







目录
数据库(一)
8.31
数据和信息
Data数据,任何描述事物的文字或符号都可以称为数据
软件开发就是为了收集数据,从中筛选出有用的信息
信息是经过分析筛选后的数据
数据需要保存,保存的介质有内存和硬盘
内存中的数据是临时的,随着软件或系统的关闭,数据也会消失
硬盘中的数据是永久的,就算系统关闭,数据依然保留
excel等文件保存数据就是一种保存到硬盘中的途径
如果需要大量数据的保存,文件系统就不再方便,使用系统化的数据仓库高效地管理数据
数据库DB
DataBase,称为数据库,简称为DB,运行在操作系统上
按照一定的数据结构,保存数据的仓库,是一个电子化的文件柜。
数据永久保存在硬盘中
数据库管理系统
DataBase Manager System,简称DBMS,通常所说的数据库,其实是指数据库管理系统
如MySQL、SQLServer、Oracle等
数据库管理系统是一种操作和管理数据库的大型软件,用来创建、使用和维护数据库
总结
数据Data是一个软件的根本,数据要永久地保存到数据库中
数据库DB是一个运行在操作系统上的软件
数据库管理系统DBMS是管理数据库的一个软件
学习数据库,就是学习如何使用DBMS创建、使用数据仓库来管理数据
常见的数据库管理系统
关系型数据库[永久存]
关系型数据库是主流的数据库类型,数据通过行row和列column的形式(表格)保存
优点
- 易于维护:数据都是以表的结构保存,格式一致
- 使用方便:SQL语句通用,可以用于不同的关系型数据库
- 支持复杂查询:可以通过SQL语句在多个表之间进行关联查询
缺点
