






目录
并发:某一时间段内处理多件事情,交替执行
并行:同一时刻可以处理多件事情,同时执行
进程与线程
进程:正在运行的程序,是系统进行资源分配的最小单位
线程:运行在进程之上,是操作系统进行调度的最小单位
进程与线程之间的区别:
一个进程可以有一个以上的线程,进程之间都是独立的,一个进程内的线程共享这个进程空间。
同个进程内的线程是可以直接交流的,两个进程要想通信,必须要通过内核代理实现。
创建新的线程很简单,但是创建新的进程需要对父进程进行克隆,所有的进程都是由另外一个进程创建。
一个线程可以控制和操作同一个进程内的其他线程,进程只能操作子进程。
一个主线程改变可能会影响其他线程,一个父进程的改变不会影响子进程。
真正在CPU上面运行的是线程。
进程的状态模型(三态模型):
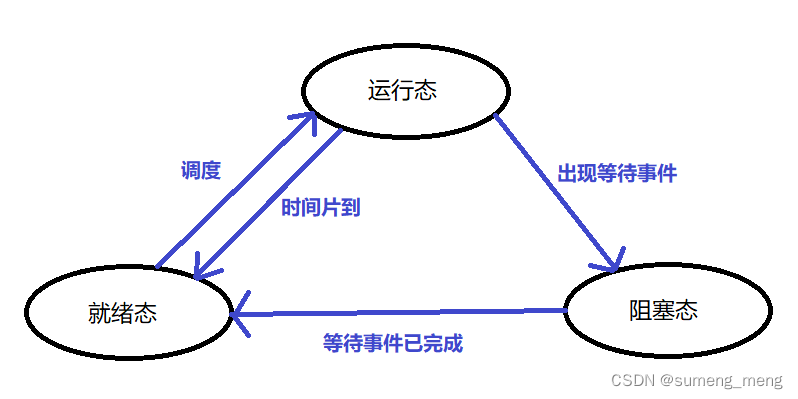
上下文切换:一个进程切换到另一个进程运行,就称为进程的上下文切换
一、多线程使用
threading库是Python的线程模型,使用threading库我们可以实现线程的并发,实现多线程任务
例题
通过计算请求一个页面所花费的时间,对比Python默认自上而下的串行执行和多线程并发执行花费时间的差异,感受一下并发执行
1.编写求花费时间的装饰器以及请求页面函数
import requests
import time
#求执行函数花费多少时间的装饰器
def runtime(func):
def inner(*args, **kwargs):
#获取请求页面前的时间
start = time.time()
result = func(*args, **kwargs)
#获取请求完页面后的时间
end = time.time()
print(f"spend {end - start}s to execute the function of requesting page")
return result
return inner
#请求页面函数
def get_content(url):
requests.get(url)
#使用time模拟阻塞时间
time.sleep(0.5)2.Python默认自上而下串行执行所花费的时间
@runtime
def main():
print("自上而下串行执行")
#多次请求页面
for i in range(5):
get_content("http://www.baidu.com")
main()
3.使用多线程并发执行
import threading
@runtime
def main():
print("多线程并发执行")
t_list = []
#模拟多次请求页面
for i in range(5):
t = threading.Thread(target=get_content, args=("http://www.baidu.com",))
#在t.start启动线程之前设置,默认就为False
t.setDaemon(False)
#启动线程,会自动调用t.run方法,t.run方法里面又会去调用传递进来的target
t.start()
#将线程实例存入列表,方便阻塞环境上下文
t_list.append(t)
#等线程全部创建启动后再join
for t in t_list:
#阻塞当前环境上下文,直到t的线程执行完成
t.join()
main()1.threading.Thread(target=get_content, args=("http://www.baidu.com",))中,target指定任务,传入callable对象(类、函数);args指定要传入的参数,传入的为元组--当只有一个参数时,最后要打逗号
2.t.setDaemon(),当设置False时,表示为前台线程--主线程会等到子线程结束才退出(默认);当设置True时,表示为后台线程--主线程一执行结束就退出
3.t.join,join所完成的工作就是线程同步--主线程任务结束之后,进入阻塞状态,一直等到其他子线程执行结束之后,主线程才会终止
4.总结
对比两种方式运行的结果来看,当有多个任务时,使用多线程执行效率会高许多
自定义线程类
可以对run方法进行重写,在启动线程时实现定制功能
#继承threading.Thread父类
class MyThread(threading.Thread):
def __init__(self, num):
#执行父类的__init__
super().__init__()
self.num = num
#重写run方法
def run(self):
print(f"the number {self.num} thread is running")
#通过自定义的线程类创建线程,并执行线程
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
二、线程锁
线程在同一个进程内是共享资源的,很容易发生资源的争抢,会产生脏数据
threading模块中提供了5种常见的锁,来保证线程安全,实现对各个线程之间数据的访问、修改变的可控
1.互斥锁lock
一次只放行一个线程,一个被加锁的线程在运行时不会将执行权交出去,只有当该线程被解锁时才会将执行权通过系统调用交给其他线程
当同一线程尝试多次获取同一个锁时,会产生死锁,如何避免产生死锁?
