







前言
参考文章:https://zhuanlan.zhihu.com/p/113917726
磁盘与IO

通常所说的机械硬盘就是上述结构,持久化的数据会存储其中,从磁盘读数据到内存中实际上就是磁头找到数据并拷贝到内存中的过程,具体分为三步:
- 寻道:磁头移动到磁道的过程,大约耗时5ms以下
- 寻点:磁头在磁道上找数据的过程,平均时间是磁头转半圈的时间,如果是一个7200转/min的磁盘,寻点时间平均是600000/7200/2=4.17ms
- 拷贝到内存:很快,可以忽略不计
所以每次IO的耗时大约是9ms,如果是百万级数据库,那么每次IO就要9000s。
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了预读的优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。
每一次IO读取的数据我们称之为一页(page),具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO。
哈希表(HASH)
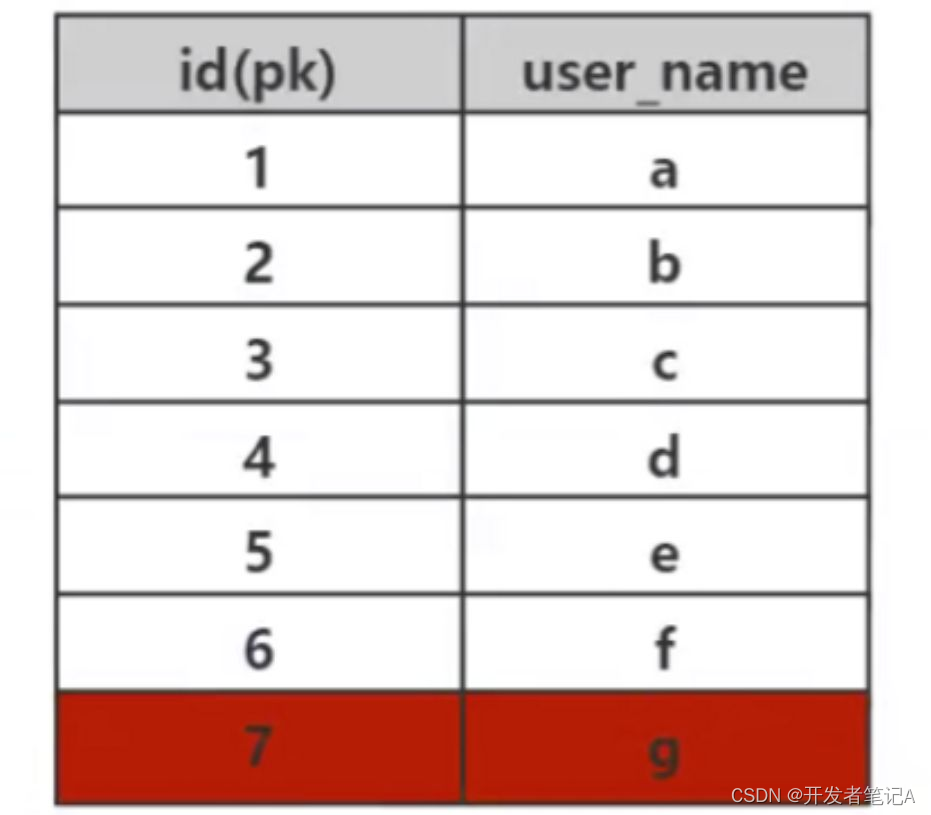
假设有如上结构的表,如果没有索引,那么如果要找id = 7的数据,那么采取最简单的顺序遍历,要比较7次,时间复杂度是O(n),如果数据量级是1000w,那么查找会非常耗时
哈希算法:也叫散列算法,就是把任意值(key)通过哈希函数变换为固定长度的 key 地址
考虑这个数据库表 user,表中一共有 7 个数据,我们需要检索 id=7 的数据,SQL 语法是:
select * from user where id=7;
哈希算法首先计算存储 id=7 的数据的物理地址 addr=hash(7)=4231,而 4231 映射的物理地址是 0x77,0x77 就是 id=7 存储的额数据的物理地址,理想情况时间复杂度只需要O(1)
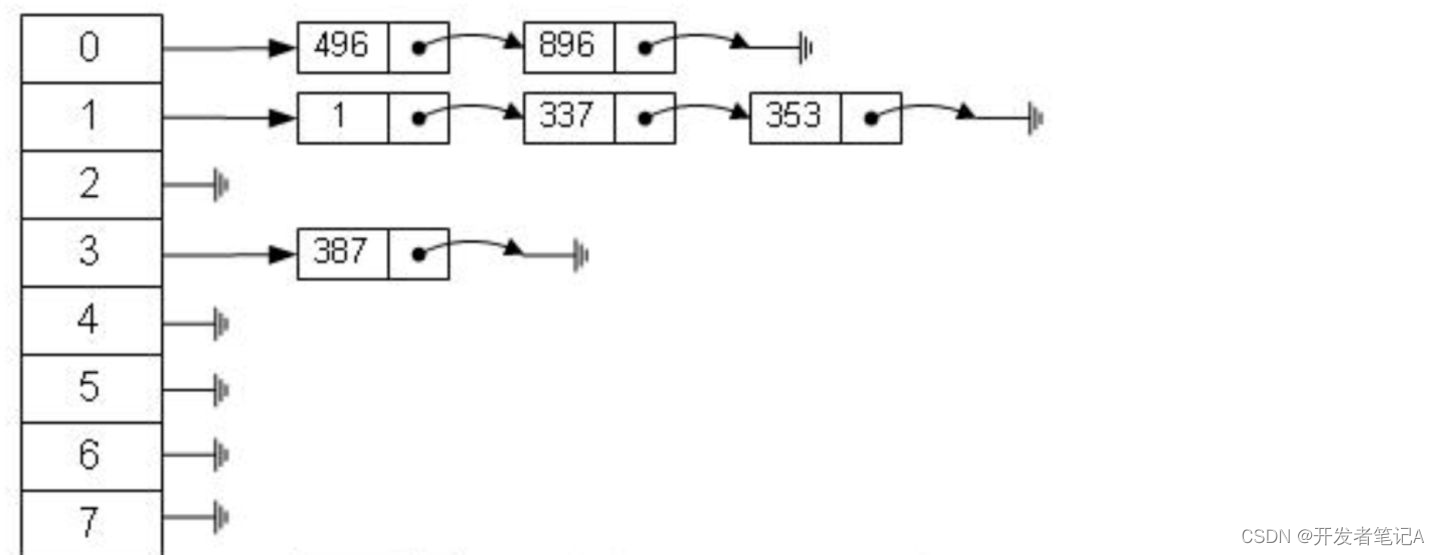
