







一、前言
开始这个项目前,你需要具备什么知识:
1.tensorflow框架的使用
2.文本预处理
3.循环神经网络的理论
二、数据预处理
我们先来看看数据集是什么样子的。

两个E之间为一段对话,M为某个角色说的话。
第一步则是提取出每段对话的问题和回答。
代码如下:
import re
import numpy as np
datapath="source_data.conv"
data_list=[]
def filter_non_chinese(text):
chinese_pattern = re.compile('[^\u4e00-\u9fa5]') # 匹配非汉字字符的正则表达式
return chinese_pattern.sub('', text)
with open(datapath,'r',encoding='utf-8') as f:
complete_dialog=[]
for line in f:
line=line.strip('\n')
ls=line.split()
if ls[0]=='E':
data_list.append(complete_dialog)
complete_dialog=[]
if ls[0]=='M':
s=''.join(ls[1:])
s1=filter_non_chinese(s)
# print(s1)
complete_dialog.append(s1)看看这个data_list最终的样子:

每个列表都是一段对话,且在提取的过程中我们还用正则表达式过滤掉了非中文字符。
第二步,每句话都需要一个开始标志和一个结束标志,不然计算机是不知道一句完整的话是什么样子的。
代码如下:
questions=[]
answers=[]
for dialog in data_list:
if len(dialog)<2:
continue
if len(dialog)%2!=0:
dialog=dialog[:-1]
for i in range(len(dialog)):
if i %2==0:
questions.append("<start> "+" ".join(dialog[i])+" <end>")
else:
answers.append("<start> "+" ".join(dialog[i])+" <end>")处理后的样子:

一共有两个列表,questions存放问题语句,answers存放回答语句,且都是一一对应的。
第三步则是文本编码了,传统的独热编码是满足不了文本编码的,在tensorflow中提供了一种文本编码类Tokenizer,在自然语言领域内非常实用。该类允许使用两种方法向量化一个文本语料库: 将每个文本转化为一个整数序列(每个整数都是词典中标记的索引); 或者将其转化为一个向量,其中每个标记的系数可以是二进制值、词频、TF-IDF权重等。
代码如下:
from tensorflow import keras
def tokenize(datas):
tokenizer=keras.preprocessing.text.Tokenizer(filters="")
tokenizer.fit_on_texts(datas)
voc_li=tokenizer.texts_to_sequences(datas)
