




Wide&Deep 模型
Wide & Deep模型由Google在2016年提出。它旨在结合线性模型(Wide部分)的记忆能力和深度学习模型(Deep部分)的泛化能力,以解决推荐系统中的记忆性(Memorization)和泛化性(Generalization)问题。
基本思想
Wide&Deep模型的主要思路正如其名,是由单层的Wide部分和多层的Deep部分组成的混合模型。其中:
- Wide部分的作用是让模型具有记忆能力(memorization)
- Deep部分的作用是让模型具有泛化能力(generalization)
这样的结构使模型兼具了逻辑回归和深度神经网络的优点:
- 能够快速处理并记忆大量历史行为特征
- 具有强大的表达能力
记忆能力和泛化能力
记忆能力(Memorization):模型能够准确记住训练数据集中的特定模式和规律,并在相似的新数据上重现这些模式的能力。
具有强记忆能力的模型通常能够:
- 捕捉历史数据:记住用户过去的交互和选择,比如用户曾经购买过的商品或浏览过的内容。
- 重现用户偏好:在新的推荐中重现用户的已知偏好,例如推荐用户过去喜欢的音乐、电影或产品。
- 减少信息丢失:在处理大量数据时,能够保留关键信息,避免因模型复杂度不足而丢失重要特征。
然而,记忆能力强的模型可能会过度拟合训练数据,导致在未见过的数据上表现不佳。
泛化能力(Generalization):模型在未见过的数据上进行准确预测的能力。
具有强泛化能力的模型能够:
- 识别新模式:在新的、未见过的数据上识别出模式和规律,即使这些数据与训练数据不完全相同。
- 适应新情况:适应新环境和新用户,即使这些用户的行为模式与训练数据中的用户不同。
- 减少过拟合:避免在训练数据上过度拟合,保持模型在新数据上的预测能力。
泛化能力强的模型通常能够更好地处理新数据,但可能在捕捉训练数据中的细微模式方面不如记忆能力强的模型。
记忆与泛化的平衡
在推荐系统中,理想的模型应该同时具备良好的记忆能力和泛化能力。
通常来说,简单线性模型的“记忆能力”强,深度神经网络的“泛化能力”强,因此通过结合线性模型(Wide部分)的记忆能力和深度学习模型(Deep部分)的泛化能力,能够在保留用户历史偏好的同时,探索和学习新的用户行为模式,从而同时具备良好的记忆能力和泛化能力。
网络结构
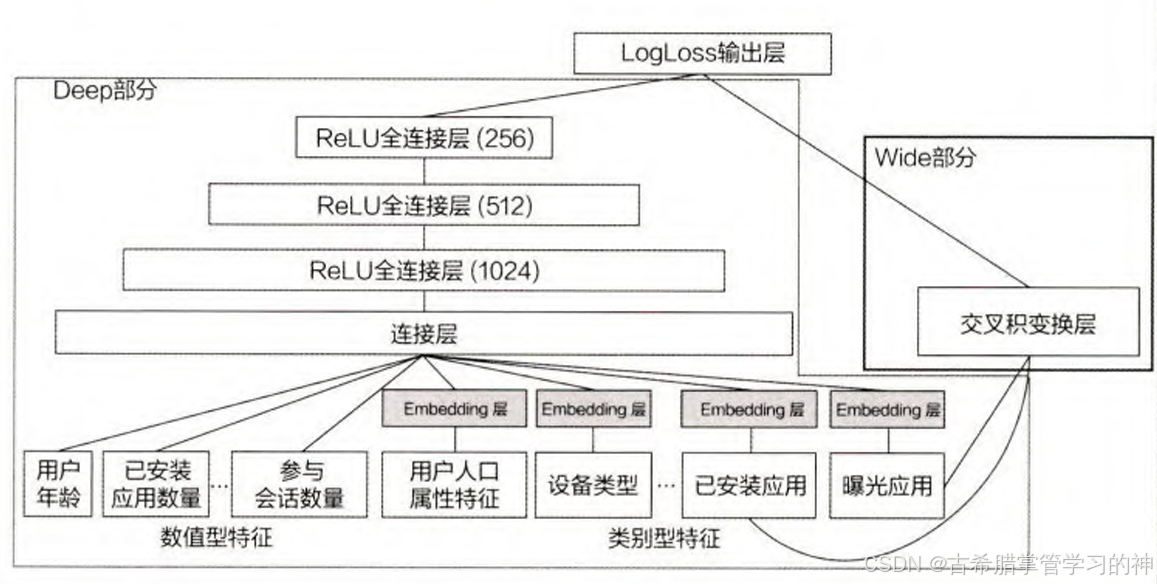
Wide部分(单输入层)
Wide部分通常指的是一个简单模型。简单模型善于记忆用户行为特征中的信息,并根据此类信息直接影响推荐结果。例如图中的已安装应用和曝光应用。
在Wide部分中,通常使用交叉积变换函数组合多个特征:
∅k(X)=∏i=1dxicki,cki∈0,1∅_k(X) = ∏_{i=1}^d x_i^{c_{ki}} , c_{ki} ∈ {0,1}∅k(X)=i=1∏dxicki,cki∈0,1
其中,∅k(X)∅_k(X)∅k(X) 表示第k个组合特征的交叉积变换结果,ckic_{ki}cki 是一个布尔变量,当第i个特征属于第k个组合特征时,ckic_{ki}cki的值为1,否则为0。
Deep部分(Embedding层和多隐层)
Deep部分使用嵌入层(Embedding Layer)来处理稀疏特征。嵌入层可以将高维稀疏特征映射到低维密集向量,这有助于模型捕捉特征间的非线性关系和深层次的交互。
通过多层神经网络结构,Deep部分可以进行更复杂的特征交叉和组合,挖掘数据中的深层模式和关系。这种深层的特征交叉是线性模型难以实现的。
输出层(逻辑回归模型)
Wide部分和Deep部分的输出被送入逻辑回归层,这个层将两部分的预测结果结合起来,形成一个统一的输出。这种结合可以是简单的加权求和,也可以是更复杂的融合方式。
输出层通常使用逻辑函数(如sigmoid函数)来将模型的输出转换为概率值,用于分类任务,如预测用户是否会点击某个广告或者是否会购买某个商品。
进化——Deep&Cross模型(DCN)
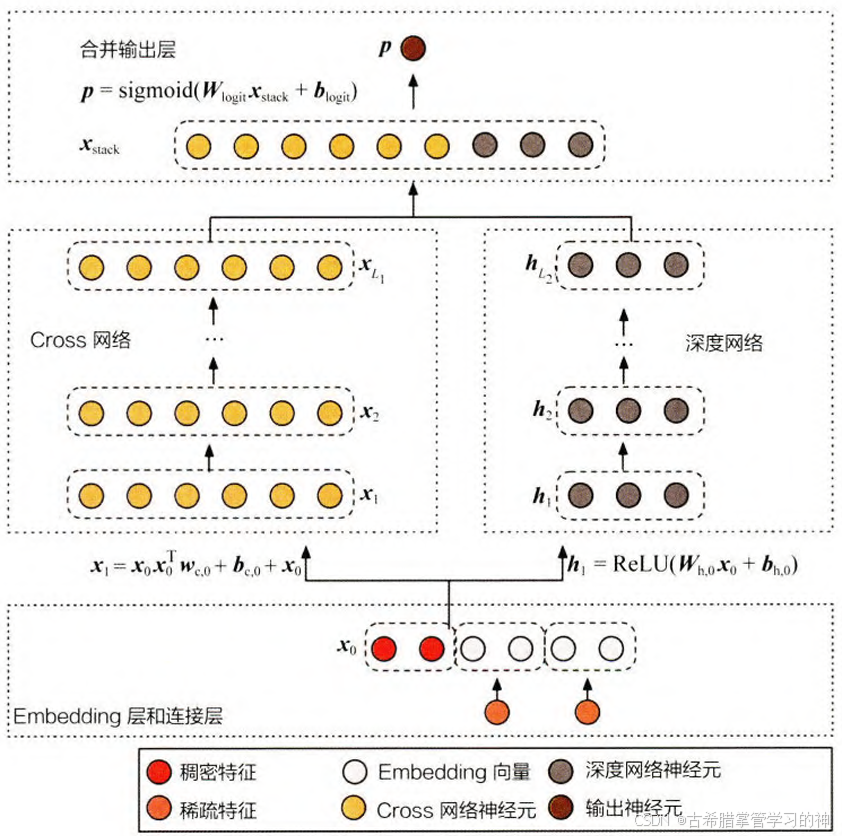
DCN对Wide & Deep模型中的Wide 部分进行改进,改成Cross网络
Cross网络的目的是增加特征之间的交互力度,使用多层交叉层对输入向量进行特征交叉
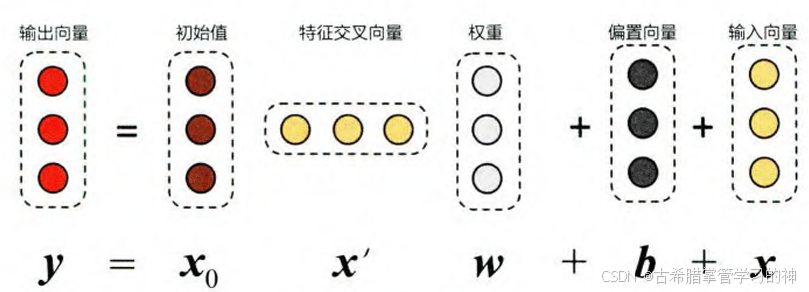
特点:
- 在Cross层中,权重 w为向量而非矩阵,这样的设计有助于减少模型参数,提高计算效率
- Cross Network引入了残差学习的思想,有助于避免梯度消失问题,并允许构建更深的网络,增强网络的表达能力
- Deep&Cross模型不需要人工特征工程来获得高阶的交叉特征,它能够自动学习特征交叉,有效地捕获有限阶上的有效特征交叉
优势
- 模型结构简单,易于理解和实现,效果优异,在工业界得到广泛应用
- 抓住了业务问题的本质特点,能够融合传统模型记忆能力和深度学习模型泛化能力的优势。
不足
- 尽管Deep部分减少了特征工程的需求,但Wide部分仍然需要人工进行特征工程
- 在用户-物品交互稀疏的情况下,Deep部分可能会过度泛化,导致推荐出与用户偏好不太相关的物品
参考
深度学习推荐系统(王喆)


















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









