






训练数据:
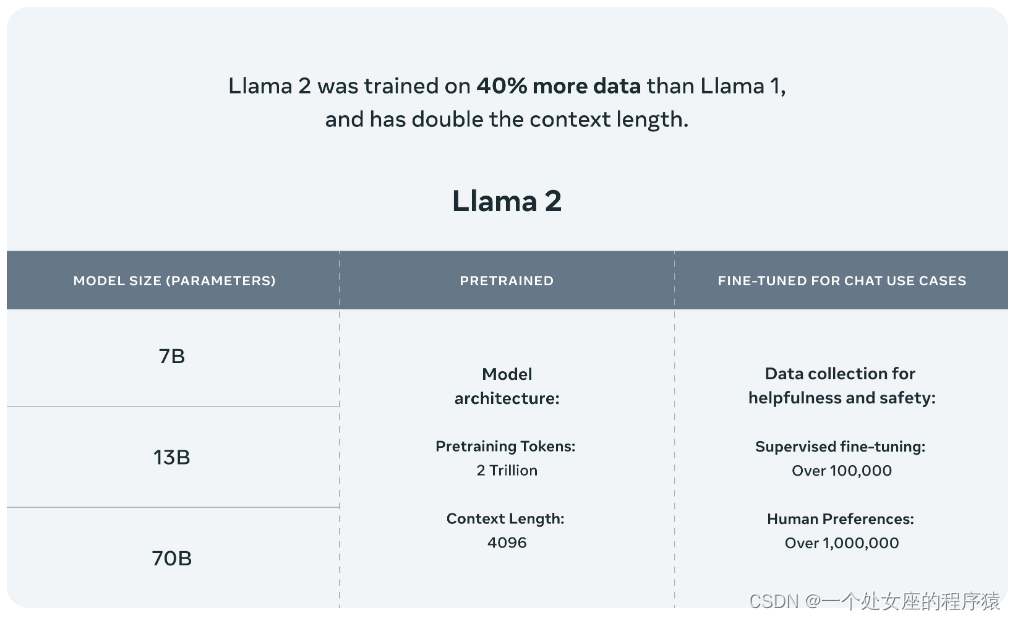
Llama 2是在公开可用的在线数据源上进行预训练的。经过微调的模型Llama-2-chat利用了公开可用的指令数据集和超过100万个人类注释。在模型内部,Llama 2模型是在2万亿个标记上进行训练的,具有Llama 1的2倍的上下文长度。Llama-2-chat模型还额外训练了超过100万个新的人类注释。Llama 2的数据比Llama 1多了40%,上下文长度增加了一倍。
更长的上下文窗口使模型能够处理更多信息,这对于支持聊天应用程序中的更长的历史记录、各种摘要任务和理解更长的文档特别有用。
个人理解:在预训练阶段,transformer让模型拥有了语言生成的功能。通过输入一个句子的一部分或一个完整的句子,模型可以生成下一个可能的单词、短语,甚至是完整的段落。这种生成在文本自动生成、机器翻译、摘要生成等任务中非常有用。这时候的预训练模型,相当于一本没有感情的字典,里面有各种文字、语法规则、例句,并且能够根据提示自动查找,但是没有评判标准,对语义信息理解能力不够,想要完成对话任务,必须经过微调。
模型结构:
Llama 2采用了 Llama 1 的大部分预训练设置和模型架构,使用标准Transformer 架构,使用 RMSNorm 应用预归一化、使用 SwiGLU 激活函数和旋转位置嵌入RoPE。
SFT 监督微调
具体来说,监督式微调包括以下几个步骤:
预训练 首先在一个大规模的数据集上训练一个深度学习模型,例如使用自监督学习或者无监督学习算法进行预训练;
微调 使用目标任务的训练集对预训练模型进行微调。通常,只有预训练模型中的一部分层被微调,例如只微调模型的最后几层或者某些中间层。在微调过程中,通过反向传播算法对模型进行优化,使得模型在目标任务上表现更好;
评估 使用目标任务的测试集对微调后的模型进行评估,得到模型在目标任务上的性能指标。
llama2中的SFT

