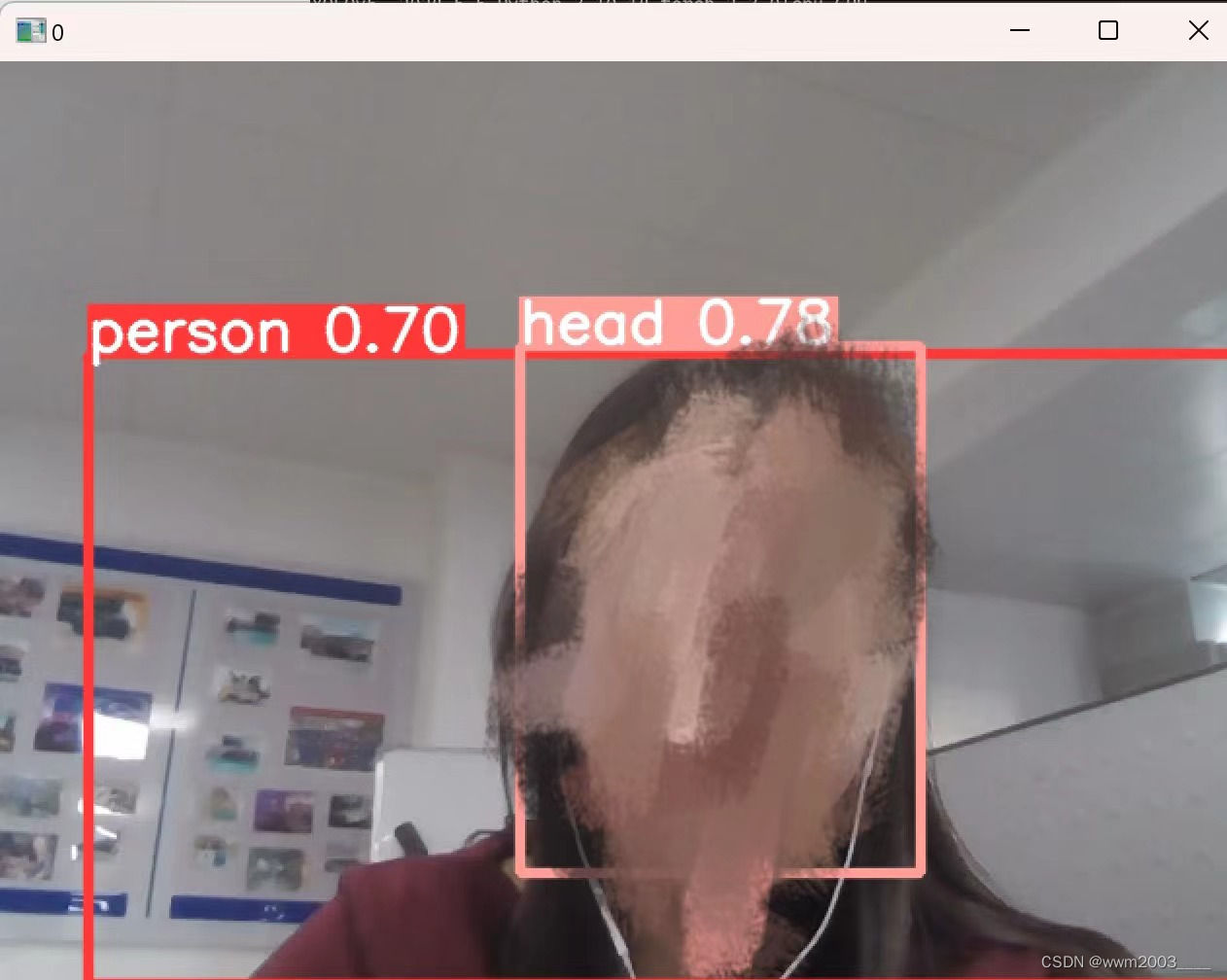
看到这里说明检测成功
语音识别的本地部署
一、安装ffmpeg
首先官网下载
下载完成后配置环境变量并重启电脑
二、配置anaconda环境
conda create -n whisper python=3.9
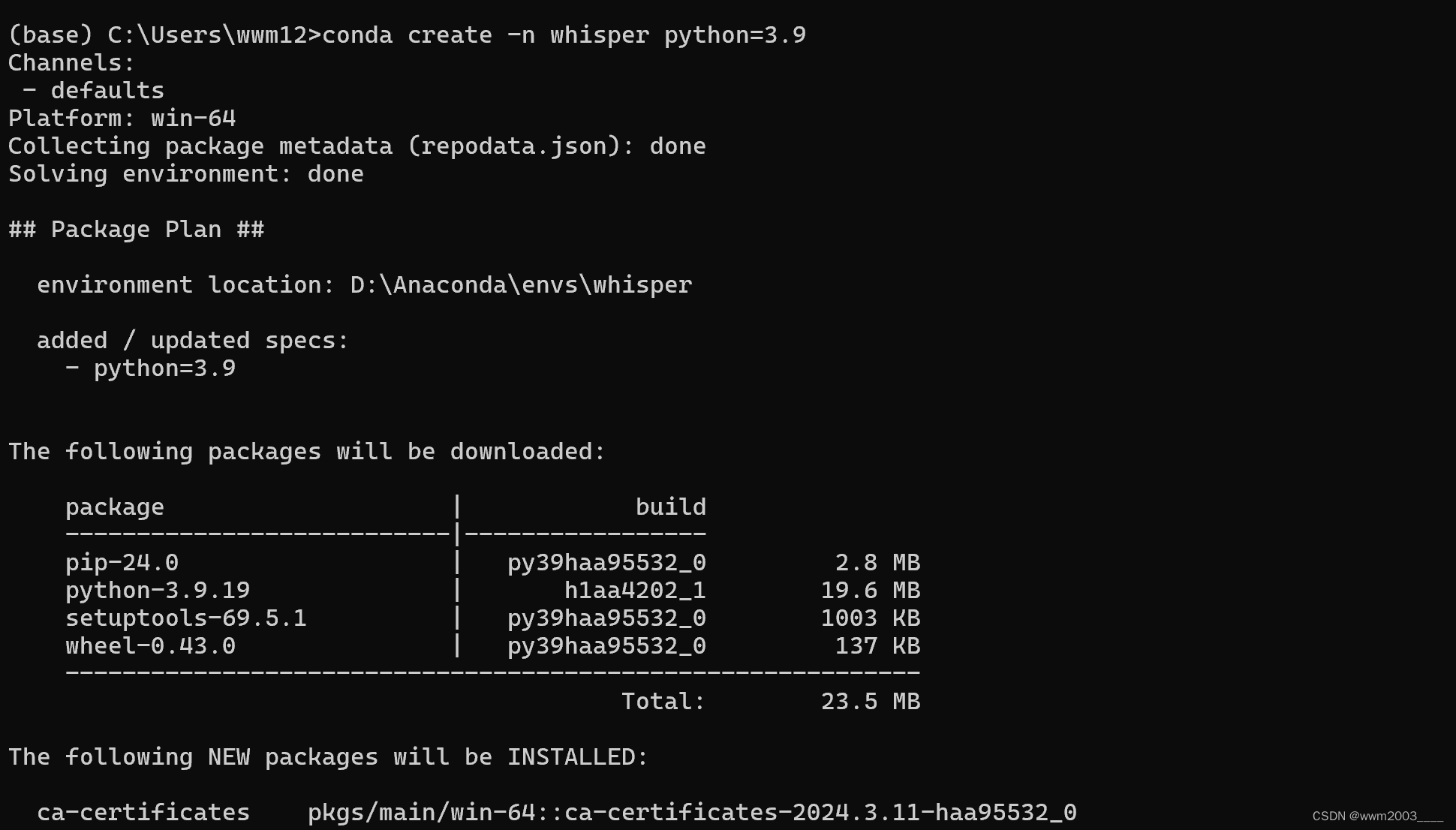