但实际上哈希函数可能对不同的 key 会计算出同一个结果,这就是碰撞问题。解决碰撞问题的一个常见处理方式就是链地址法,即用链表把碰撞的数据接连起来。计算哈希值之后,还需要检查该哈希值是否存在碰撞数据链表,有则一直遍历到链表尾,直达找到真正的 key 对应的数据为止。
但MySql并没有将哈希作为底层算法是因为sql语句的范围查找问题,比如以下这个 SQL 语句:
select * from user where id >3;
哈希就哑火了
下面用java写一个简单的HASH表(拉链式)
public class Hello {
public static void main(String [] args) {
// Hash表插入数据
HashTable table = new HashTable(10);
table.insert(new Item(29,"a"));
table.insert(new Item(52,"b"));
table.insert(new Item(71,"c"));
table.insert(new Item(98,"d"));
table.insert(new Item(91,"e"));
// 便利Hash表数据
for(Item item : table.hashArr) {
if (item != null ) {
System.out.println(item.info);
} else {
System.out.println("null");
}
}
// 测试Hash表的查询
System.out.println("find 98:" + table.find(98).info);
}
}
// 拉链式哈希表
class HashTable {
Item[] hashArr;
int size;
HashTable(int size) {
this.size = size;
this.hashArr = new Item[size];
}
int hash(int id) {
return id%10;