- 读写性能由硬盘的读写速度相关
- 海量数据处理时,若频繁读写,效率变低
- 表结构不易改动,灵活度欠佳
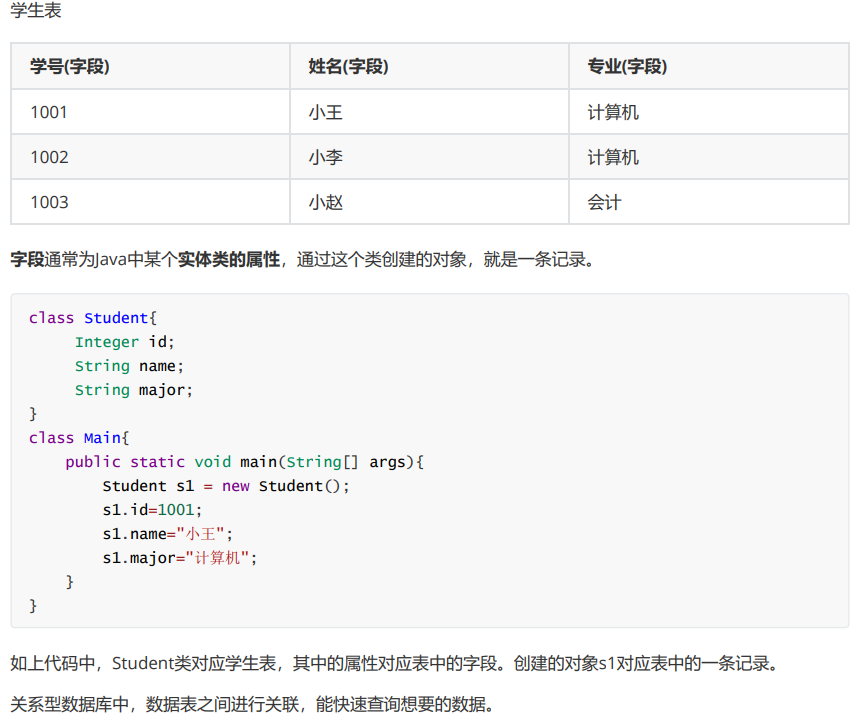
每行称为一条记录,每列称为一个字段
字段通常为Java中某个实体类的属性,通过这个类创建的对象,就是一条记录
非关系型数据库[临时存]
数据通过对象的形式保存,对象可以是一个键值对、文档、图片等
特点
- 保存数据的格式多样
- 数据保存在内存中,对于海量数据的读写性能高
- 不支持复杂查询
MySQL纯命令简单使用
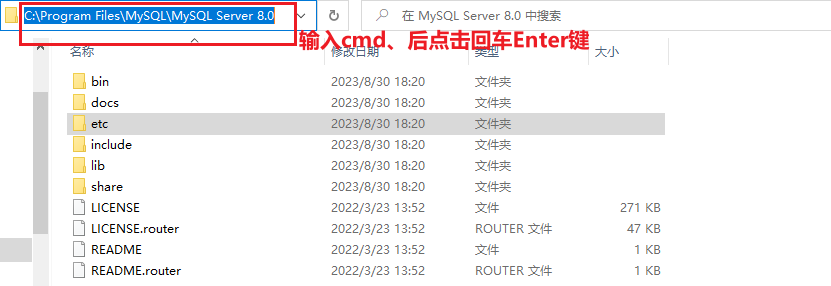
在安装目录的bin文件夹中,输入cmd进入控制台
默认安装目录为C:\Program Files\MySQL\MySQL Server 8.0
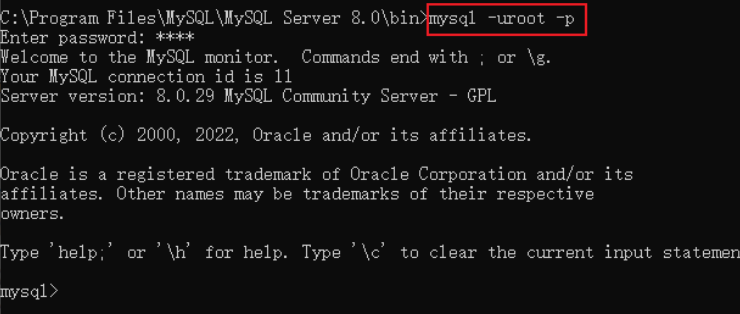
输入mysql -u root -p 后回车,输入安装时的密码
常用指令
| 命令 | 描述 |
|---|---|
| show databases; | 查看所有的数据库 |
| use 数据库名; | 进入指定数据库 |
| show tables; | 查看某个数据库中中的所有表 |
| create database 数据库名; | 创建指定数据库 |
| drop database 数据库名; | 删除指定数据库 |
| create table 数据表名; | 在某个数据库,创建一个数据表 |
show databases;
show databases