1.尽量避免同一个线程对多个lock进行锁定
2.多个线程对多个lock进行锁定,尽量保证它们以相同的顺序加锁
3.设置超时时间
2.可重入锁rlock
可重入锁是一种特殊类型的互斥锁,底层维护了一个互斥锁和一个计数器,可重入锁可以被拿到锁的线程多次获取,但必须以相同的次数释放,才能真正释放多锁的拥有权
可重入锁与互斥锁的主要区别就是,可重入锁允许同一个线程多次获取同一个锁,而不会产生死锁
互斥锁--一个线程尝试多次获取同一个锁,会产生死锁:
import threading
lock = threading.Lock()
lock.acquire()
print("lock acquire 1")
#同一线程未释放,又去尝试获取同一个原始锁
lock.acquire()
print("lock acquire 2")
lock.release()
print("lock release 1")
lock.release()
print("lock release 2")
可重入锁--同一线程多次获取同一个锁不会产生死锁:
import threading
lock2 = threading.RLock()
lock2.acquire()
print("lock1 acquire 1")
#不会产生死锁
lock2.acquire()
print("lock1 acquire 2")
lock2.release()
print("lock1 release 1")
lock2.release()
print("lock1 release 2")
3.条件锁condition
内部是通过lock和rlock锁实现的,并且在此基础上增加了暂停线程运行的功能,允许一个或多个线程等待某个条件满足才被唤醒
4.事件锁event
事件锁是基于条件锁来做的,它与条件锁的区别在一次只能放行全部,不能放行任意数量的子线程运行
事件锁对象中有一个信号标志,默认为False,如果一个线程等待一个Event对象,那么这个Event对象的标志将决定这个线程是否会被阻塞,如果一个线程将Event对象的标志设置为真,那么所有等待这个Event对象的线程都将会被放行
5.信号量锁semaphore
允许一定数量的线程同时访问锁,可以用semaphore来控制线程的并发数量
三、全局解释器锁
GIL全局解释器锁是解释器层面的锁,是CPython的历史遗留问题,在CPython解释器中,GIL是一把互斥锁,用于阻止同一个进程下多个线程的同时执行。
基本行为:
1.当前执行的线程必须要有全局解释器锁
2.当遇到io阻塞或者CPU时间片到,都会释放全局解释器锁
四、多进程
进程的组成
进程控制块(PCB):进程标识符pid、进程优先级、进程当前状态、进程相应的程序和数据地址、进程资源清单(打开的文件列表等)等
数据段:存放程序运行过程中处理的各种数据
正文段:存放要执行的程序代码
僵尸进程与孤儿进程
正常情况:子进程由父进程创建,子进程再创建新的进程。当子进程结束后,它的父进程会调用wait()或者waitpid()取得子进程的终止状态,回收子进程的资源
僵尸进程:子进程退出了,但是父进程没有响应--没有调用wait或者waitpid方法去获取子进程的状态,那么这个子进程的进程描述符就会依然存在系统中,这种进程就称为僵尸进程
孤儿进程:父进程退出了,子进程还在运行,那么这个子进程就被称为孤儿进程,孤儿进程会被pid为1的进程收养
多进程模块
multiprocessing是Python中实现多进程的模块
在multiprocessing中,通过创建一个Process对象然后调用其start()方法来生成进程,例:
from multiprocessing import Process, current_process
import time
lst = []
def task():
# current_process()表示当前进程
print(current_process().name, f"start...{i}")
time.sleep(2)
# 用于展示各个进程都拥有一份数据,相互隔离
lst.append(i)
print(f"lst is {lst}")
print(current_process().name, f"end...{i}")
#只有直接运行时才能创建多进程
if __name__ == "__main__":
for i in range(4):
p = Process(target=task, args=(i + 1,))
p.start()
自定义进程类
对run方法进行重写
from multiprocessing import Process
class MyProcess(Process):
def __init__(self, value):
super().__init__()
self.value = value
def run(self):
print(f"running...{self.value}")
if __name__ == "__main__":
p1 = MyProcess(1)
p2 = MyProcess(2)
p1.start()
p2.start()
进程之间共享数据
1.manager
Python通过manager方式实现多个无关联进程共享数据
from multiprocessing import Process, Manager, Lock
import time
def task(i, temp, lock):
with lock:
print(f"start {i}......")