voc_li=keras.preprocessing.sequence.pad_sequences(voc_li,padding='post')
return voc_li,tokenizer三、人机对话模型的构建
模型的关键在于编码器、注意力机制和编码器,接下来我们来构建它们吧。
在构建之前我们引入了循环神经网络:
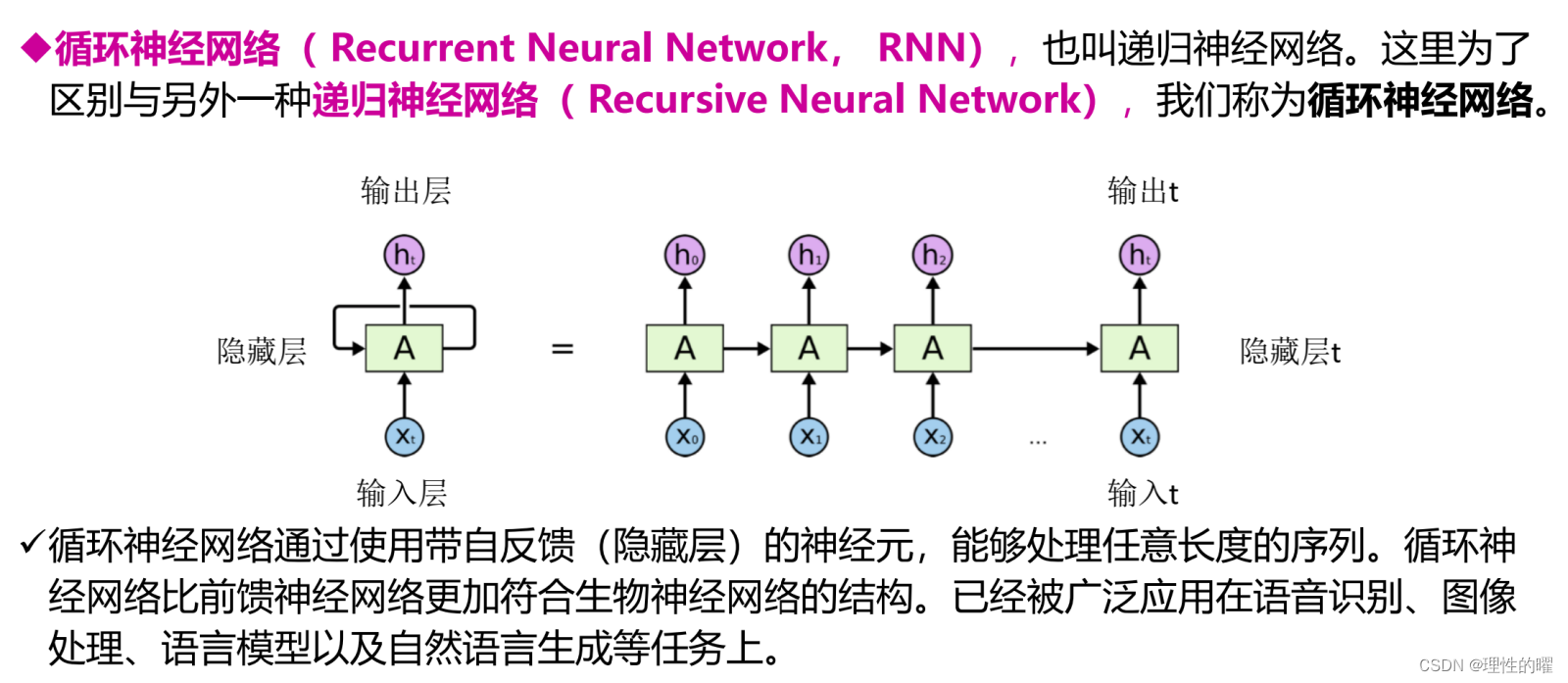
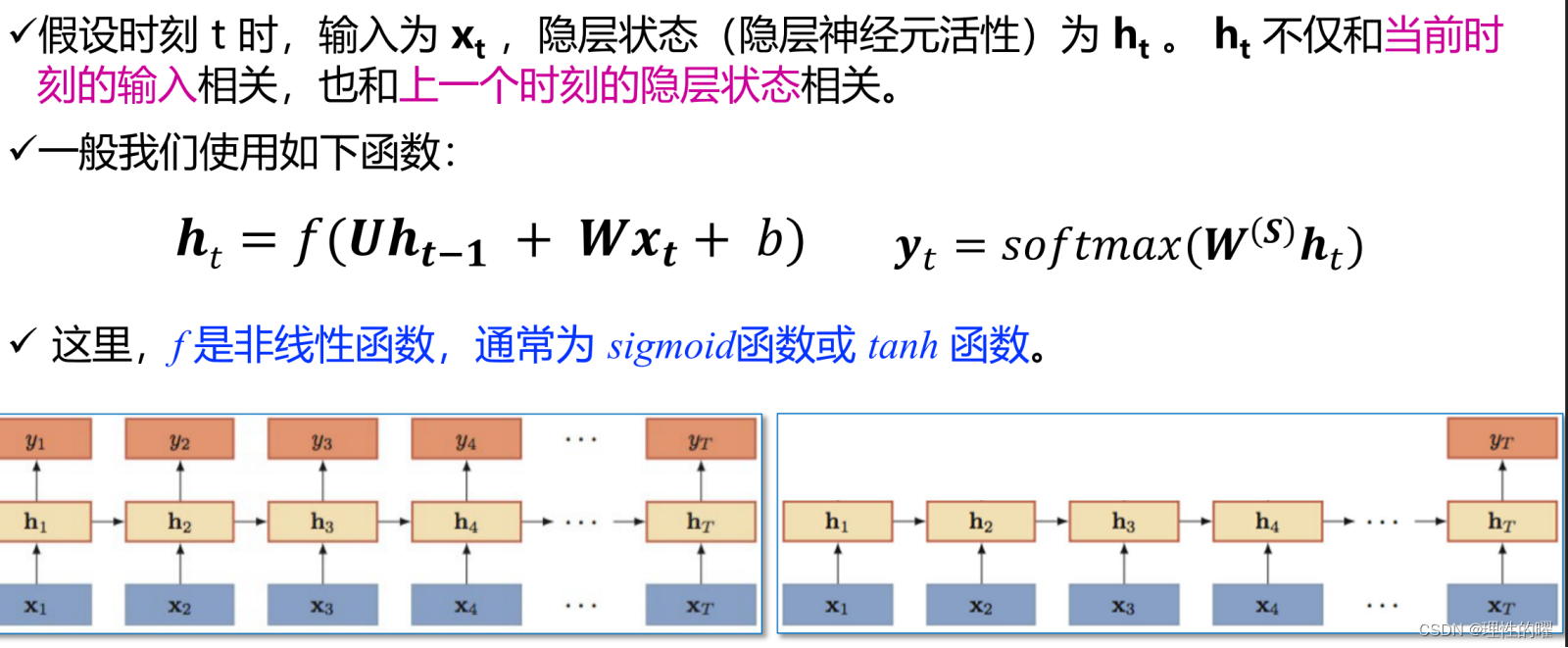
传统的循环神经网络是满足不了的,随着时间的推移,前面的输入对后面的输出的影响可能不是很大,我们就此引入LSTM。
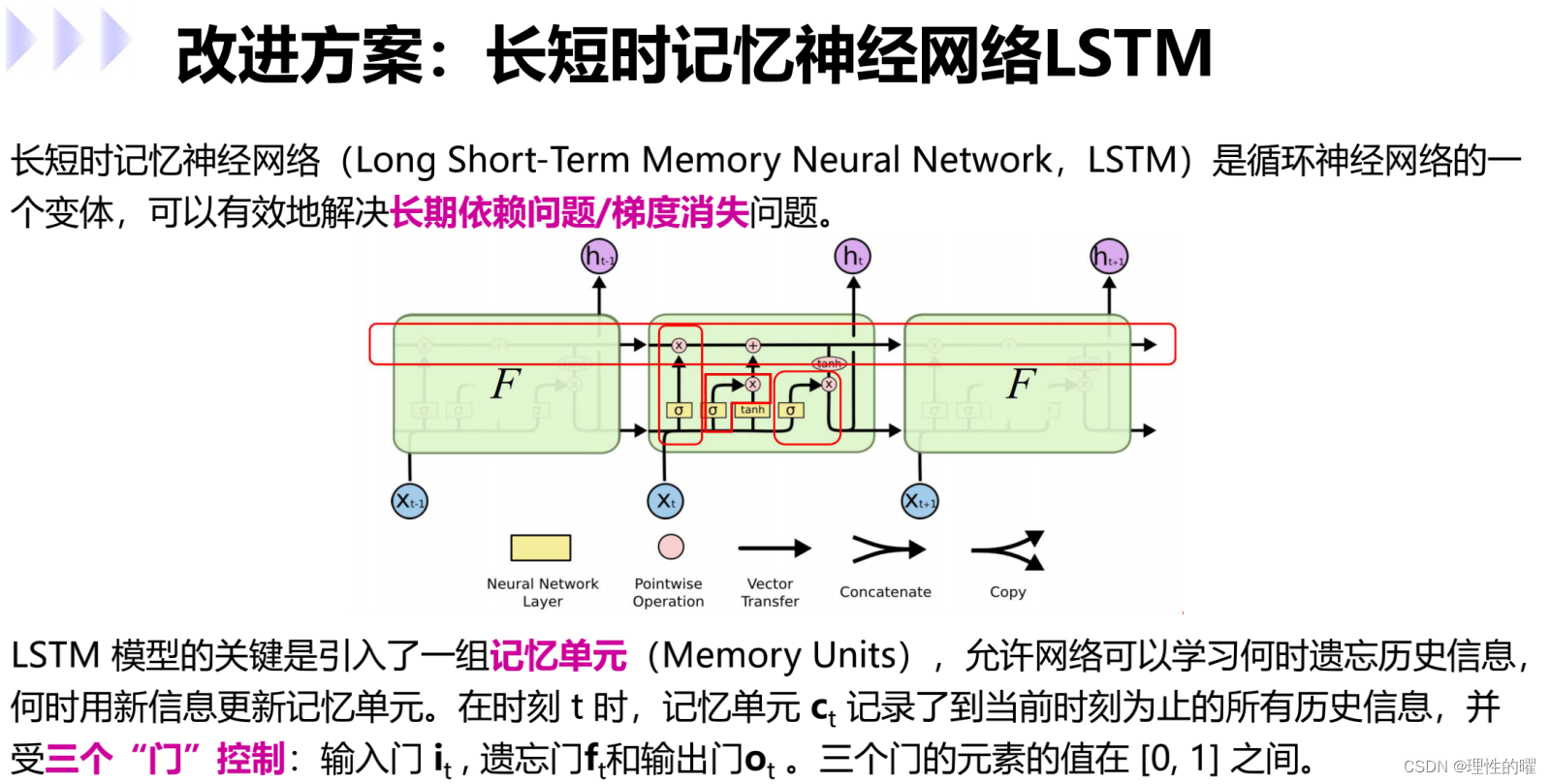
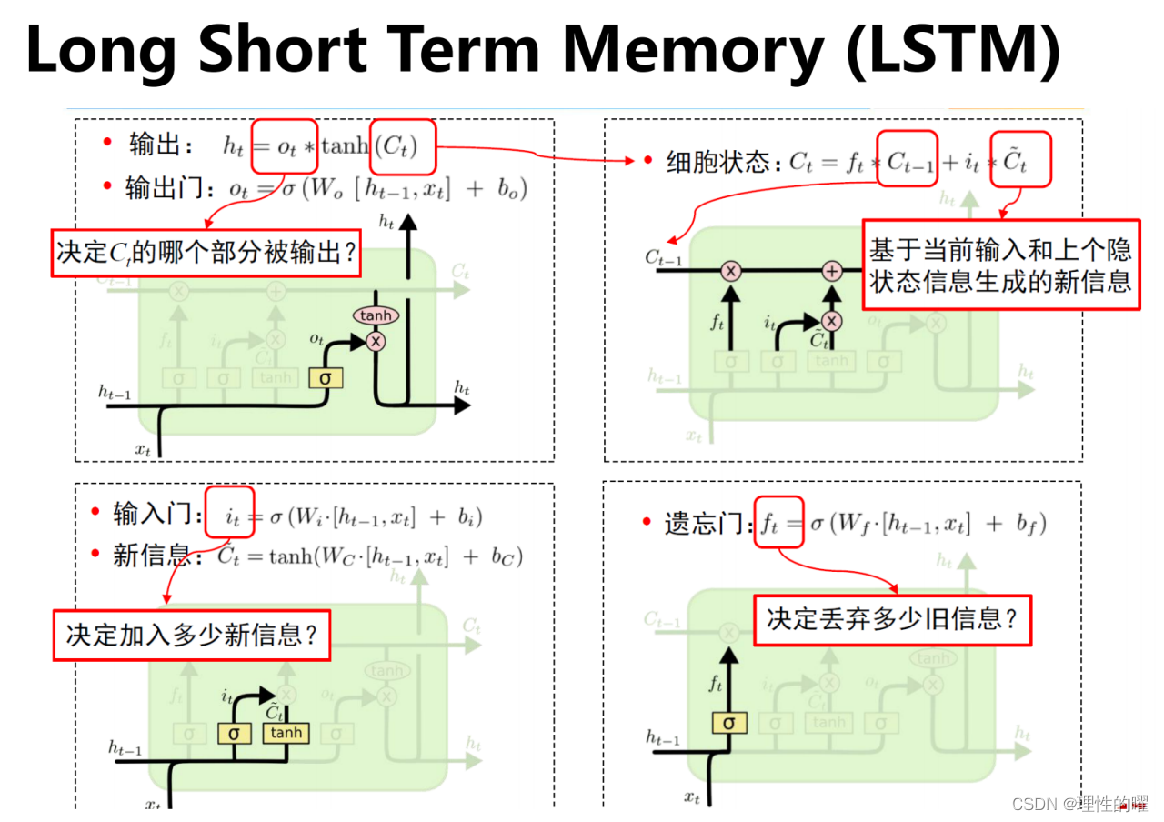
随着科学的发展,LSTM的优化版本GRU诞生了,它们有什么不同:
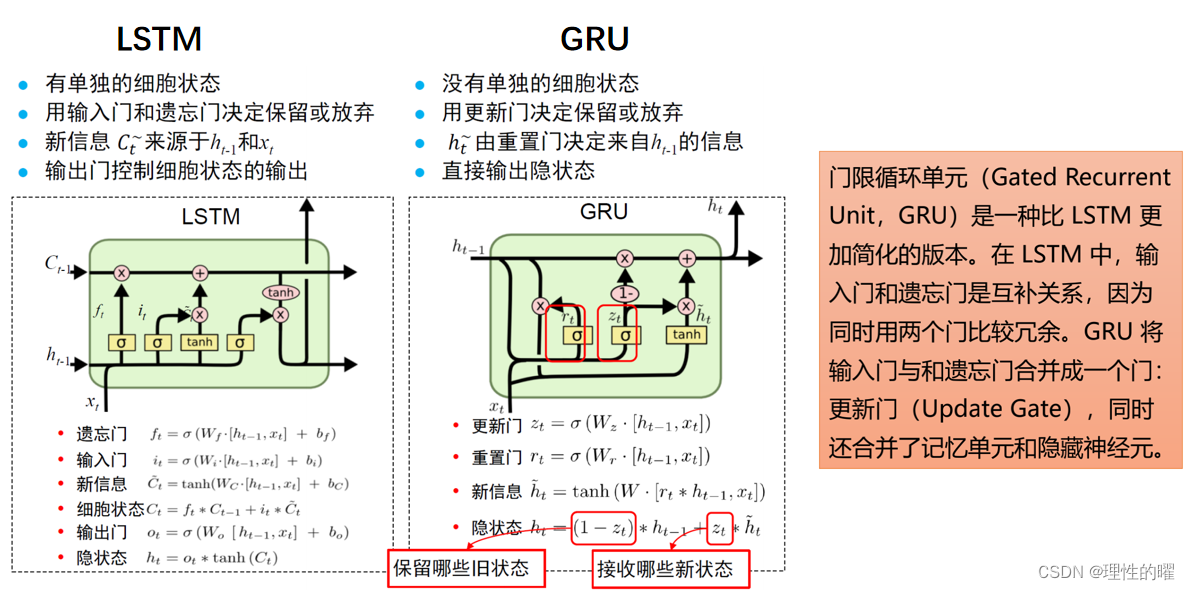
构建GRU的代码如下:
import tensorflow as tf
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.enc_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
@tf.function
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state=hidden)
return output, state
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.enc_units))接下来是注意力机制的构建:
class BahdanauAttentionMechanism(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttentionMechanism, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
@tf.function
def call(self, query, values):
query_with_time_axis = tf.expand_dims(query, 1)
score = self.V(tf.nn.tanh(
self.W1(query_with_time_axis) + self.W2(values)))
attention_weights = tf.nn.softmax(score, axis=1)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights解码器的构建:
class Decoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, dec_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
self.fc = tf.keras.layers.Dense(vocab_size)
self.attention = BahdanauAttentionMechanism(self.dec_units)
@tf.function
