







上一篇文章我们讲解了插入排序,选择排序以及交换排序,此篇文章着重于交换排序中的快速排序的优化以及归并排序、计数排序的讲解。
正文开始:
1. 快速排序的优化
1.1 三数取中
上一篇文章我们了解到,快速排序每次都会取第一个元素作为key,但是当数组接近有序的时候,此时快速排序的时间复杂度会退化成 O(N^2) ,因此,为了解决这个问题,我们可以运用三数取中的方法来优化,代码如下:
int GetMidNum(int* a, int begin, int end) { int mid = (begin + end) / 2; if (a[begin] < a[end]) { if (a[end] < a[mid]) { return end; } else if (a[mid] < a[begin]) { return begin; } else { return mid; } } // end > begin else { if (a[begin] > a[mid]) { return begin; } else if (a[end] < a[mid]) { return end; } else { return mid; } } }这时每次快排都会把数组分为两组数量几乎相等的两部分,时间复杂度就会变成O(N*logN)
1.2 挖坑法
我们了解到,Hoare的快速排序需要注意很多细节,处理起来比较繁琐,因此还有其他方法来实现快速排序,其中之一就是挖坑法:
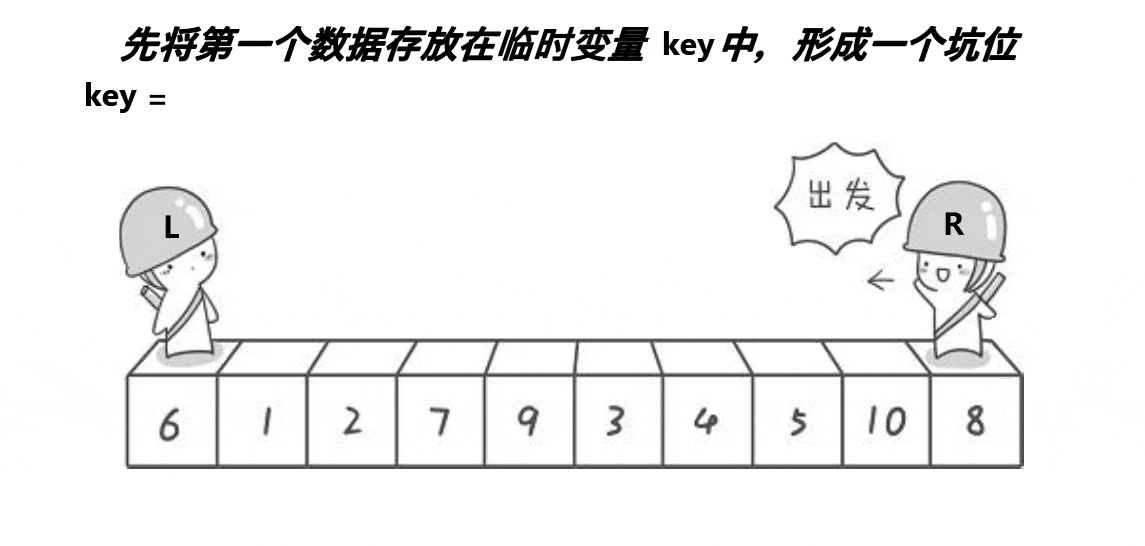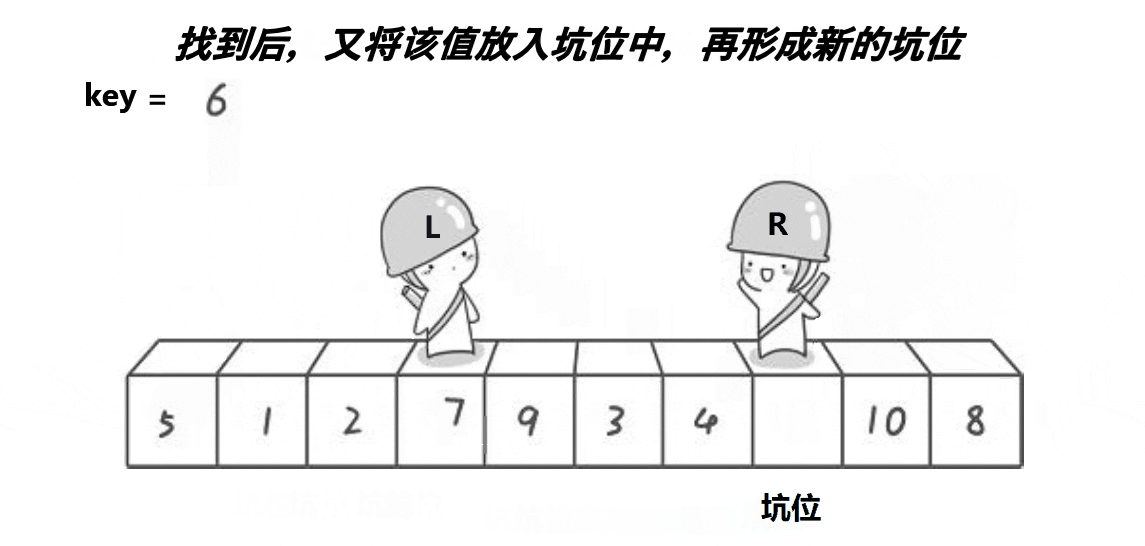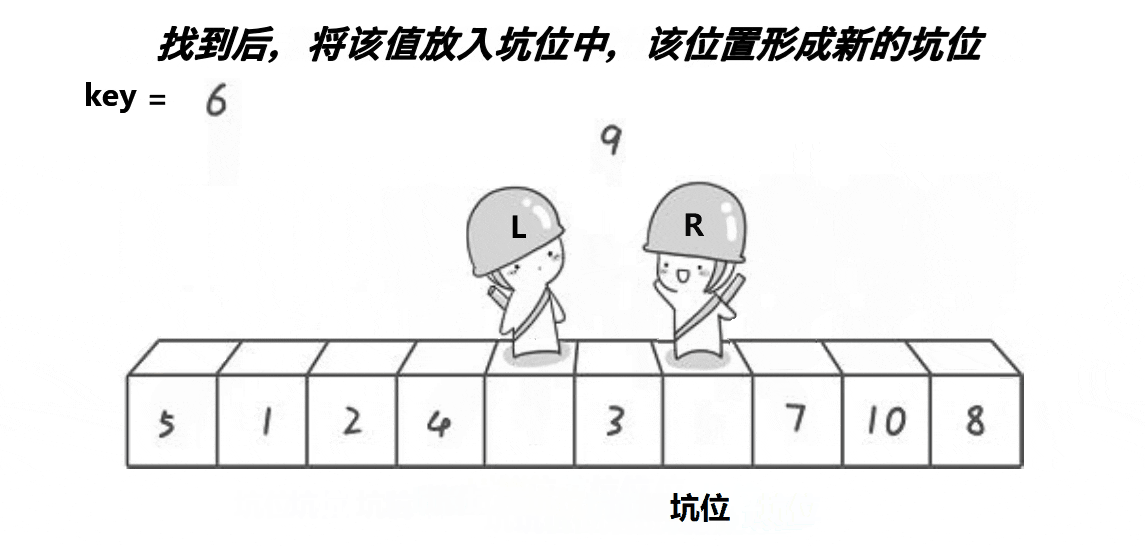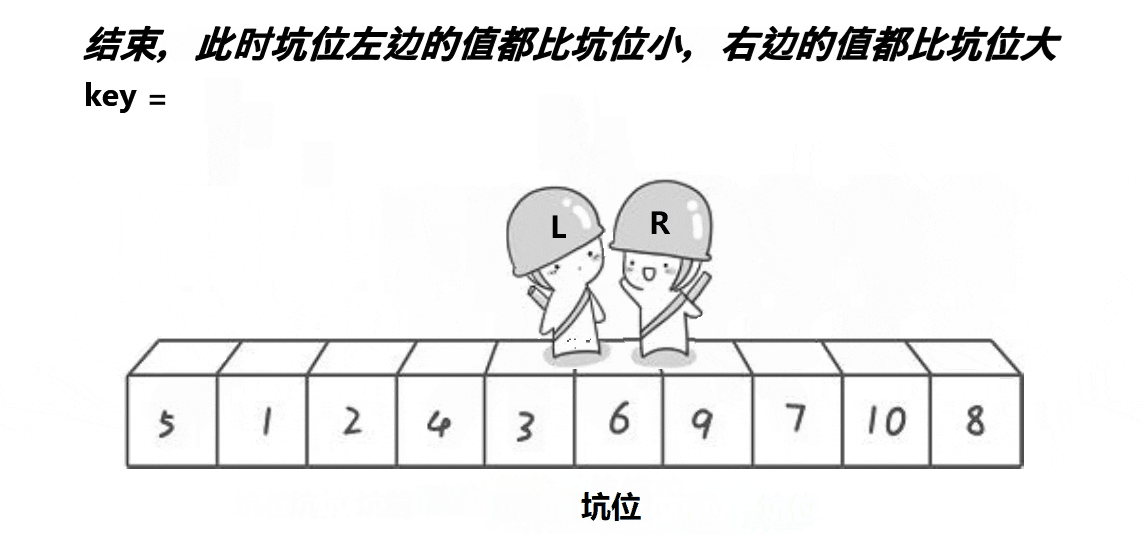
- 首先将首元素作为key,并将key所在位置的值放在tmp中,此时“坑”就相当于是首元素;
- 从右向左找比tmp小的值,找到就将此位置的值填到坑里,此位置就变为“坑”;
- 从左向右找比tmp大的值,找到就将此位置的值填到坑里,此位置就变为“坑”;
- 一直到左右相遇,把tmp放到坑中,就完成第一次快排,之后继续递归。