微调指令如上,作者共使用了大约27000条指令,论文中说Quality Is All You Need,也就是说质量是数据的关键。微调时只对模型的回答做反向传播。
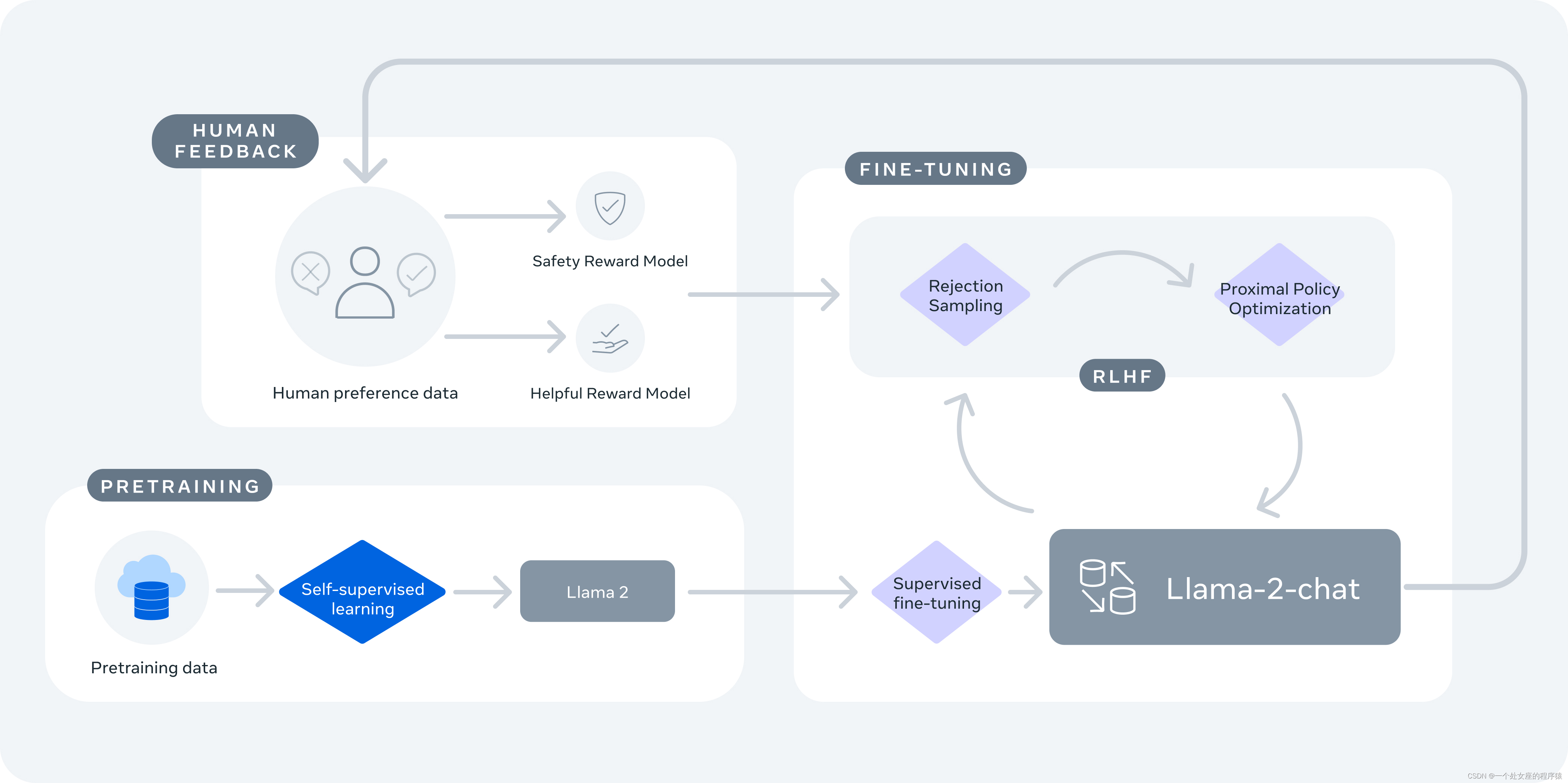
什么是RLHF?
RLHF (Reinforcement Learning from Human Feedback) ,即带有人类反馈的强化学习。
RLHF的过程可以分为几个步骤:
1.初始模型训练:一开始,AI模型使用监督学习进行训练,人类训练者提供正确行为的标记示例。模型学习根据给定的输入预测正确的动作或输出。
2.收集人类反馈:在初始模型被训练之后,人类训练者提供对模型表现的反馈。他们根据质量或正确性排名不同的模型生成的输出或行为。这些反馈被用来创建强化学习的奖励信号。
人类反馈可以以多种形式提供:
-
直接指导: 人类可以直接告诉代理哪些行为是好的或不好的,代理根据这些反馈来更新策略。
-
比较反馈: 人类可以提供不同行为之间的比较,告诉代理哪个行为更好。
-
奖励模型: 人类可以设计一个奖励函数,根据代理的行为给予奖励或惩罚,代理根据奖励信号来学习。
-
演示: 人类可以提供一些示例,展示应该如何执行任务,代理可以通过模仿这些示例来学习。
在llama2中,在收集反馈时选用了比较反馈的形式,即binary comparison protocol,二进制比较协议,基本思想是将两个不同的行为(策略)呈现给人类,然后要求人类选择其中哪个行为更好或更合适。通过收集多次这样的比较反馈,代理可以逐渐学习哪种行为在人类眼中更优越,从而调整策略以提高性能。作者在llama2中关注的主要是有用性和安全性。
3.强化学习:然后使用Proximal Policy Optimization (PPO)或类似的算法对模型进行微调,这些算法将人类生成的奖励信号纳入其中。模型通过从人类训练者提供的反馈学习,不断提高其性能。
4.迭代过程:收集人类反馈并通过强化学习改进模型的过程是重复进行的,这导致模型的性能不断提高。

