






线程
几个线程方法:
~run():用以表示线程活动的方法
~start():启动线程
~join():等待至线程终止
~isAlive():返回线程是否活动的
~getName():返回线程名称
~setName() : 设置线程名称
线程池
线程池的基类是 concurrent.futures 模块中的 Executor,Executor 提供了两个子类,即 ThreadPoolExecutor 和 ProcessPoolExecutor,其中 ThreadPoolExecutor 用于创建线程池,而 ProcessPoolExecutor 用于创建进程池。
Exectuor 提供了如下常用方法:
-
submit(fn, *args, **kwargs):将 fn 函数提交给线程池。*args 代表传给 fn 函数的参数,*kwargs 代表以关键字参数的形式为 fn 函数传入参数。
-
map(func, *iterables, timeout=None, chunksize=1):该函数类似于全局函数 map(func, *iterables),只是该函数将会启动多个线程,以异步方式立即对 iterables 执行 map 处理。
-
shutdown(wait=True):关闭线程池。
程序将 task 函数提交(submit)给线程池后,submit 方法会返回一个 Future 对象,Future 类主要用于获取线程任务函数的返回值。
Future 提供了如下方法:
-
cancel():取消该 Future 代表的线程任务。如果该任务正在执行,不可取消,则该方法返回 False;否则,程序会取消该任务,并返回 True。
-
cancelled():返回 Future 代表的线程任务是否被成功取消。
-
running():如果该 Future 代表的线程任务正在执行、不可被取消,该方法返回 True。
-
done():如果该 Funture 代表的线程任务被成功取消或执行完成,则该方法返回 True。
-
result(timeout=None):获取该 Future 代表的线程任务最后返回的结果。如果 Future 代表的线程任务还未完成,该方法将会阻塞当前线程,其中 timeout 参数指定最多阻塞多少秒。
-
exception(timeout=None):获取该 Future 代表的线程任务所引发的异常。如果该任务成功完成,没有异常,则该方法返回 None。
-
add_done_callback(fn):为该 Future 代表的线程任务注册一个“回调函数”,当该任务成功完成时,程序会自动触发该 fn 函数
-
使用线程池来执行线程任务的步骤如下:
-
调用 ThreadPoolExecutor 类的构造器创建一个线程池。
-
定义一个普通函数作为线程任务。
-
调用 ThreadPoolExecutor 对象的 submit() 方法来提交线程任务。
-
当不想提交任何任务时,调用 ThreadPoolExecutor 对象的 shutdown() 方法来关闭线程池。
注意:
程序调用了 Future 的 result() 方法来获取线程任务的运回值,但该方法会阻塞当前主线程,只有等到钱程任务完成后,result() 方法的阻塞才会被解除。
如果程序不希望直接调用 result() 方法阻塞线程,则可通过 Future 的 add_done_callback() 方法来添加回调函数,该回调函数形如 fn(future)。当线程任务完成后,程序会自动触发该回调函数,并将对应的 Future 对象作为参数传给该回调函数。
实例:
from concurrent.futures import ThreadPoolExecutor
import threading
import time
# 定义一个准备作为线程任务的函数
def action(max):
my_sum = 0
for i in range(max):
print(threading.current_thread().name + ' ' + str(i))
my_sum += i
return my_sum
# 创建一个包含2条线程的线程池
with ThreadPoolExecutor(max_workers=2) as pool:
# 向线程池提交一个task, 50会作为action()函数的参数
future1 = pool.submit(action, 50)
# 向线程池再提交一个task, 100会作为action()函数的参数
future2 = pool.submit(action, 100)
def get_result(future):
print(future.result())
# 为future1添加线程完成的回调函数
future1.add_done_callback(get_result)
# 为future2添加线程完成的回调函数
future2.add_done_callback(get_result)
print('--------------')主程序的最后一行代码打印了一条横线。由于程序并未直接调用 future1、future2 的 result() 方法,因此主线程不会被阻塞,可以立即看到输出主线程打印出的横线。接下来将会看到两个新线程并发执行,当线程任务执行完成后,get_result() 函数被触发,输出线程任务的返回值。
由于线程池实现了上下文管理协议(Context Manage Protocol),因此,程序可以使用 with 语句来管理线程池,这样即可避免手动关闭线程池。
线程的通信
场景:
1、一个线程生成数据,另一个线程处理数据。
2、多个线程并发地读取和写入共享的数据结构。
3、一个线程通知另一个线程某个事件的发生。
通信实现:
1.共享变量
互斥访问共享变量
import threading
# 创建互斥锁
lock = threading.Lock()
def producer():
global data
with lock:
data = 123
def consumer():
with lock:
print(data)
# 创建两个线程
t1 = threading.Thread(target=producer)
t2 = threading.Thread(target=consumer)
# 启动线程
t1.start()
t2.start()
# 等待线程结束
t1.join()
t2.join()在上面的代码中,with lock语句用于获取互斥锁。当一个线程获取到锁时,其他线程必须等待,直到该线程释放锁。通过使用互斥锁,我们可以确保在一个线程修改共享变量时其他线程不能同时访问。(操作系统中讲的临界资源)
2.队列
实例:
from queue import Queue
from threading import Thread
import random
import time
_sentinel = object()
def producer(out_q):
n = 10
while n:
time.sleep(1)
data = random.randint(0, 10)
out_q.put(data)
print("生产者生产了数据{0}".format(data))
n -= 1
out_q.put(_sentinel)
def consumer(in_q):
while True:
data = in_q.get()
print("消费者消费了{0}".format(data))
if data is _sentinel:
in_q.put(_sentinel)
break
q = Queue()