动图如下:
代码如下:
//挖坑 int PartSort2(int* a, int begin, int end) { int mid = GetMidNum(a, begin, end); Swap(&a[begin], &a[mid]); int holei = begin; int tmp = a[begin]; while (begin < end) { while (begin < end && a[end] >= tmp) { --end; } a[holei] = a[end]; holei = end; while (begin < end && a[begin] <= tmp) { ++begin; } a[holei] = a[begin]; holei = begin; } a[holei] = tmp; int keyi = holei; return keyi; } void QuickSort(int* a, int begin, int end) { if (begin >= end) { return; } int keyi = PartSort2(a, begin, end); QuickSort(a, begin, keyi - 1); QuickSort(a, keyi + 1, end); }

1.2 双指针法
另一种方法就是双指针法:
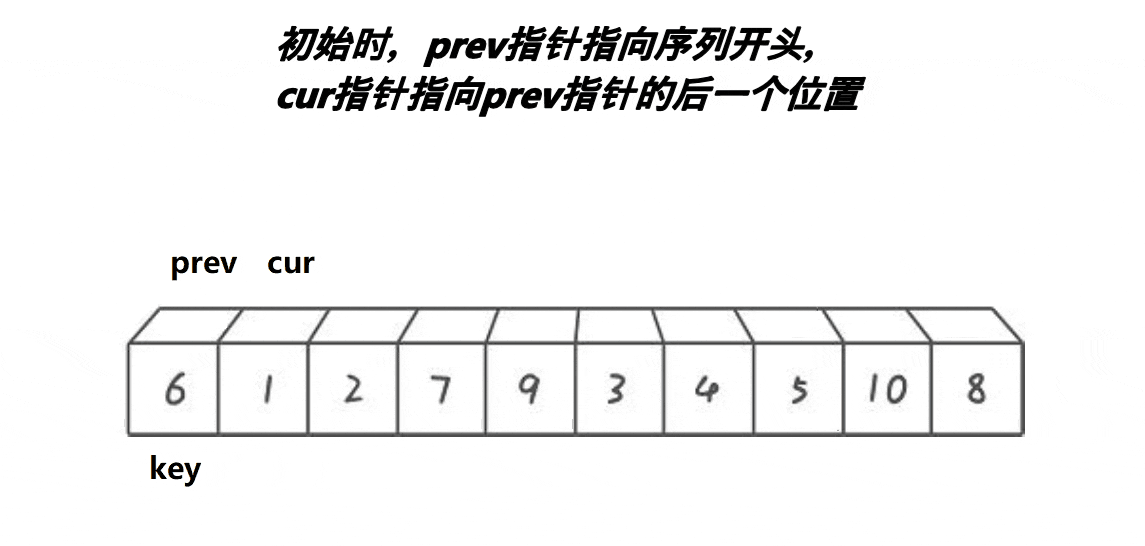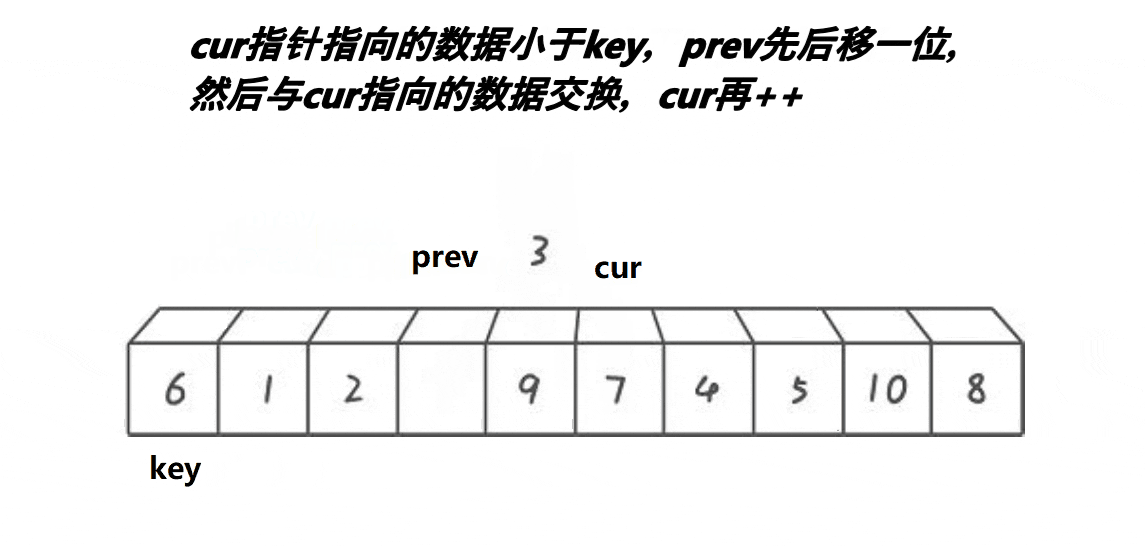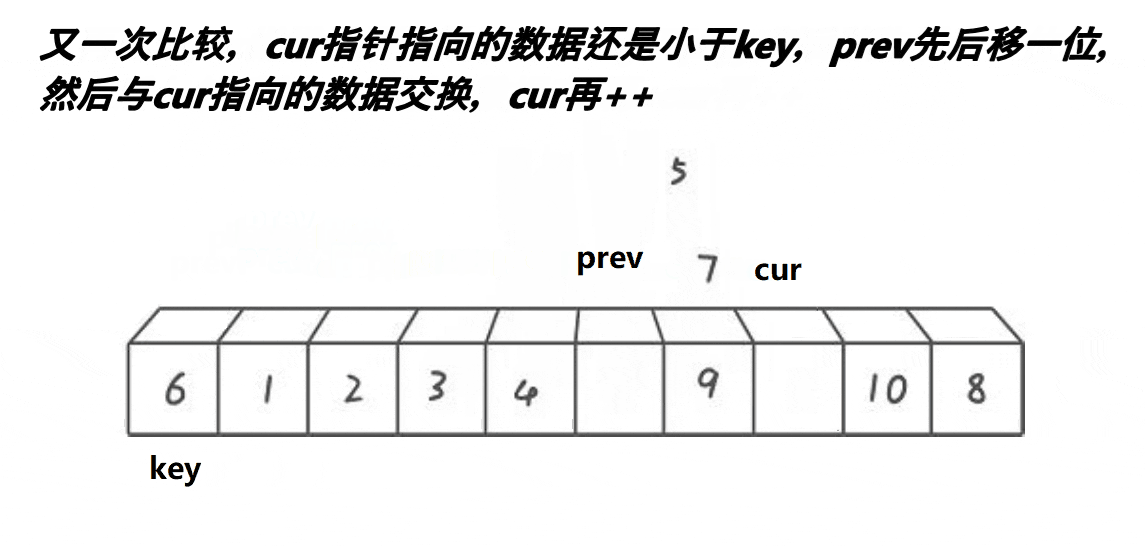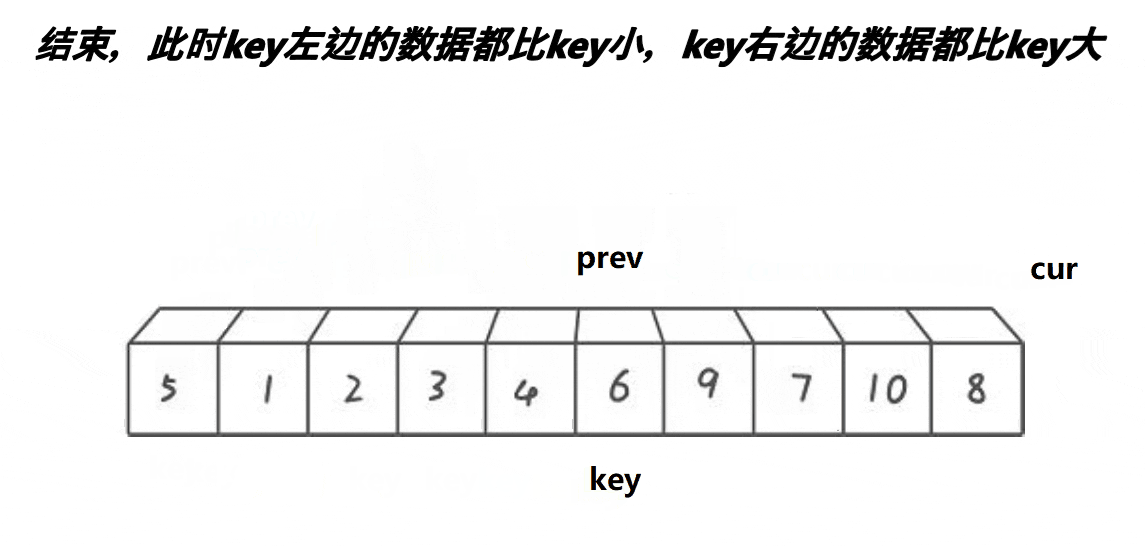
- 将首元素的下标当作key;
- 定义两个下标cur 和 prev,cur先走,找比key小的值;
- 找到之后prev再走一步,交换cur和prev所在位置的值;
- 直到cur超过数组的范围n,就停止,此时prev所在的位置就当成key,并进行递归。
动图如下:
代码如下:
//双指针 int PartSort3(int* a, int begin, int end) { int mid = GetMidNum(a, begin, end); Swap(&a[begin], &a[mid]); int keyi = begin; int prev = begin; int cur = prev + 1; while (cur <= end) { if (a[cur] < a[keyi] && (++prev) != cur) { Swap(&a[prev], &a[cur]); } ++cur; } Swap(&a[keyi], &a[prev]); keyi = prev; return keyi; } void QuickSort(int* a, int begin, int end) { if (begin >= end) { return; } int keyi = PartSort3(a, begin, end); QuickSort(a, begin, keyi - 1); QuickSort(a, keyi + 1, end); }运行截图如下:

1.3 非递归版本的快排
我们可以用栈来模拟非递归版本的快排:
- 首先将最后一个元素和第一个元素的下标入栈(注意顺序);
- 然后取两次Top(一个作为begin,另一个作为end),并Pop掉,进行第一次快排;
- 之后,将end、keyi + 1、keyi - 1、begin 依次入栈,再进行接下来的快排。
代码如下:
void QuickSortNonR(int* a, int begin, int end) { ST st; STInit(&st); STPush(&st, begin); STPush(&st, end); while (!STEmpty(&st)) { int right = STTop(&st); STPop(&st); int left = STTop(&st); STPop(&st); int keyi = PartSort3(a, left, right); if (keyi + 1 < right) { STPush(&st, keyi + 1); STPush(&st, right); } if (left < keyi - 1) { STPush(&st, left); STPush(&st, keyi - 1); } } STDestroy(&st); }运行结果:

注意以上的方法只是对Hoare的方法进行了优化,对于时间复杂度和空间复杂度没有什么质的飞跃,平均时间复杂度依旧是 O(N*logN),平均空间复杂度依旧是 O(logN)。
2. 归并排序
归并排序是一种经典的分治算法,它的基本思想是将一个大的数组划分为两个相等大小的子数组,然后递归地对子数组进行排序,最后将已经排好序的子数组合并成一个有序的数组。
以下是归并排序的基本步骤:
分割: 将原始数组分成两个子数组,这个过程是递归的,直到每个子数组只包含一个元素。
排序: 递归地对每个子数组进行排序。
合并: 合并两个已排序的子数组,生成一个新的有序数组。
递归终止条件: 当数组的大小为1时,不再继续递归,直接返回。
归并排序的关键在于合并两个已排序的子数组。合并过程中,需要比较两个子数组中的元素,并按照顺序将它们合并到一个临时数组中。最后,将临时数组中的元素拷贝回原始数组的相应位置,完成合并。
动图如下:
2.1 归并排序的递归版本
代码如下:
void _MergeSort(int* a, int begin, int end, int* tmp) { if (begin >= end) { return; } int mid = (begin + end) / 2; // 分成两组,最后会变成一个一个比较 _MergeSort(a, begin, mid, tmp); _MergeSort(a, mid + 1, end, tmp); int begin1 = begin, end1 = mid; int begin2 = mid + 1, end2 = end; int i = begin1; while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] <= a[begin2]) { tmp[i++] = a[begin1++]; } else { tmp[i++] = a[begin2++]; } } while (begin1 <= end1) { tmp[i++] = a[begin1++]; } while (begin2 <= end2) { tmp[i++] = a[begin2++]; } memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1)); } void MergeSort(int* a, int begin, int end) { int* tmp = (int*)malloc(sizeof(int) * (end - begin + 1)); if (tmp == NULL) { perror("malloc fail!"); exit(-1); } _MergeSort(a, begin, end, tmp); }运行结果:

2.2 归并排序的非递归版本
代码如下:
void MergeSortNonR(int* a, int n) { int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("malloc fail!"); exit(-1); } int gap = 1; while (gap < n) { int i = 0; for (i = 0; i < n; i += 2 * gap) { int begin1 = i, end1 = i + gap - 1; int begin2 = i + gap, end2 = i + 2 * gap - 1; // end1 和 begin2 越界,不需要处理 if (end1 >= n || begin2 >= n) { break; } // end2 越界, 需要拷贝 if (end2 >= n) { end2 = n - 1; } int j = i; while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] <= a[begin2]) { tmp[j++] = a[begin1++]; } else { tmp[j++] = a[begin2++]; } } while (begin1 <= end1) { tmp[j++] = a[begin1++]; } while (begin2 <= end2) { tmp[j++] = a[begin2++]; } //一定要再这里拷贝,如果在内循环外拷贝可能出现随机数。 memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1)); } gap *= 2; } }运行如下:

归并排序的特性总结:
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
3. 计数排序
思想:计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。 操作步骤:
- 统计相同元素出现次数
- 根据统计的结果将序列回收到原来的序列中
代码如下:
void CountSort(int* a, int n) { int max = a[0]; int min = a[0]; for (int i = 0; i < n; ++i) { if (a[i] < min) { min = a[i]; } if (a[i] > max) { max = a[i]; } } int range = max - min + 1; // 注意这里的加1 int* count = (int*)calloc(range,sizeof(int)); if (count == NULL) { perror("calloc error"); exit(-1); } for (int j = 0; j < n; j++) { count[a[j] - min]++; } for (int k = 0; k < range; k++) { while (count[k]--) { printf("%d ", k + min); } } }运行结果:

计数排序的特性总结:
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(MAX(N,Range))
- 空间复杂度:O(Range)














 2895
2895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