}
void insert(Item item) {
int hashCode = this.hash(item.id);
while (this.hashArr[hashCode] != null) {
hashCode = (hashCode + 1) % 10;
}
hashArr[hashCode] = item;
}
Item find(int id) {
int hashCode = hash(id);
while (hashArr[hashCode].id != id) {
hashCode = (hashCode + 1) % 10;
}
return this.hashArr[hashCode];
}
}
// 元数据
class Item {
String info;
int id;
Item(int id, String info) {
this.id = id;
this.info = info;
}
}
二叉查找树(BST)
BST相关知识参考了这一篇博客https://xblog.lufficc.com/blog/binary-search-tree
二叉搜索树(Binary Search Tree),又称为二叉查找树、有序或排序的二叉树,具有以下特性:
- 如果节点的左子树不空,则左子树上所有结点的值均小于等于它的根结点的值;
- 如果节点的右子树不空,则右子树上所有结点的值均大于等于它的根结点的值;
- 任意节点的左、右子树也分别为二叉查找树;
从特性上看,BST是满足范围查找的
BST查询
BST查找的时间复杂度是O(log2(n)),下面先解释为什么是这个复杂度
BST的查找的伪代码可以这么写:
TREE-SEARCH(x, k)
if x == nil or k == x.key //如不存在或者找到,直接返回
return x
if k < x.key //如果小于当前节点,根据性质,在左子树中搜索
return TREE-SEARCH(x.left, k)
else //如果大于等于当前节点,根据性质,在右子树中搜索
