







1 网页
分为静态页面和动态页面。
- 静态页面:内容是写死的,除非人为的进行内容修改,否则这个页面的内容是一成不变的。
- 动态页面:内容不是写死的,使用某种特殊的技术(JavaScript)使数据通过某种方式显示在页面中。
2 需要用到的库
- requests请求页面,得到的结果是静态页面的结果。
- BeautifulSoup(网页源码,解析器):将字符串类型的源代码转换为bs4类型。
- bs模块提供了一系列提取数据的方法,这些方法的操作对象的bs4类型的数据。
bs4模块能够从html或xml中提取数据
3 需要用到的方法
- select:根据CSS选择器(标签、class、id等)定位数据,得到的是符合这个选择器的所有结果(整体是列表,列表中每个元素是一个bs4类型的数据)。
- select_one:根据CSS选择器(标签、class、id等)定位数据,得到的是符合这个选择器的一个结果(是一个bs4类型数据)。
- text:从bs4类型数据中提取标签内的内容,结果为str。
- attris:从bs4类型数据中提取标签内容属性值,结果为str。
4 爬取数据的步骤
- 使用 requests请求页面,得到响应结果。
- 使用 BeautifulSoup4根据响应结果解析页面、提取数据。
- 将提取的数据写入文件、数据库。
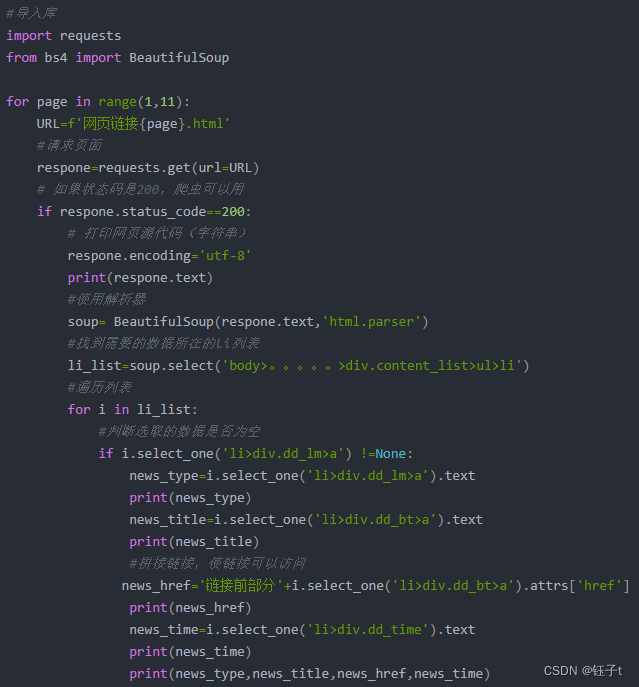
一个小栗子:















 1656
1656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