注:上图来自于gpt训练过程,只可作为参考。
奖励模型(Reward Model)
奖励模型将模型响应及其相应的提示(包括来自前一个回合的上下文)作为输入,并输出一个标量分数来指示模型生成的质量(例如,有用性和安全性)。利用这样的反应分数作为奖励,我们可以在RLHF期间优化Llama 2-Chat,以更好地调整人类的偏好,提高帮助和安全性。
帮助性和安全性有时会相互权衡,这使得单一奖励模型在两者上都表现良好具有挑战性。为了解决这个问题,我们训练了两个独立的奖励模型,一个针对帮助性(称为helpfulness RM)进行了优化,另一个针对安全性(safety RM)进行了优化。

上图是奖励模型与其他模型在不同测试集上的表现,这些测试集都是符合人类偏好的。
拒绝近抽样和近端策略优化(PPO):
近端策略优化(PPO):
关于强化学习(RLHF)中PPO算法的理论,全部学习于这篇博客:强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO_mdp和dp_v_JULY_v的博客-CSDN博客
现做一些自己的总结。
给定策略参数(一个网络结构),计算某条轨迹
发生的概率:

策略价值函数:

个人理解:该策略下轨迹的期望奖励。

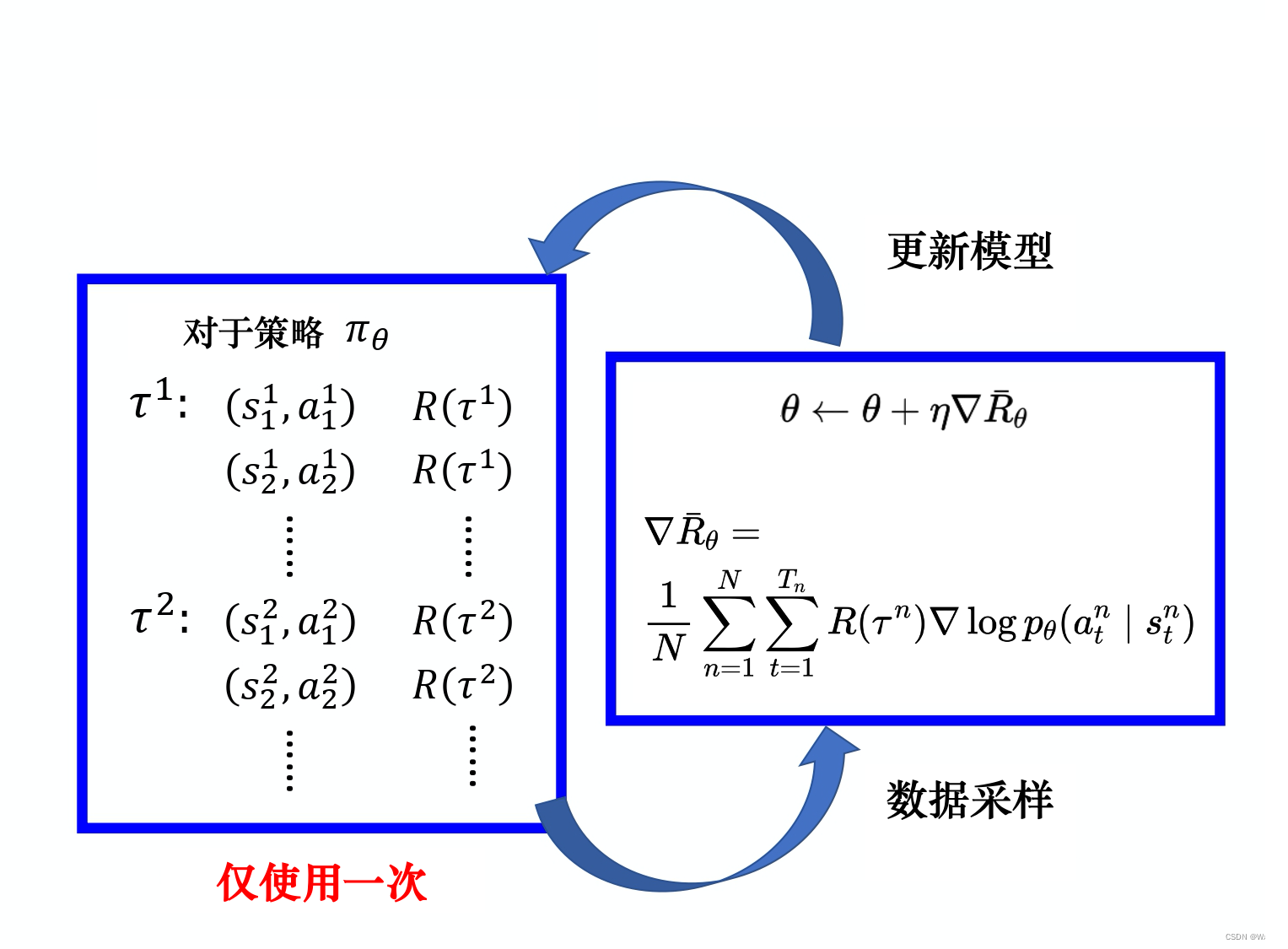
那么想让奖励越大越好,可以使用梯度上升来最大化期望奖励。而要进行梯度上升,先要计算期望奖励的梯度:

因此,期望奖励梯度如下:

按照蒙特卡洛方法近似求期望原则,采样N条轨迹,再求平均:

其中n代表第n条轨迹的采样,公式中末尾梯度的变化很简单,将轨迹概率先取对数再求梯度展开合并即可。
如此可得策略梯度定理:

计算出梯度后,就可以根据![]() 来更新
来更新,即(神经网络)。
避免采样的数据仅能用一次:重要性采样
策略函数为:
关于策略梯度,由于策略只与有关,当
更新后,在对应s状态下对应的概率p(
)会发生变化,之前采样的(s,a)也都不能用了。如下图所示:
解决方法:引入重要性权重,公式如下:

1.可以用另外一个策略πθ′与环境交互,用θ′采样到的数据去训练。
2.假设我们可以用 θ′采样到的数据去训练,我们可以多次使用θ′采样到的数据,可以多次执行梯度上升,可以多次更新参数, 都只需要用θ′采样到的同一批数据。
引入优势演员-评论家算法(Advantage Actor-Criti):为避免奖励总为正增加基线
实际在做策略梯度的时候,并不是给整个轨迹都一样的分数,而是每一个状态-动作的对会分开来计算,但通过蒙特卡洛方法进行随机抽样的时候,可能会出问题,比如在采样一条轨迹时可能会出现
- 问题1:所有动作均为正奖励
- 问题2:出现比较大的方差
为了解决奖励总是正的的问题,也为避免方差过大,需要在之前梯度计算的公式基础上加一个基准线bb『此bb指的baseline,非上面例子中的b,这个所谓的基准线bb可以是任意函数,只要不依赖于动作即可』


此外,b还有别的选择,留待用到时再详细理解。
一般的,被定义为优势函数
,是对一个动作在平均意义上比其他动作好多少的度量。

再引入重要性采样可得:

个人理解:最后一项梯度消失是因为目标函数是对采样,而不是
,因此对目标函数影响不大。
信任区域策略优化——TRPO(Trust Region Policy Opimization)
由于重要性采样引入了参数,这会导致采样数目不够多时变量(s,t)分布方差与引入重要性权重前的分布方差差异较大,公式如下:

为了使不太大,需要让这两个分布尽量接近,因此加入KL散度约束,用来限制两个分布的相似性。

近端策略优化PPO:解决TRPO的计算量大的问题

其实就是将KL散度约束放在了目标函数中,其中是可以调整的。
通过设置KL散度的最大最小值,如果策略优化后超出这个范围,自适应的调整大小,以调整惩罚力度。(有点类似于正则项)
总结:

在llama2强化学习过程中,将奖励模型作为奖励函数的估计,将预训练模型当作被优化的策略,在此基础上,目标函数如下:















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