def call(self, x, hidden, enc_output):
context_vector, attention_weights = self.attention(hidden, enc_output)
x = self.embedding(x)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
output, state = self.gru(x)
output = tf.reshape(output, (-1, output.shape[2]))
x = self.fc(output)
return x, state, attention_weights到此模型以及构建完成。
四、模型的训练
模型训练需要损失函数,优化器,同样需要手动构建:
def loss(real,pred):
mask=tf.math.logical_not(tf.math.equal(real,0))
loss_obj=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True,reduction='none')
loss_value=loss_obj(real,pred)
mask=tf.cast(mask,dtype=loss_value.dtype)
loss_value*=mask
return tf.math.reduce_mean(loss_value)def grad_loss(q,a,q_hidden,encoder,decoder,q_index,BATCH_SIZE):
loss_value=0
with tf.GradientTape() as tape:
q_output,q_hidden=encoder(q,q_hidden)
a_hidden=q_hidden
a_input=tf.expand_dims([q_index.word_index["<strat>"]*BATCH_SIZE,1])
for vector in range(1,a.shape[1]):
predictions,a_hidden,_=decoder(a_input,a_hidden,q_output)
a_input=tf.expand_dims(a[:,vector],1)
batch_loss=(loss_value/int(a.shape[1]))
variable=encoder.trainable_variable+decoder.trainable_variable
return batch_loss,tape.gradient(loss_value,variable)def optimize_loss(q,a,q_hidden,encoder,decoder,q_index,BATCH_SIZE,optimizer):
batch_loss,grads=grad_loss(q,a,q_hidden,encoder,decoder,q_index,BATCH_SIZE)
variables=encoder.trainable_variable+decoder.trainable_variable
optimizer.apply_gradients(zip(grads,variables))
