






论文地址:https://arxiv.org/abs/1911.05722
项目地址:GitHub - facebookresearch/moco: PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722
自监督self-supervised learning
自监督,是指从输入数据中构建出标签或者监督信号;
它利用数据本身的固有结构或信息来创建训练的标签。自我监督学习不是依靠人类标记的数据,而是从输入数据中创建人工标签或监督信号。这些人工标签是使用特定的先验任务生成的,旨在捕捉数据中的有用信息或关系。
自监督学习是无监督学习中的一个特定方法,从数据本身产生人工标签或监督信号。自监督学习由于能够在不需要大量标签数据的情况下学习有意义的表征而得到了普及
自监督学习是从数据本身找标签来进行有监督学习。
对比学习
对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征。
就比如在没有标签的情况下,做出如下判断:

对比学习的目标是在特征空间中,相似的特征尽量靠近,不相似的特征尽量远离。
对比学习如何工作?
以MoCo v1的工作为例,从损失函数的角度介绍模型的训练方式。
损失函数:
info NCE loss:
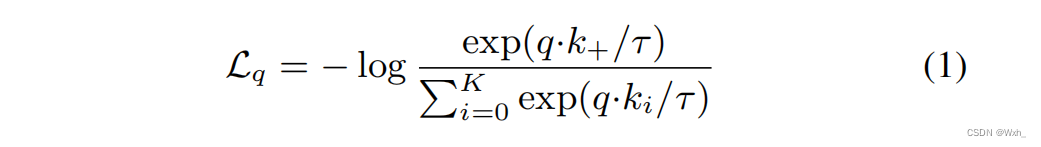
假设不考虑,并且将q*k当作一般分类模型最后的输出,也就是logits,那么上述损失函数就是一个Cross Entropy Loss,即交叉熵损失,但这是一个已知标签位置的交叉熵损失。
交叉熵损失函数
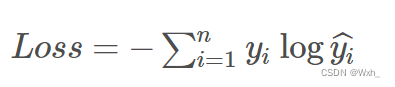
用一个例子来说明,在手写数字识别任务中,如果样本是数字“5”,那么真实分布应该为:[ 0, 0, 0, 0, 0, 1, 0, 0, 0, 0 ],
如果网络输出的分布为:[ 0.1, 0.1, 0, 0, 0, 0.7, 0, 0.1, 0, 0 ],那么计算损失函数得:
Loss=−0×log0.1−0×log0.1−0×log0−0×log0−0×log0−1×log0.7−0×log0−0×log0.1−0×log0−0×log0≈0.356
如果网络输出的分布为:[ 0.2, 0.3, 0.1, 0, 0, 0.3, 0.1, 0, 0, 0 ],那么计算损失函数得:
Loss=−0×log0.2−0×log0.3−0×log0.1−0×log0−0×log0−1×log0.3−0×log0.1−0×log0−0×log0−0×log0≈1.2040
上述两种情况对比,第一个分布的损失明显低于第二个分布的损失,说明第一个分布更接近于真实分布,事实也确实是这样。
对比学习所用的损失函数就是已知标签位置的交叉熵损失函数。
那么就会有两个问题:
第一,对比学习没有标签,如何判定每个样本应该被分到哪一个类别?
第二,就算知道它应该被分到哪个类别,又如何得到label?
代理任务:instance discrimination
在对比学习中,代理任务的作用就是生成一种自监督信号,也就是设定一种规则,以区分正负样本,从而解决上述的第一个问题。在MoCo v1中,采用了最常见的个体判别(instance discrimination)作为代理任务。


个体判别任务将每个样本视作一个单独的类,任务目标是进行一个 K+1类的分类任务,K为负样本个数。对于imagenet数据集来说,它就不在是1k类,而是1M类。
对比学习中的代理任务设定是非常灵活的,比如图片的不同角度,不同裁剪,视频的任意连续两帧,nlp中文本的两次随机dropout后forward结果等等,在moco v1中,使用了上述方法判定正负样本。
但是又有一个问题,假设使用imagenet数据集训练,那么每次都要计算一个百万类分类任务的损失,这是没法儿计算的,因此使用一种近似的分布来模拟整个数据集,也就是随机抽样。
NCE loss
NCE loss : Noise Contrastive Estimation(噪声对比估计)
他的直观想法:把多分类问题转化成二分类。
之前计算softmax的时候class数量太大,NCE索性就把分类缩减为二分类问题。
之前的问题是计算某个类的归一化概率是多少,二分类的问题是input和label正确匹配的概率是多少,也就是不用计算负样本的得分,只计算正样本的得分

Info NCE Loss
温度超参数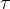
其实就是在NCE的基础上加了这个超参数,用于模型对负样本分布的控制。