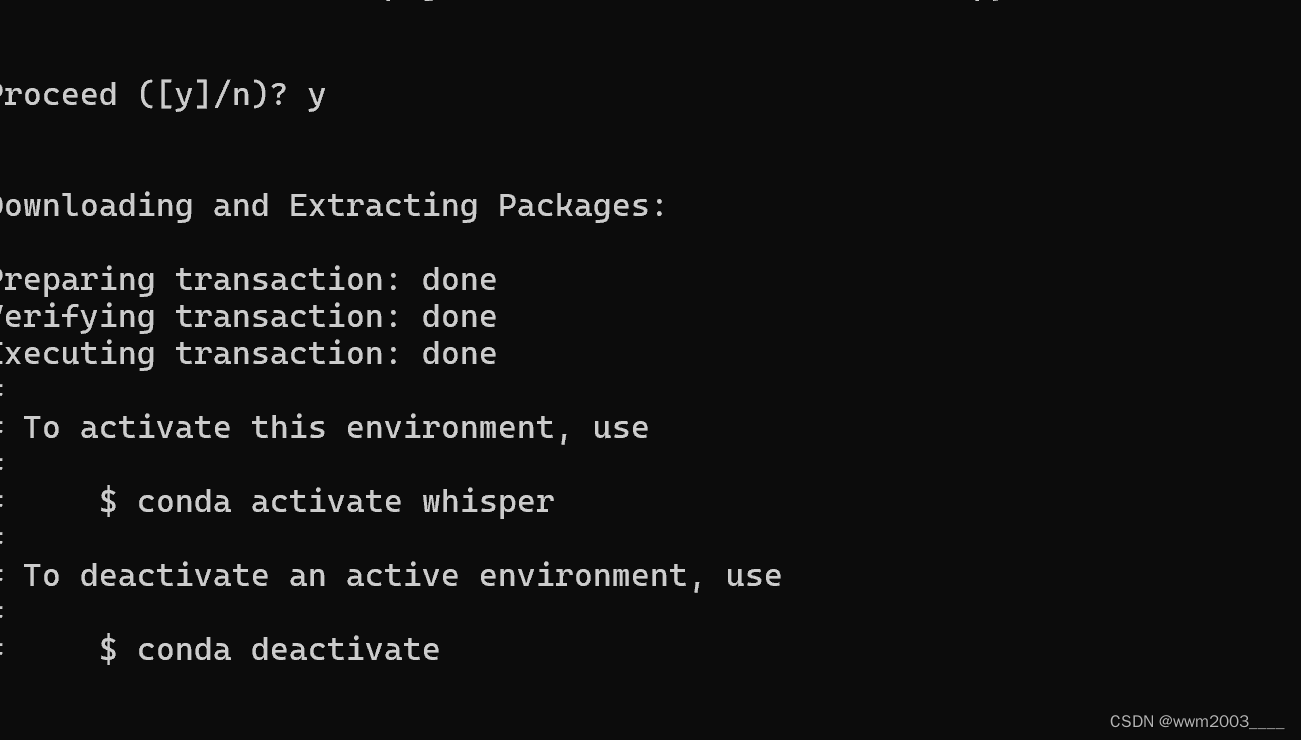
三、下载自己版本的cuda并在虚拟环境安装
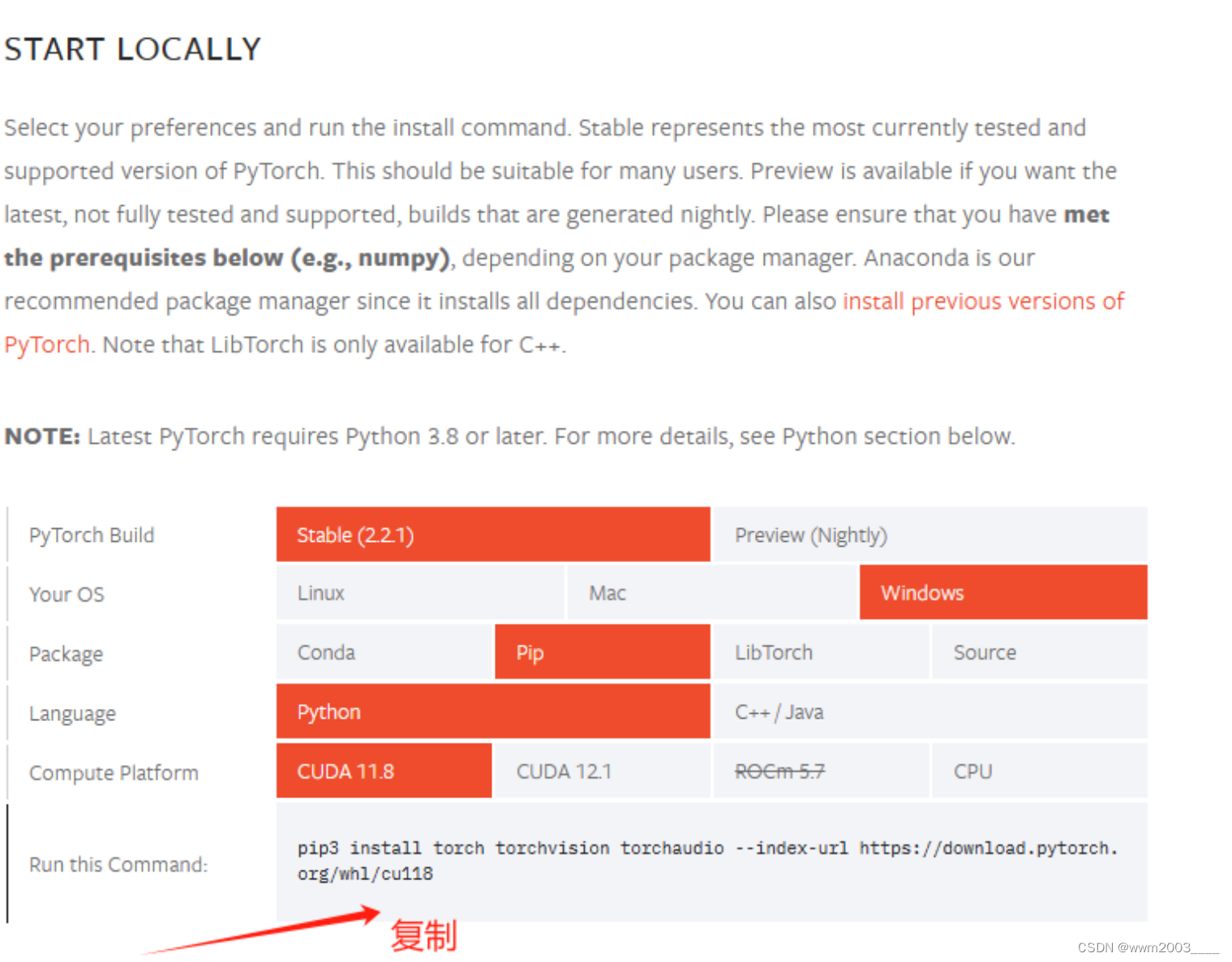
四、安装whisper
运行命令:pip install git+https://github.com/openai/whisper.git
语音识别本地测试