return batch_loss最后就是训练函数的编写,这部分是最重要的,写了这么多函数,我们该怎么把他们给组织起来:
import time
def train_model(q_hidden, encoder, decoder, q_index, BATCH_SIZE,dataset,steps_per_epoch,optimizer,checkpoint,checkpoint_prefix,summary_writer):
i=0
EPOCHS = 200
for epoch in range(EPOCHS):
start=time.time()
a_hidden = encoder.initalize_hidden_state()
total_loss = 0
for (batch,(q,a)) in enumerate(dataset.take(steps_per_epoch)):
batch_loss=optimize_loss(q, a, q_hidden, encoder, decoder,q_index,BATCH_SIZE,optimizer)
total_loss += batch_loss
with summary_writer.as_default():
tf.summary.scalar('batch_loss', batch_loss.numpy(), step=epoch)
if batch%100==0:
print("第{}次训练,第{}批数据损失值:{:.4f}".format(
epoch+1,
batch+1,
batch_loss.numpy()
))
with summary_writer.as_default():
tf.summary.scalar('total loss',total_loss/steps_per_epoch,step=epoch)
if (epoch+1)%100==0:
i+=1
print("=====第{}次报存训练模型=====".format(i))
checkpoint.save(file_prefix=checkpoint_prefix)
print("第{}次训练,总损失值:{:.4f}".format(epoch+1,total_loss/steps_per_epoch))
print("训练耗时:{:.1f}".format(time.time()-start))五、编写主函数以及其他函数
def max_length(vectors):
return max(len(x) for x in vectors)
def convert(index,vectors):
for vector in vectors:
if vector !=0:
print("{}-->{}".format(vector,index.index_word[vector]))
def preprocess_question(question):
question="<start> "+' '.join(question)+" <end>"
return question
def answer_vector(question,a_max_len,q_max_len,q_index,a_index,encoder,decoder):
attention_plot=np.zeros((a_max_len,q_max_len))
