






一、深层网络的退化问题
理论上来说,堆叠神经网络的层数可以提升模型的精度,但现实中真的如此吗?
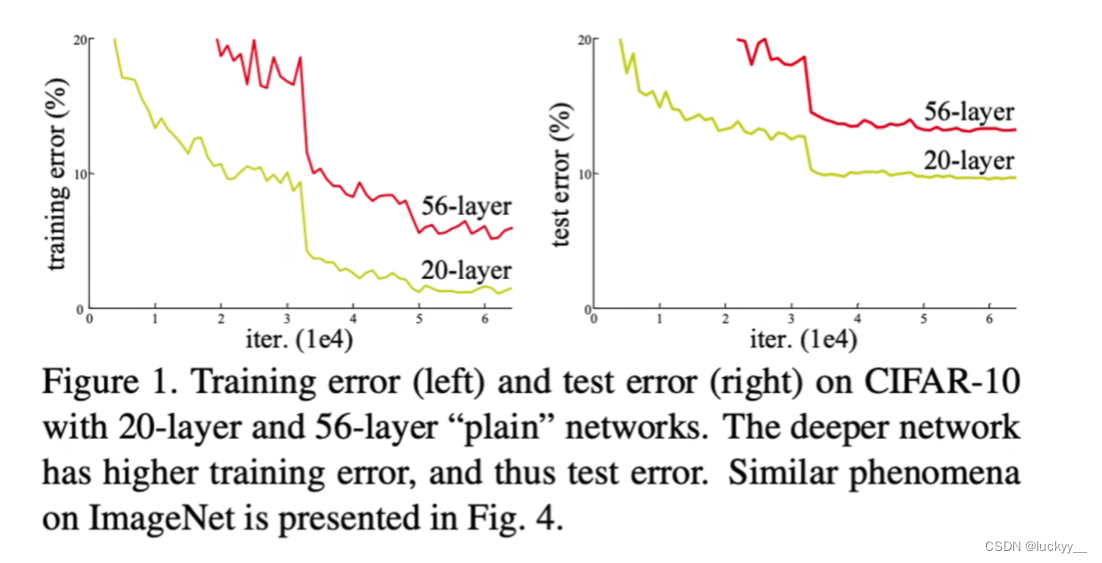
1、退化
对于这个问题,实验数据证明,一开始随着模型层数的的增加,模型精度会达到饱和,但是如果再继续增加,它就开始退化了,从上图的实验数据中我们可以看到,在训练轮次相同的的情况下,56层的网络误差居然比20层的网络还要高,这个现象是由于深层网络训练难度太高导致的,我们给这个现象起名叫做退化。
退化和过拟合的区别:
过拟合:训练误差越来越小,测试误差变高。
退化:训练误差和测试误差都会变高。
深度神经网络还有一个难题。
2、梯度消失
以一个神经网络为例,在反向传播的过程中,可以推导出每一层的误差项都依赖于它后面一层的误差项(链式法则)。在层数很多的情况下,难以保证每一层的权值和梯度的大小。例如,激活函数sigmoid,其导数最大值只有0.25,梯度在传播过程中越来越趋近于0。如此,误差就无传播到底层的参数了,这就是梯度消失。
目前针对这种现象已经有了解决的方法:对输入数据和中间层的数据进行归一化操作,这种方法可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再往深处走的时候,这种方法就无用武之地了。
二、残差网络
假设神经网络到L层时达到了最优,此时,再往下加深网络就会出现退化问题(错误率上升的问题)。那么第L层之后的每一层,理论上说应该均是恒等映射才不会出现退化,但是拟合一个恒等映射是困难的。
但是采用残差网络就能很好的解决这个问题。
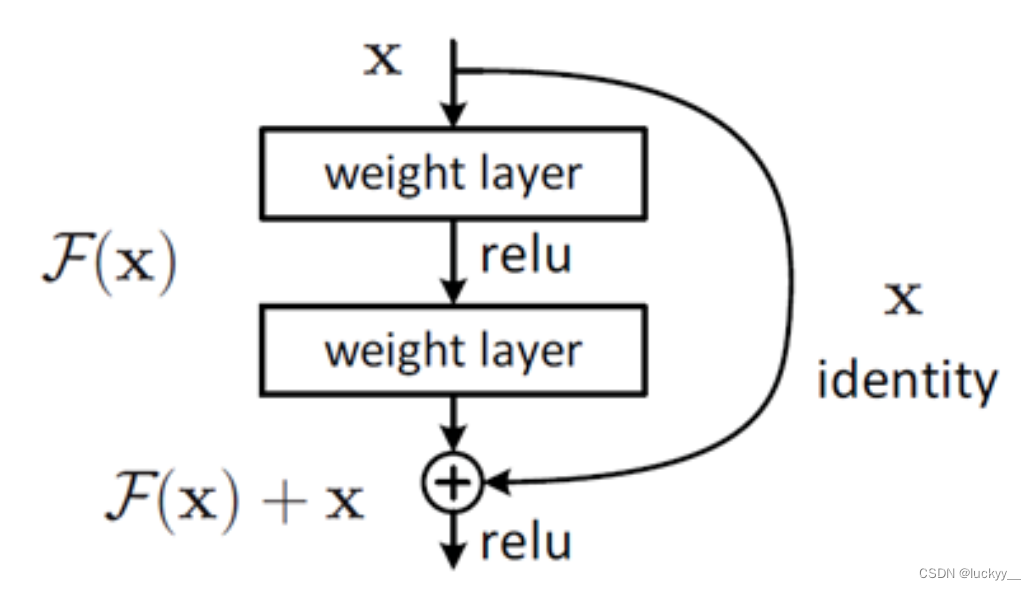
如果我们用 来表示我们想让这个神经网络学到的映射,用
来表示我们已经学到的内容,那么现在,我们希望神经网络去拟合
和
之间的残差
,也就是说我们选择优化的不是
,而是把
拆分为
和
两个部分,我们选择去优化
,
通常包括这卷积和激活之类的操作,我们把
和
相加之后,仍然能得到我们想要的
,如果让
,可以得到
,就相当于我们构造了一个恒等映射。
直观理解的话,采用ResNet只用小小的更新F(x)部分的权重值就行,不用像一般的卷积层一样大动干戈。















 110
110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









