







实验四 使用pandas实现数据描述
一、实验目的
练习使用pands完成成绩数据的统计计算、分组与聚合和可视化
二、实验内容
根据下面的内容完成以下任务:
(1) 任务一:成绩数据的统计计算

(2) 任务二:成绩数据的分组与聚合
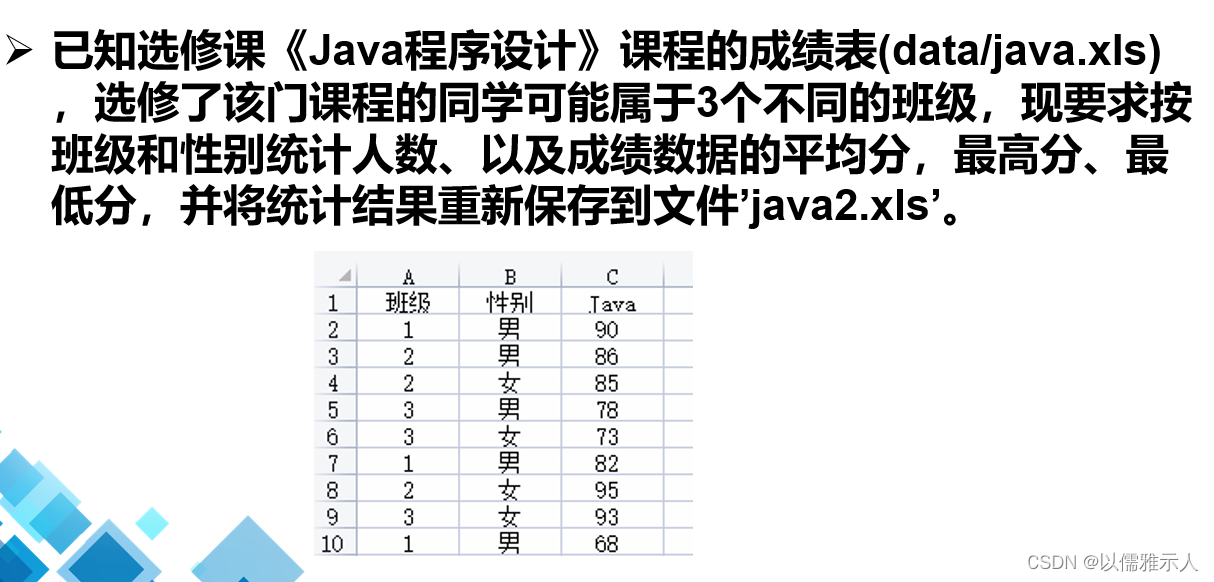
(3)任务三:成绩数据的可视化
 三、实验代码
三、实验代码
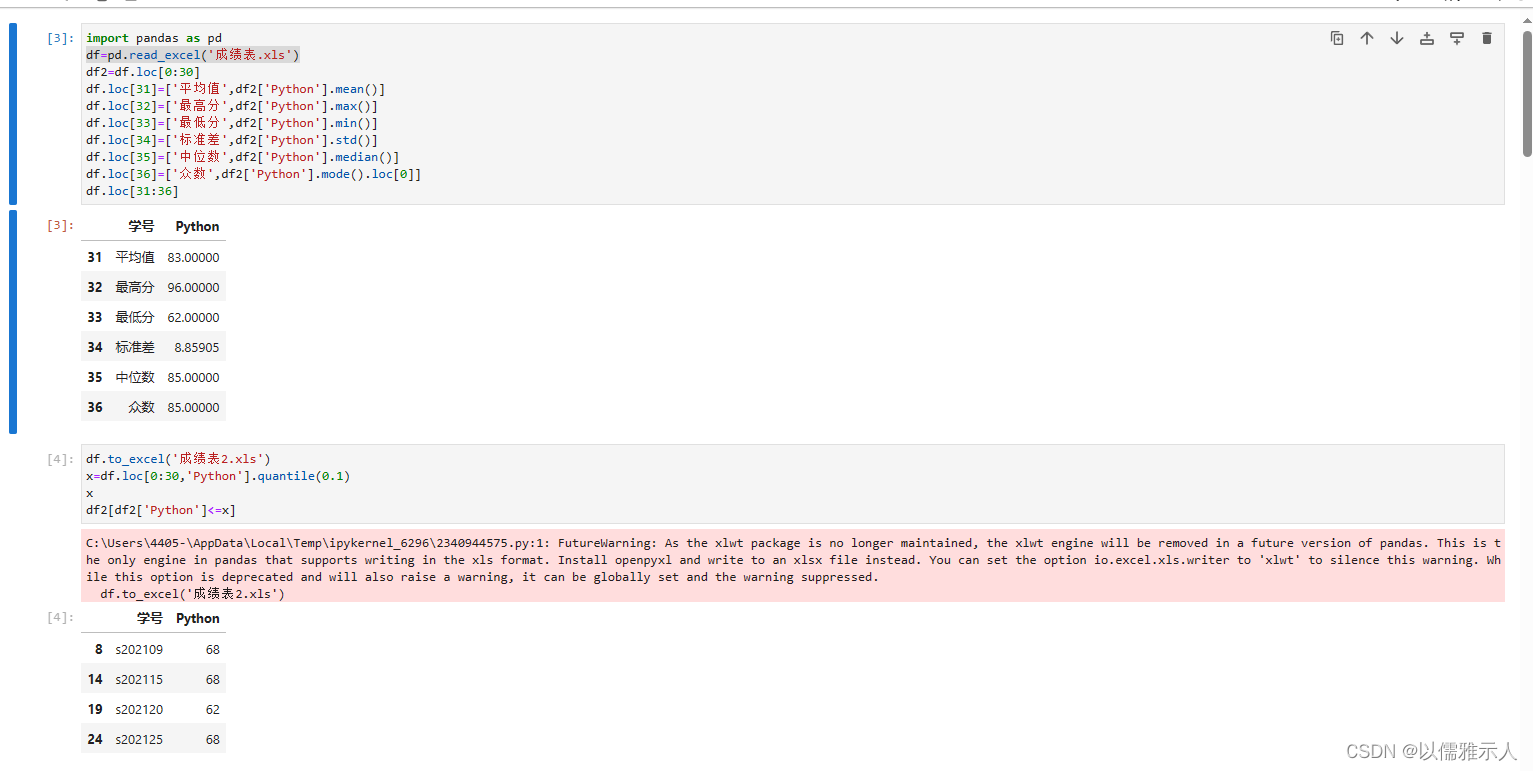
任务一:
import pandas as pd
df=pd.read_excel('成绩表.xls')
df2=df.loc[0:30]
df.loc[31]=['平均值',df2['Python'].mean()]
df.loc[32]=['最高分',df2['Python'].max()]
df.loc[33]=['最低分',df2['Python'].min()]
df.loc[34]=['标准差',df2['Python'].std()]
df.loc[35]=['中位数',df2['Python'].median()]
df.loc[36]=['众数',df2['Python'].mode().loc[0]]
df.loc[31:36]
df.to_excel('成绩表2.xls')
x=df.loc[0:30,'Python'].quantile(0.1)
x
df2[df2['Python']<=x]
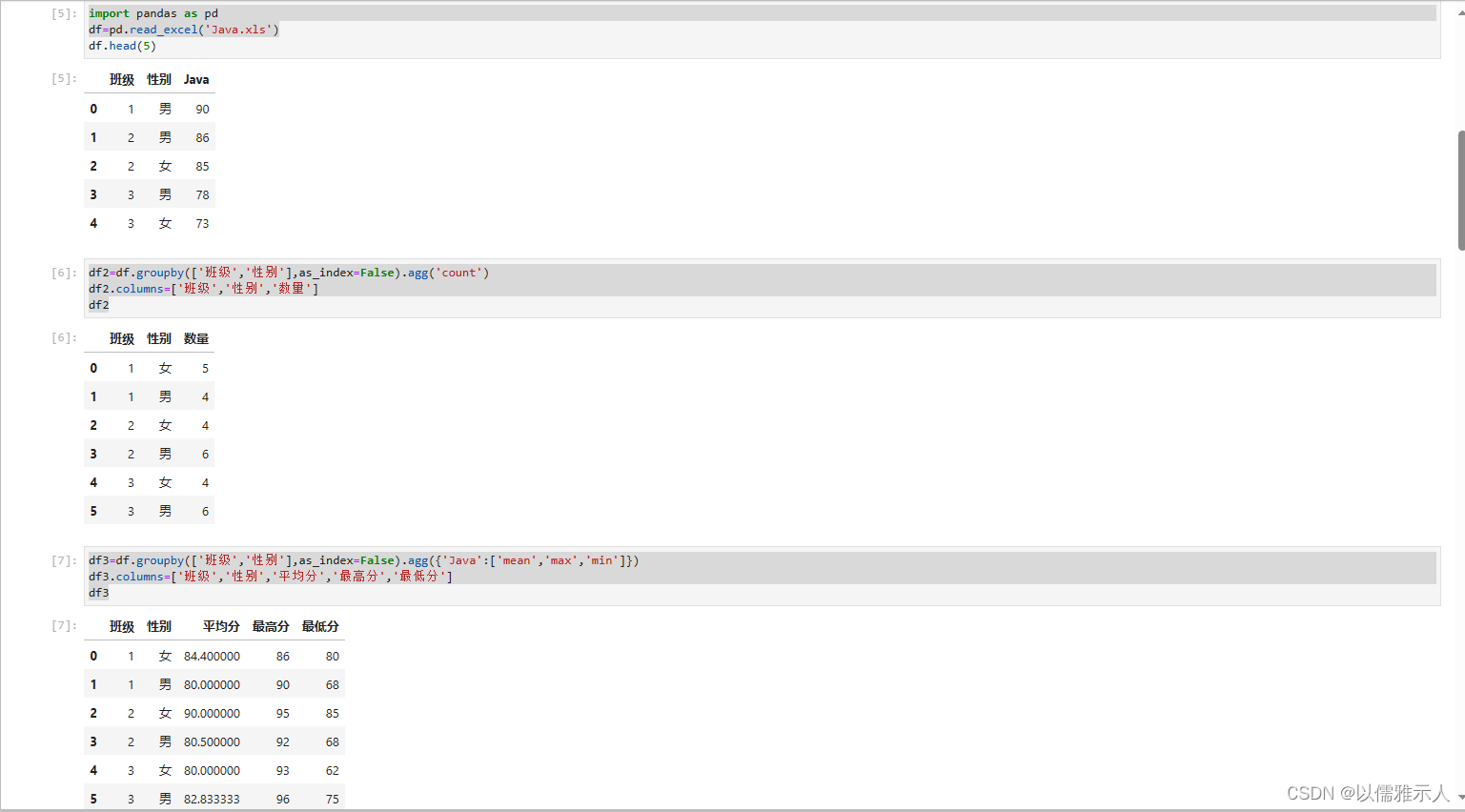
任务二:
import pandas as pd
df=pd.read_excel('Java.xls')
df.head(5)
df2=df.groupby(['班级','性别'],as_index=False).agg('count')
df2.columns=['班级','性别','数量']
df2
df3=df.groupby(['班级','性别'],as_index=False).agg({'Java':['mean','max','min']})