return TREE-SEARCH(x.right, k)
BST也属于二叉树,二叉树根节点只有1个(20),第1层最多有2个节点(21),2层最多有4个节点(22),以此类推,第n层就有2n个节点;所以,前n层总共有:
2^n + 2^(n-1) + ... + 2^1 + 2^0 = 2^(n+1) - 1 ; 等比数列求和
所以如果有k个数据(转为二叉树就是有k个节点),那么就有:
2^(n+1) - 1 = k
n = log2(k+1) - 1 约等于 log2(k),重点是对数
所以k个数据的二叉树就有log2(k)层,对于BST来说每一层会查询一次,所以最多有log2(k)次查询
可以看出来,BST和二分查找的思路是一样的,都是每一轮可以直接舍弃一半的数据,二分查找的时间复杂度也是O(log2(n)),当然二分查找的前提是排好序的数组
下面再计算下二分查找的时间复杂度:
假设有n个数据,第1次查找后还剩n/2个数据,第2次查找后还剩n/22,第k次查找后还剩n/2k个数据,那么极端情况就是第k次查找后就剩1个数据(无论最后一个数据是不是要找的,二分查找都已经结束了):
n/2^k = 1
2^k = n
k = log2(n)
下面也用java通过递归写一个二分查找的算法:
public class Hello {
public static void main(String [] args) {
System.out.println(Hello.binarySearch(new int[]{3,7,10,11,35,77,89}, 0, 7, 89));
}
static int binarySearch(int[] arr, int a, int b, int v) {
if (a == b) {
if (arr[a] == v) {
return a;
} else {
return -1;
}
} else {
int mid = (a+b)/2;
if (arr[mid]<v) {