question=preprocess_question(question)
inputs=[q_index.word_index[i] for i in question.split(' ')]
inputs=tf.keras.preprocessing.sequence.pad_sequences([inputs],maxlen=q_max_len,padding='post')
inputs=tf.convert_to_tensor(inputs)
result=''
hidden=[tf.zeros((1,units))]
q_out,q_hidden=encoder(inputs,hidden)
a_hidden=q_hidden
a_input=tf.expand_dims([a_index.word_index["<start>"]],0)
for t in range(a_max_len):
predictions,a_hidden,attention_weights=decoder(a_input,a_hidden,q_out)
attention_weights=tf.reshape(attention_weights,(-1,))
attention_plot[t]=attention_weights.numpy()
predicted_id=tf.argmax(predictions[0]).numpy()
result+=a_index.index_word[predicted_id]
if a_index.index_word[predicted_id]=="<end>":
result+=a_index.index_word[predicted_id]
else:
return result,question,attention_plot
a_input=tf.expand_dims([predicted_id],0)
return result,question,attention_plot
#对话函数
def chat(question,a_max_len,q_max_len,q_index,a_index,encoder,decoder):
result,question,attention_plot=answer_vector(question,a_max_len,q_max_len,q_index,a_index,encoder,decoder)
print('机器人:',result)最终如何运行,需要编写下面这段代码:
import os
from datetime import datetime
if __name__ == "__main__":
stamp = datetime.now().strftime("%Y%m%d-%H:%M:%S")
# source_path = "./data/source_data.conv"
# 下载文件
path_to_zip = tf.keras.utils.get_file(
'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',
extract=True)
path_to_file = os.path.dirname(path_to_zip)+"/spa-eng/spa.txt"