df3.columns=['班级','性别','平均分','最高分','最低分']
df3
cont=pd.merge(df2,df3,how='inner')
cont['平均分']=cont['平均分'].round(2)
cont
cont.to_excel('Java2.xls',index=None)
任务三:
import pandas as pd
df=pd.read_excel('期末考试成绩表.xls')
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
df2=pd.DataFrame({'科目':['Python','Java'],
'平均分': [df['Python'].mean(), df['Java'].mean()],
'最高分':[df['Python'].max(),df['Java'].max()],
'最低分':[df['Python'].min(),df['Java'].min()]}
,columns=['科目','平均分','最高分','最低分'])
df2
df2.plot(x='科目',y=['平均分','最高分','最低分'],kind='bar',grid=True,title="期末成绩")
def grade(score):
if score>=90:
return '优秀'
elif score>=80:
return '良好'
elif score>=70:
return '中等'
elif score>=60:
return '及格'
else:
return '不及格'
df3=pd.DataFrame({'Python等级':df['Python'].apply(lambda x:grade(x)),
'Java等级':df['Java'].apply(lambda x:grade(x))})
df_python=df3.groupby('Python等级',as_index=False).count()
df_python.index=['中等','优秀','及格','良好']
df_python.drop('Python等级',axis=1,inplace=True)
df_python.rename(columns={'Java等级':'Python等级'},inplace=True)
df_python
df_java=df3.groupby('Java等级',as_index=False).count()
df_java.index=['中等','优秀','及格','良好']
df_java.drop('Java等级',axis=1,inplace=True)
df_java.rename(columns={'Java等级':'Python等级'},inplace=True)
df_java
df_grade=pd.concat([df_Python,df_java],axis=1)
df_grade.plot(kind='pie', autopct='%.0f%%', subplots=True, fontsize=10, layout=(1,2), figsize=(9,4), legend=False)四、实验结果
(1) 任务一
(2) 任务二
(3) 任务三



五、出现的问题和解决方法
出现的问题:在编译任务三代码的时候,Python以及java的平均值显示不出来。
解决办法:把'平均分':[format(df['Python'].mean(),'.2f'), format(df['Java'].mean(),'.2f')],改为'平均分': [df['Python'].mean(), df['Java'].mean()]即可正常显示出平均值的柱形图。
六、实验心得
通过本次实验我学会了 使用pands完成数据的统计计算、分组与聚合和可视化操作,让我更加深入学会了基于python对数据处理的强大功能。















 2583
2583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