return Hello.binarySearch(arr, mid+1, b, v);
} else if (arr[mid]>v) {
return Hello.binarySearch(arr, a, mid-1, v);
} else {
return mid;
}
}
}
}
BST插入
BST插入的时间复杂度和查找是一样的,都是log2(n)
红黑树
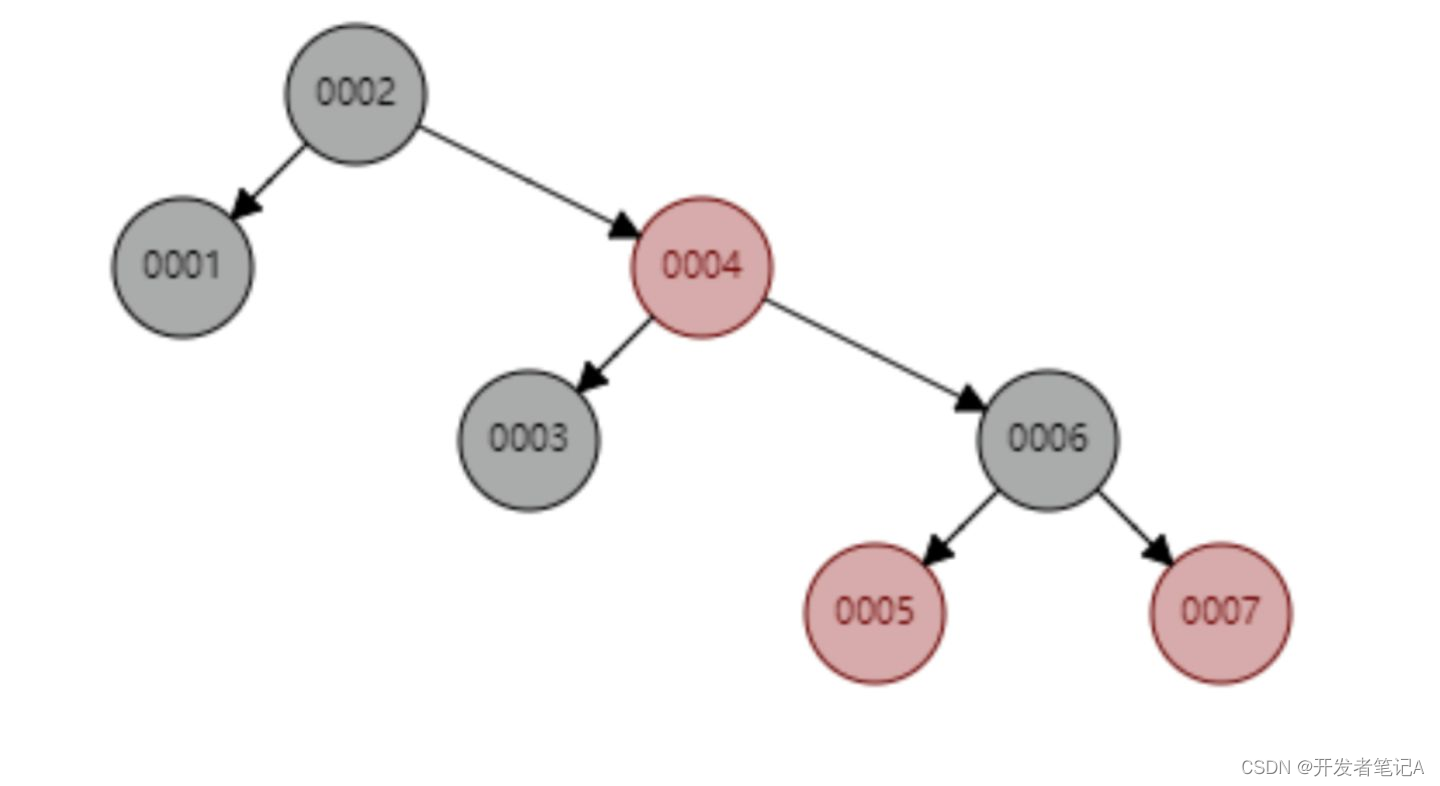
但BST也有缺陷,BST很容易起出现线型链表的情况,比如顺序插入1到7:

此时BST的查找和插入效率都退变成了O(n)
造成退化的本质是二叉查找树存在不平衡问题,因此学者提出通过树节点的自动旋转和调整,让二叉树始终保持基本平衡的状态,就能保持二叉查找树的最佳查找性能了。基于这种思路的自调整平衡状态的二叉树就是红黑树,红黑树具有以下特性:
- 每个节点都有红色或黑色
- 树的根始终是黑色的
- 没有两个相邻的红色节点(红色节点不能有红色父节点或红色子节点,并没有说不能出现连续的黑色节点)
- 从节点(包括根)到其任何后代NULL节点(叶子结点下方挂的两个空节点,并且认为他们是黑色的)的每条路径都具有相同数量的黑色节点
红黑树的调整给了两种方法:
变色和旋转
红黑树和AVL树相比多了变色这一种调平衡方法,因为变色比旋转时间复杂度要低,所以红黑树比AVL树调平衡的性能要好
且每次调整平衡操作的时间复杂度为O(log2(n))
这篇知乎博客详细介绍了这些规则https://zhuanlan.zhihu.com/p/79980618
比如顺序插入1到7,相比于BST的线型链表的极端情况,红黑树则会呈现以下结构:
AVL树
虽然相比BST来说,红黑树稍微平衡了些,但还并不是绝对平衡,这就引出了AVL树(平衡二叉树),AVL树每次调整可以保证树的绝对平衡,AVL树的特性如下:
- 左右子树的高度差小于等于 1
- 其每一个子树均为平衡二叉树
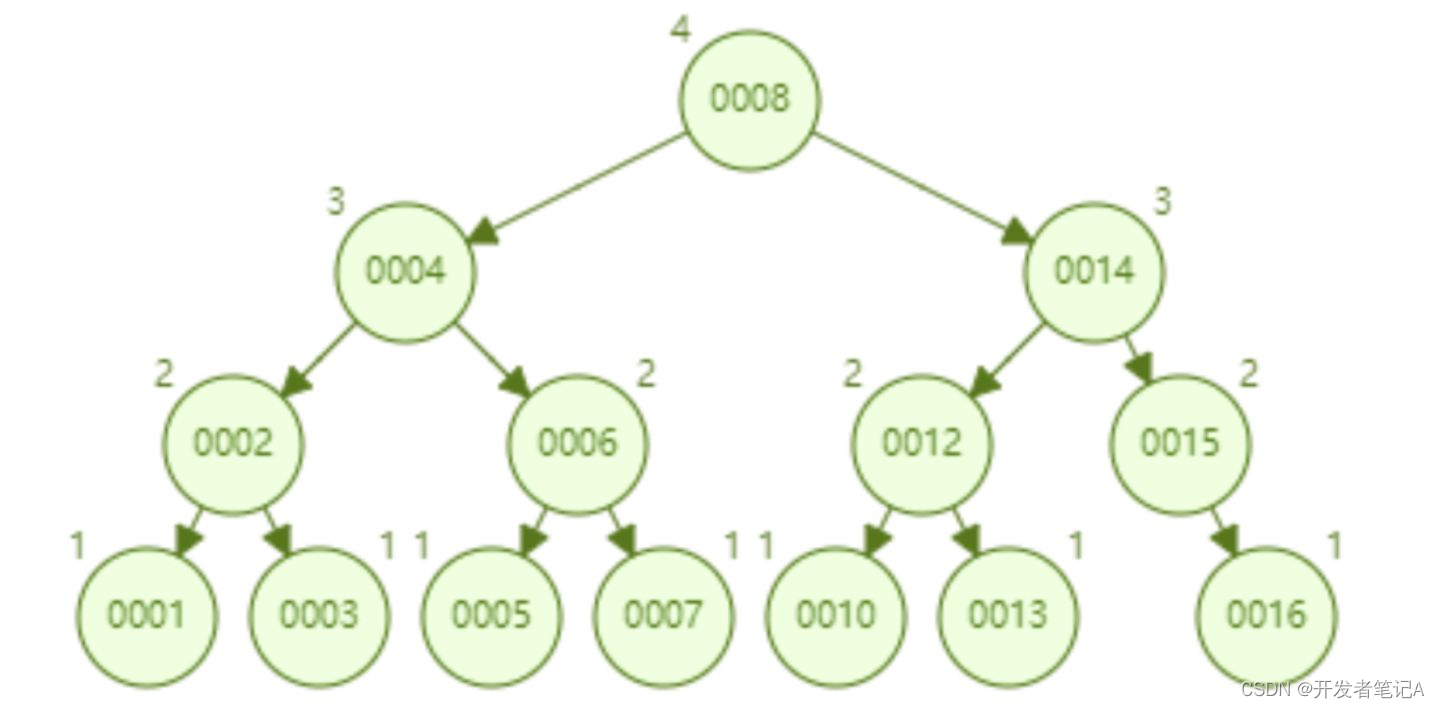