部署完成后进行测试
测试结果:
1.部署状态:系统部署成功,无报错信息。
Deployment complete with the following status:
- Status: SUCCESS
- Error Messages: None
- Warnings: None
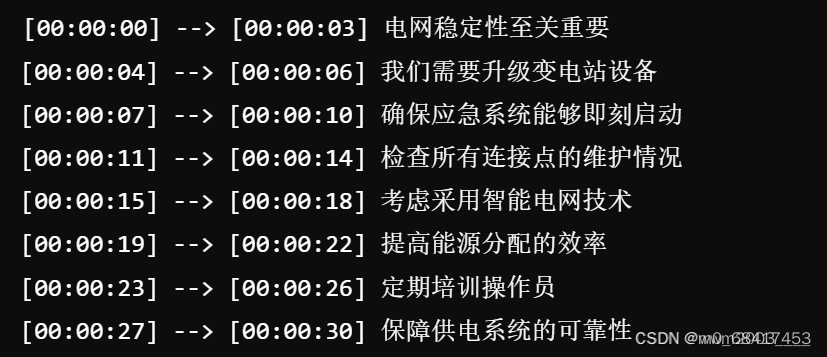
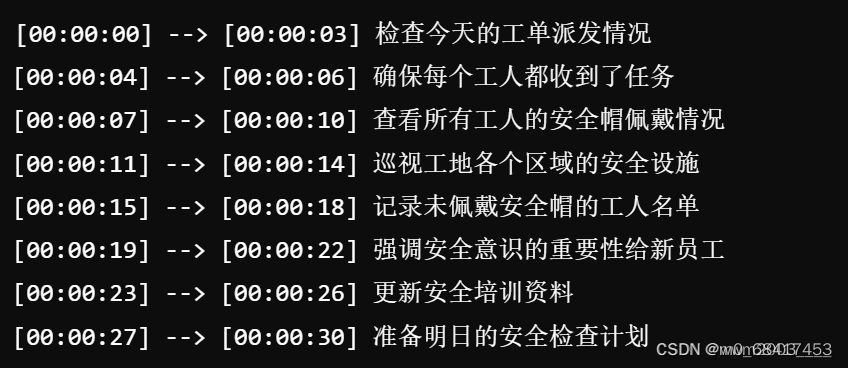
2.识别准确率: 识别出的文本与原始语音内容的准确率高
a)检查日常用语

b)检查有关电网系统用语
c)检查有关本次项目实训用语















 2428
2428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