t1 = Thread(target=consumer, args=(q,))
t2 = Thread(target=producer, args=(q,))
t1.start()
t2.start()Queue的部分方法介绍:
get(): 获取Queue中的一条数据,该方法是会阻塞的,如果Queue中没有数据那么会一直停在这里
put(): 往Queue中存入一条数据,如果Queue已满,那么会阻塞
qsize(): 获取Queue的长度
empty(): 判断Queue是否为空
full(): 判断Queue是否已满
put_nowait(): 与put方法相同,只是不阻塞,会立刻返回结果.可以设置put方法的block参数实现
get_nowait(): 与get方法相同,只是不阻塞,会立刻返回结果.可以设置get方法的block参数实现
join和task_done方法: join方法可以从Queue的角度阻塞整个程序的运行,直到Queue收到一个task_done方法的信号才会退出程序. task_done放法要写在join方法之前.
Event事件:
3个函数
event = threading.Event()
# 重置event,使得所有该event事件都处于待命状态
event.clear()
# 等待接收event的指令,决定是否阻塞程序执行
event.wait()
# 发送event指令,使所有设置该event事件的线程执行
event.set()
实例:
#这段代码的作用是创建了一个事件对象,使用该事件对象进行线程间的同步。多个线程被阻塞在event.wait()方法处等待事件的触发,当调用event.set()方法后,所有等待中的线程会被激活并开始执行任务。
import threading
event = threading.Event()
def worker():
print('Waiting for event to trigger...')
event.wait()
print('Starting...')
threads= []#使用for循环创建了4个线程,并将它们添加到threads列表中,每个线程的目标函数都是worker。
for i in range(4):
threads.append(threading.Thread(target=worker))
for t in threads:
t.start()
event.set()#通过调用event.set()方法,设置事件为已触发,即通知所有等待中的线程可以开始执行任务。
for t in threads:
t.join()线程锁:
线程锁实例方法:
acquire([timeout]): 使线程进入同步阻塞状态,尝试获得锁定。
release(): 释放锁。使用前线程必须已获得锁定,否则将抛出异常。
实例:
import threading
import time
#创建了一个名为rlock的可重入锁对象
rlock = threading.RLock()
#定义了一个名为func的函数,表示线程的执行任务。在函数中,首先打印"acquire lock…“,表示当前线程正#在请求获得锁。然后通过调用rlock.acquire()方法来请求获得锁。如果获得锁成功,打印"get the #lock.”,表示当前线程成功获得了锁。接下来通过调用time.sleep(2)方法暂停2秒钟,模拟线程的执行过程。
def func():
# 第一次请求锁定
print('%s acquire lock...' % threading.currentThread().getName())
if rlock.acquire():
print('%s get the lock.' % threading.currentThread().getName())
time.sleep(2)
# 第二次请求锁定
print('%s acquire lock again...' % threading.currentThread().getName())
if rlock.acquire():
print('%s get the lock.' % threading.currentThread().getName())
time.sleep(2)
# 第一次释放锁
print('%s release lock...' % threading.currentThread().getName())
rlock.release()
time.sleep(2)
# 第二次释放锁
print('%s release lock...' % threading.currentThread().getName())
rlock.release()
t1 = threading.Thread(target=func)
t2 = threading.Thread(target=func)
t3 = threading.Thread(target=func)
t1.start()
t2.start()
t3.start()信号量
构造方法:
Semaphore(value=1): value是计数器的初始值。
实例方法:
acquire([timeout]): 请求Semaphore。如果计数器为0,将阻塞线程至同步阻塞状态;否则将计数器-1并立即返回。
release(): 释放Semaphore,将计数器+1,如果使用BoundedSemaphore,还将进行释放次数检查。release()方法不检查线程是否已获得 Semaphore。
from multiprocessing import Process
from multiprocessing import Semaphore
from multiprocessing import current_process
import time
import random
#该函数表示每个进程的执行任务
def get_connections(s):
#调用acquire方法来请求获得信号量。如果当前信号量的计数器大于零,则线程可以继续执行
s.acquire()
try:
print(current_process().name+' acqiure a connection')
time.sleep(random.randint(1,2))
print(current_process().name+' finishes its job and return the connection')
except:
raise
#调用release方法来释放信号量,即将信号量的计数器加1。
finally:
s.release()
if __name__=='__main__':
#创建了一个名为connections的信号量,初始值为5。
connections=Semaphore(5)
workers=[]
#创建了一个空的进程列表workers。通过一个循环,创建了20个进程,每个进程的目标函数为get_connections,传入参数为connections信号量,并为每个进程指定一个名称
for i in range(20):
p=Process(target=get_connections,args=(connections,),name='worker:'+str(i+1))
workers.append(p)
for p in workers:
p.start()
#通过循环遍历workers列表,使用join方法等待所有进程执行完毕。
for p in workers:
p.join()
print("all workers exit")问题:
缓冲区满就False,并没有等待缓冲区有空位呀?