当某一节点的左右子树高度差大于1了,就会通过旋转的方式来平衡二叉树,使得高度差等于1,从而保证了查询的时间复杂度就是O(log2(n))。
这篇博客详细介绍了AVL树的旋转过程https://www.jianshu.com/p/65c90aa1236d
B树
AVL树在数据结构层面已经达到了最优解,保证log2(n)的查询速度,但是如果结合硬件就会发现另一个问题:以上面的AVL树为例,如果要查询id=7的数据,那么磁盘需要进行三次IO,分别取出0008、0004、0006来比较,当数据量级变大时IO的时间依然是瓶颈,这就引出了B树。
首先放一张B树结构示意图:
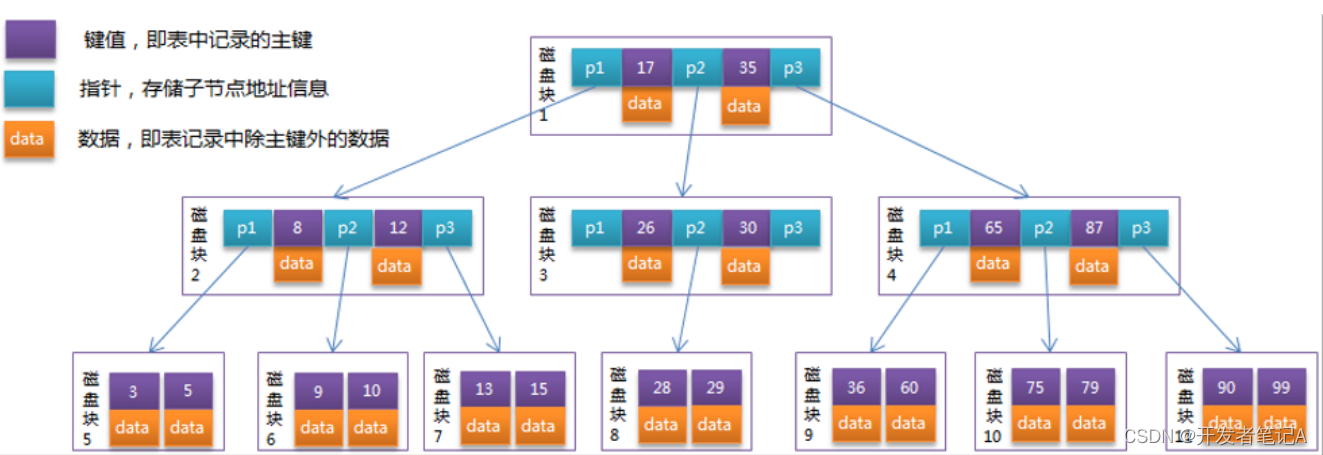
磁盘 IO 有个有个特点,就是从磁盘读取 1B 数据和 1KB 数据所消耗的时间是基本一样的(本文最开始提到的磁盘IO是以页为单位进进行读取的),我们就可以根据这个思路,我们可以在一个树节点上尽可能多地存储数据,一次磁盘 IO 就多加载点数据到内存,这就是 B 树,B+树的的设计原理了

从上图可以看出,每一个节点存储了最多可以按顺序的4个数据,这样查询id=7这个数据只要进行两次IO,每一次IO取出一组数据,如此B树的查找时间复杂度就是O(h*log2(n)),其中h是树高(这里h是小于log2(n)的)
这篇博客讲了B树的一些详细信息https://juejin.im/entry/6844903613915987975
B+树
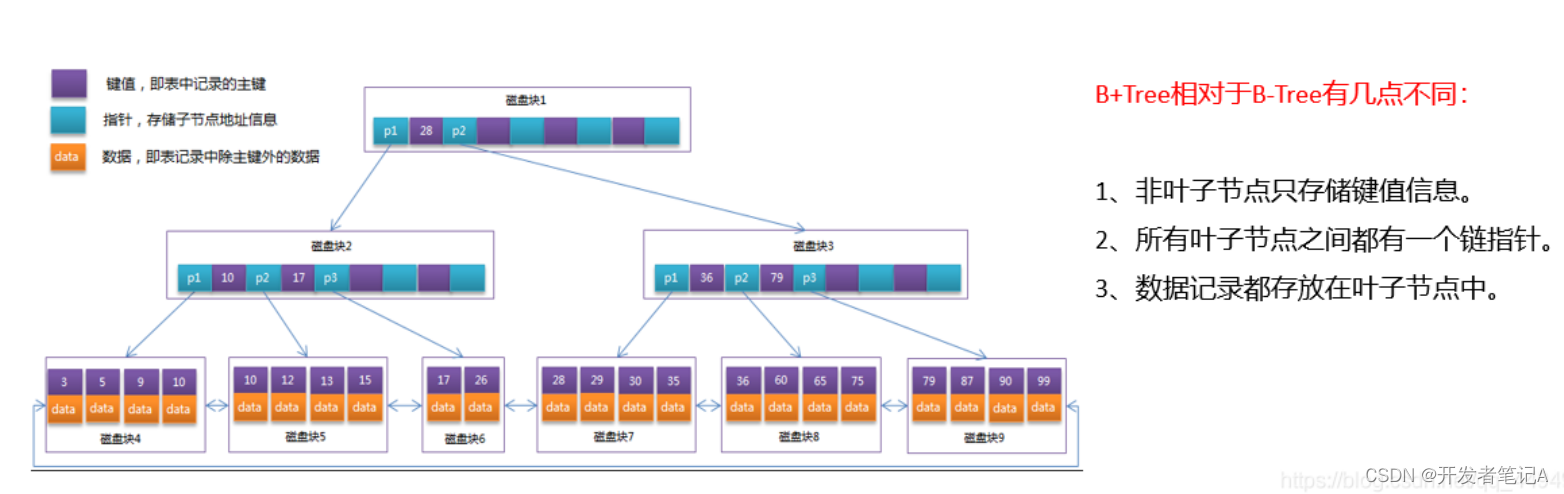
B+树相比于B树又做了优化,首先除了叶子节点,其他节点存储的都是索引(也就是key),而具体的数据存储在叶子节点,同时叶子节点用链表串联了起来:

这样B+树每个节点能存放更多的key,使树高度变低,查询速度更快
而MySql底层数据结构使用的正是B+树。
B+树结构示意图:















 1108
1108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