动态字典
在moco v1中,作者将看作query,将
和
看作key,那么问题就转换为q在K+1个key中如何查询到唯一那个正样本的问题,也就是将对比学习看作是构建一个动态字典的问题。
这个字典首先要足够大,足够多的负样本才能拟合数据的分布。
字典中key的个数也就是负样本的个数,如果选取所有负样本,比如1M,这样无法计算,NCE loss也并没有降低计算复杂度,因此moco v1在所有负样本中随机抽样65536个负样本,当作字典的大小。
但如果每次都在65536+1=65537上进行计算,也就是batch_size选65537,硬件达不到要求。
所以作者提出以队列的形式储存key。
队列 :fifo,即 first in first out
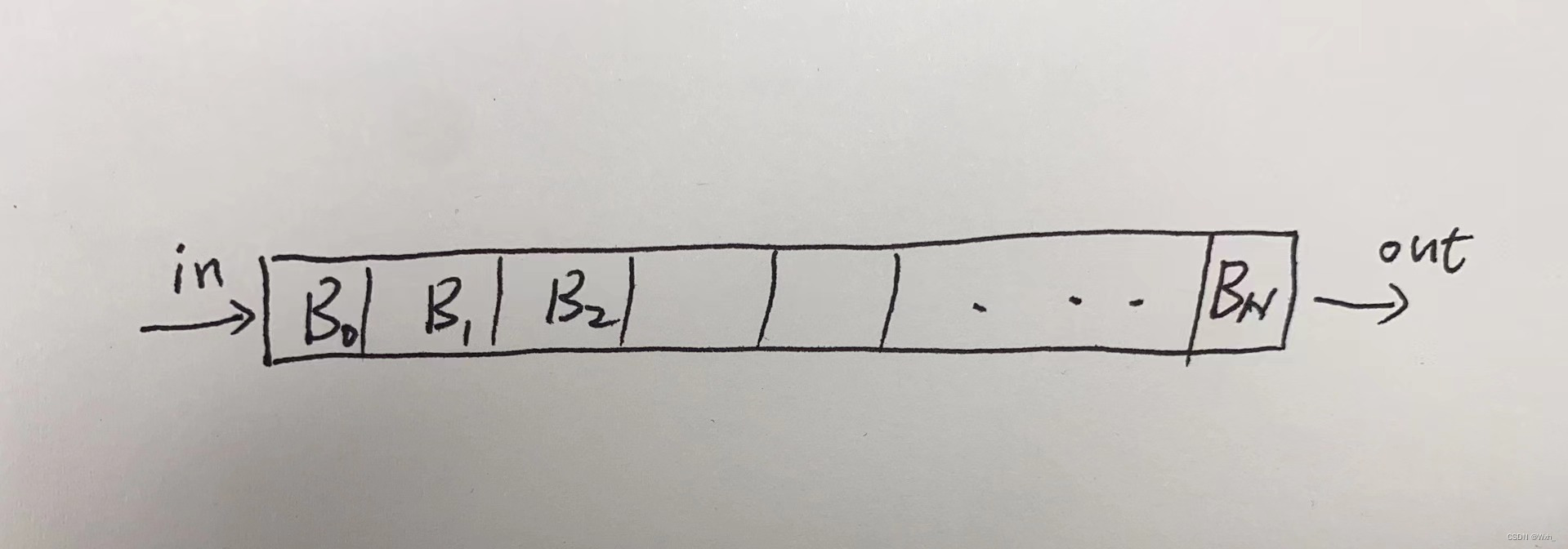
B为mini_batch,这样就可以将batch的大小和字典的大小剥离,这是moco v1的第一点贡献。
补充:为方便理解,图中每个格子中写的是B,其实应该是Key,也就是负样本的特征,一个128维的向量。
负样本的一致性
但是这样的话,就没办法用每个batch得到的损失梯度回传去更新模型。
因为当前负样本的特征是是用当前编码器得到的,一旦模型更新,队列中移出一个batch的负样本,移进一个batch的负样本,这个负样本的特征是用新的编码器得到的,不仅与其他负样本不一致,而且与当前正样本的编码器一致,这会破坏负样本对于原数据的拟合,也有可能使模型认为同一个编码器得到的特征是近似的,学了一条捷径。
举例:

因此 ,为了保证队列中负样本的一致性,moco v1提出了第二点贡献,也就是动量编码器。
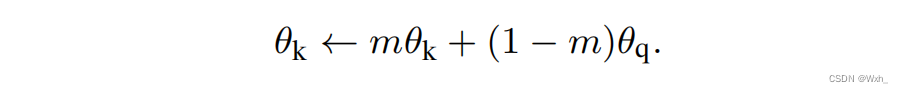
文中分别做了m=0.999和m=0.9的实验,发现m越趋近于1,效果越好。这样既更新了k的编码器,也保证了负样本特征一致性。
伪代码

实验结果
pass...
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