我们使用queue.Queue类来创建一个线程安全的队列。在add_item方法中,我们使用queue.put方法将物品添加到队列中。如果队列已满,queue.put方法将阻塞线程,直到队列中有空位或超时。在这个例子中,我们设置了一个1秒的超时时间。
在remove_item方法中,我们使用queue.get方法从队列中删除物品。如果队列为空,queue.get方法将阻塞线程,直到队列中有物品可用或超时。
使用queue模块可以避免我们手动实现线程安全的队列,并且可以更容易地实现生产者-消费者问题。在这个实现中,生产者线程将在队列已满时阻塞,直到队列中有空位。这样可以避免生产者线程无限循环地添加物品,从而导致缓冲区溢出。
问题2
在当前代码中,当缓冲区已满时,add_item 方法会在队列的 put 操作中使用了一个超时参数 timeout,但它并没有做任何处理,只是返回了 False。而在消费者线程中,当队列为空时,remove_item 方法会在队列的 get 操作中使用了一个超时参数 timeout,同样也没有做任何处理,只是返回了 None
解决:提供一种机制让生产者线程在缓冲区满时等待,并在消费者线程消费产品后进行通知。类似地,让消费者线程在缓冲区空时等待,并在生产者线程生产产品后进行通知。
实战!!!!
知识:
类
1. 调用类
类的名称空间在定义阶段就产生了
对象名=类名 () //并不会调用类的子代码运行,因为在定义阶段就执行过了。
//只会建好对象与类的关联
__init__
在调用类的时候被自动执行
在调用类创建类对象的时候,Python会自动调用类下的__init__
2.类的属性访问
对象可以使用类,类也可以使用类
类名.__dict__
返回一个字典(里面就有类名称空间里面的名字)
类名.__dict__['属性名']
返回属性值
类名.__dict__['函数']
调用函数
3.类里面存放的是对象固有的数据和功能
对象
1.访问属性
对象名.__dict__
-----在对象里访问类
在建立了对象与类的关联之后,调用“对象名.__dict__”之后返回的是空字典,因为一开始就没往里头放数据,但可以通过“对象名.类属性”访问到类容器
when对象在访问属性时,先在对象自己的名称空间里面找(包括__init__中的,但是__init__中没有的,自己可以加属性(不管是不是类里的共有的属性)),再去所属类的名称空间里面去找
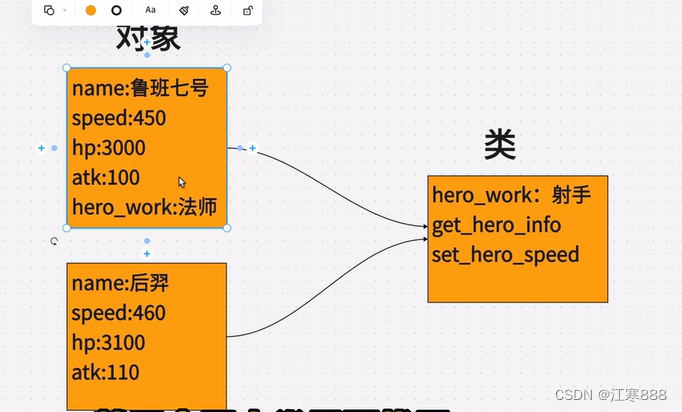
2添加属性(对象自己独有的数据)
方式一:对象名.__dict__['key']=value
方式二:对象名.key=value
3.当遇到各个对象有相同的key,却有不同的value时
用类里的__init__
















 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