# answers, questions = create_dataset(path_to_file, 24000)
# q_vec, q_index = tokenize(questions)
# a_vec, a_index = tokenize(answers)
# questions, answers = source_data(source_path)
q_vec, q_index = tokenize(questions)
a_vec, a_index = tokenize(answers)
print("voc:", q_vec)
print("tokenize:", q_index.index_word)
print("voc:", a_vec)
print("tokenize:", a_index.index_word)
q_max_len = max_length(q_vec)
a_max_len = max_length(a_vec)
convert(q_index, q_vec[0])
BUFFER_SIZE = len(q_vec)
print("buffer size:", BUFFER_SIZE)
BATCH_SIZE = 64
steps_per_epoch = len(q_vec)//BATCH_SIZE
embedding_dim = 256
units = 1024
q_vocab_size = len(q_index.word_index)+1
a_vocab_size = len(a_index.word_index)+1
dataset = tf.data.Dataset.from_tensor_slices(
(q_vec, a_vec)
).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
# 数据遍历测试
# for(batch,(q, a)) in enumerate(dataset.take(steps_per_epoch)):
# print("batch:",batch)
# print("question:",q)
# print("answer:",a)
# 正常训练
q_batch, a_batch = next(iter(dataset))
print("question batch:",q_batch.shape)
print("answer batch:", a_batch.shape)
log_path = "./logs/chat"+stamp
summary_writer = tf.summary.create_file_writer(log_path)
tf.summary.trace_on(graph=True, profiler=True)
encoder = Encoder(
q_vocab_size,
embedding_dim,
units,
BATCH_SIZE)
q_hidden = encoder.initialize_hidden_state()
q_output, q_hidden = encoder(q_batch, q_hidden)
with summary_writer.as_default():
tf.summary.trace_export(name="chat-en", step=0, profiler_outdir=log_path)
