






目录
为什么索引的默认结构使用B+树,而不是B-树,Hash表,二叉树,红黑树?
B树的出现:1970年,R.Bayer和E.mccreight提出了一种适用于外查找的树,它是一种平衡的多叉树(N叉搜索树),称为B树(或B-树、B_树)。
B-树
性质:1.每个树节点上都包含多个值
2.每个节点上的子树个数,就是当前节点值范围的个数+1
3.保证字数中的节点值一定要处于父节点的范围之内
4.所有的叶子结点都位于同一层。
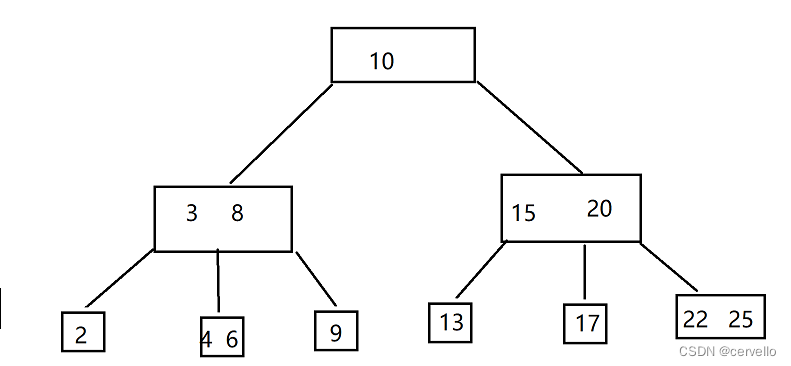
B树中的每一个节点的值为复合值,相较于BST来说,N叉搜索树可以大大降低树的高度
B-树上的每一个节点都储存当前数据表中该索引的数据
B+树
性质:1.B+树中,子节点中存在的最大值(最小值)是父节点中出现过的值
2.B+树中,最底层的叶子节点使用链表连接 (更高效的区间查找)
3.B+树中所有的数据都储存在叶子节点,非叶子节点只储存索引的辅助信息
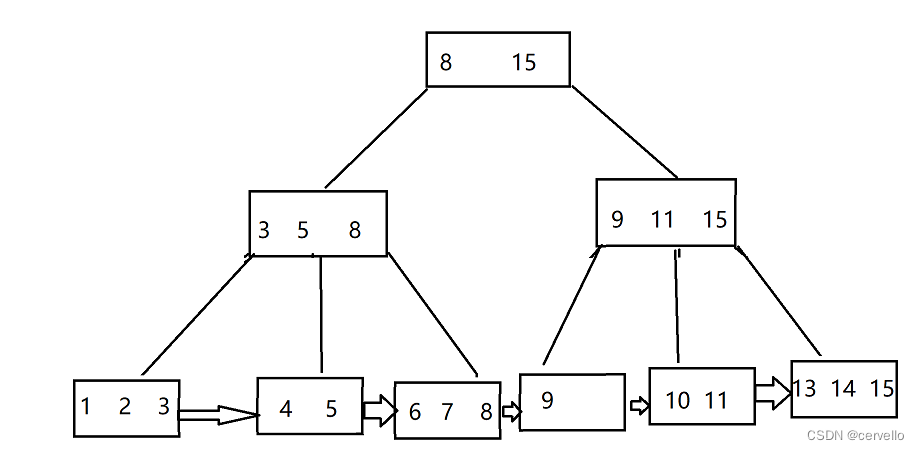
B-树与B+树的区别?
1.B-内部非叶子节点时存储数据的;而B+树非叶子节点不保存数据,只做索引作用,他的叶子节点保存数据;
2.B+树的相邻叶子节点之间是通过链表连接起来的
3.查找过程中,B-树再找到具体的数值以后就结束,而B+树则需要通过索引找到叶子节点中的数据才结束
4.b-树中任何一个关键词出现且只出现在一个节点,而B+树中可以出现多次
为什么索引的默认结构使用B+树,而不是B-树,Hash表,二叉树,红黑树?
1.Hash表只适合单个数据查询,不适合范围查询
2.一般二叉树,树的结构不确定导致查询的速度也不确定,如果二叉树出现了退化为链表的情况,就相当于全表扫描
3.红黑树:当MySQL数据量很大时,索引的体积也会很大,内存中如果放不下的需要从磁盘中读取,树的层次太高的话,读取磁盘的次数就多了,而磁盘的读取速度远远大于从内存中读取
4.B-树:叶子节点和非叶子节点都存储数据,相同的数据量,B+树数据结构,查询磁盘的次数会更少
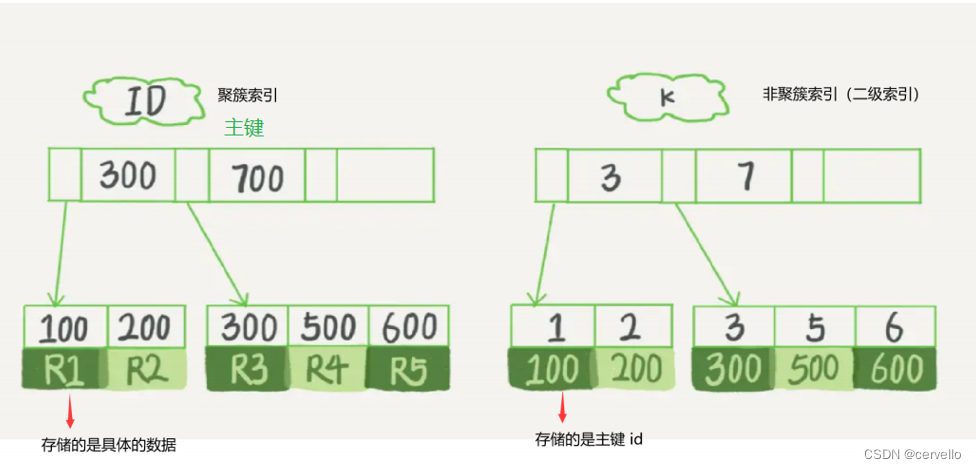
聚簇索引
主键索引,一个表中只有一个聚簇索引,索引树上的每一个节点,除了保存索引列的信息,还需要保存这条记录的完整内容
特点:查询速度快,保存信息多,占用空间大
非聚簇索引
普通索引,一张表上可以由多个非聚簇索引,索引树上的每一个节点,除了保存索引列的信息,还需要该记录的行号
特点:查询速度慢(找到主键信息后,还需要回表查询),保存信息少,占用空间小















 1035
1035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