time.sleep(1)
temp.append(i + 1)
print(temp)
if __name__ == "__main__":
# 创建数据共享对象,底层为socket通信
m1 = Manager()
# 用manager方法创建列表--创建出来的变量可以在不同进程之中修改
temp = m1.list([0])
#为了防止资源争抢出现脏数据,设置进程锁
lock = Lock()
p_list = []
for i in range(5):
p = Process(target=task, args=(i, temp, lock))
p.start()
p_list.append(p)
# 等待子进程运行完成,父进程先退出的话,Manager共享就没用了
[p.join() for p in p_list]
2.queue
queue是一个消息队列来实现进程之间数据共享
queue最大的优势在于它是线程安全的,其中的put、get操作都是原子操作--要么成功要么失败,没有执行到一半的情况
from multiprocessing import Process, Queue
def task(i, q):
#q.empty()判断队列是否为空
if not q.empty():
#取出队列中的数据
print(i, "--> get value", q.get())
if __name__ == "__main__":
q = Queue()
for i in range(5):
#向队列中存放数据
q.put(i)
p = Process(target=task, args=(i, q))
p.start()
进程池
如果有多少个任务就开启多少个进程,其实并不划算,进程池就是用固定的进程数去执行同样多的任务,采用预创建的技术,在应用启动之初便预先创建一定数量的进程
Python中使用Pool实现进程池,Pool类可以指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求;如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
from multiprocessing import current_process, Pool
import time
def task(i):
print(current_process().name, f"start......{i}")
time.sleep(2)
print(current_process().name, f"end......{i}")
if __name__ == "__main__":
p = Pool(processes=4, maxtasksperchild=2)
for i in range(8):
#进程池接收任务,apply_async是非阻塞的
p.apply_async(func=task, args=(i, ))
#关闭进程池,不接受任务了
p.close()
#阻塞当前环境
p.join()
print("process end......")其中的Pool(processes=4, maxtasksperchild=2)中,processes表示指定进程池中的进程数,建议进程数与cpu核数一致;maxtasksperchild指定每个子进程最多处理多少个任务,达到相应的任务数后当前进程就会退出,开启新的进程,指定maxtasksperchild就是为了定期释放资源
五、协程
协程是一种用户态的轻量级线程,协程的调度完全由用户控制,协程拥有自己的寄存器上下文和栈,在执行函数A时,可以随时中断去执行函数B,然后又中断继续执行函数A
asyncio是Python实现协程的模块
import asyncio
import time
#定义协程函数 async是定义一个协程的关键字
async def say_after(delay, what):
print(f"test start.....{what}")
#await是用于挂起阻塞的异步调用接口的关键字
await asyncio.sleep(delay)
print(what)
async def main():
#asyncio.create_task函数用来并发运行作为asyncio任务的多个协程
task1 = asyncio.create_task(
say_after(1, 'hello'))
task2 = asyncio.create_task(
say_after(2, 'world'))
print(f"started at {time.strftime('%X')}")
await task1
await task2
print(f"finished at {time.strftime('%X')}")
#asyncio.run函数用来运行最高层级的入口点main()函数
asyncio.run(main())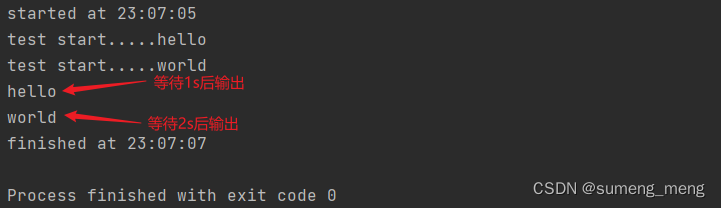














 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