tf.summary.trace_on(graph=True, profiler=True)
attention_layer = BahdanauAttentionMechanism(10)
attention_result, attention_weights = attention_layer(
q_hidden, q_output
)
with summary_writer.as_default():
tf.summary.trace_export(name="chat-atten", step=0, profiler_outdir=log_path)
tf.summary.trace_on(graph=True, profiler=True)
decoder = Decoder(
a_vocab_size,
embedding_dim,
units,
BATCH_SIZE
)
a_output, _, _ = decoder(
tf.random.uniform((64,1)),
q_hidden,
q_output
)
with summary_writer.as_default():
tf.summary.trace_export(name="chat-dec", step=0, profiler_outdir=log_path)
optimizer = tf.keras.optimizers.Adam()
checkpoint_dir = "./models"
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(
optimizer=optimizer,
encoder=encoder,
decoder=decoder
)
# 训练模型
train_model(q_hidden, encoder, decoder, q_index, BATCH_SIZE, dataset, steps_per_epoch, optimizer, checkpoint, checkpoint_prefix,summary_writer)
# 恢复模型,进行预测
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
# 对话预测
print("====机器人1号为您服务====")
while True:
inputs = input("用户:")
if inputs == "q":
exit()
chat(inputs,a_max_len, q_max_len, q_index, a_index, encoder, decoder)
# chat_image(inputs,a_max_len, q_max_len, q_index, a_index, encoder, decoder)运行这段代码,会进行200轮的训练,最后调用对话函数,就可以和机器人对话啦。
五、总结
本文到此结束啦,作者不会提供代码,只提供数据集,因为代码全都在代码块里哈哈哈。
获取数据集的方式:
1.点赞+收藏+评论区留言邮箱
2.点赞+收藏+私信发邮箱















 1620
1620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