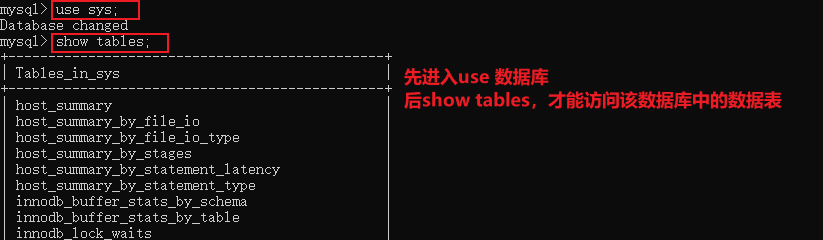
use 数据库名;与show tables;
必须先启用use 数据库名命令,show tables命令才能访问该数据库的数据表
use sys 与show tables
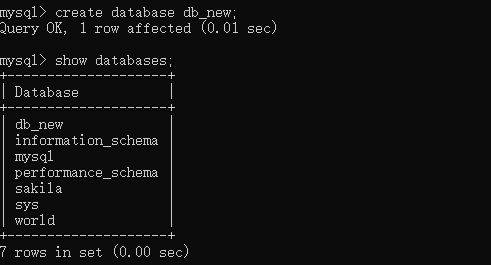
create database 数据库名;
create database db_new;
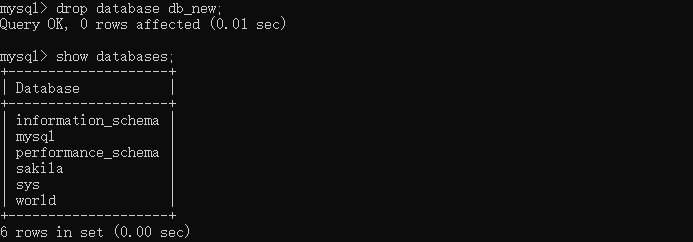
drop database 数据库名;
drop database db_new;
数据库管理系统图形化管理工具
若只使用控制台操作数据库系统很不方便,因此在windows下有很多图形化的管理工具
如navicat、datagrip、sqlyog等
安装Navicat
微信公众号:软件管家
Navicat的使用
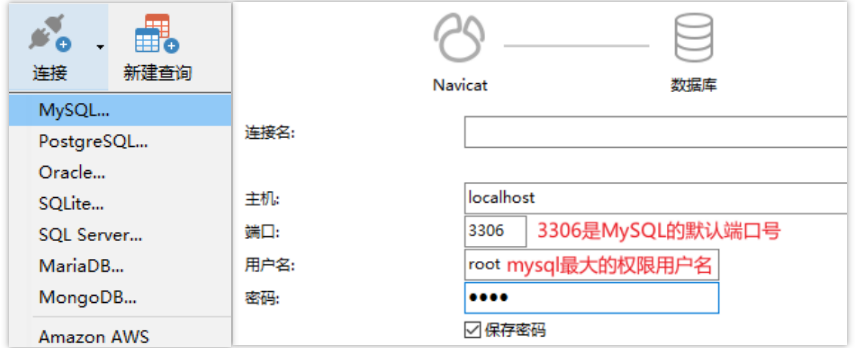
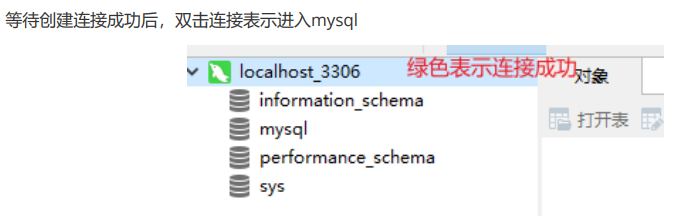
创建mysql连接点击后、输入mysql登录密码
创建数据库、删除数据库
在连接上右键,点击新建数据库,只需填写数据库名
在对应的库上右键删除数据库
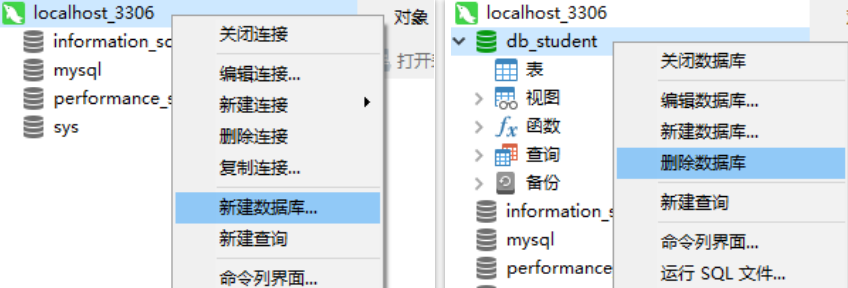
切换数据库
双击对应的数据库,类似于"use 数据库"指令
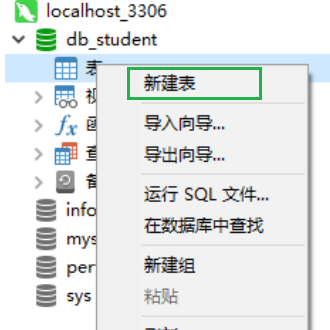
创建数据表
在展开后的数据库中,在表的选项上右键新建表
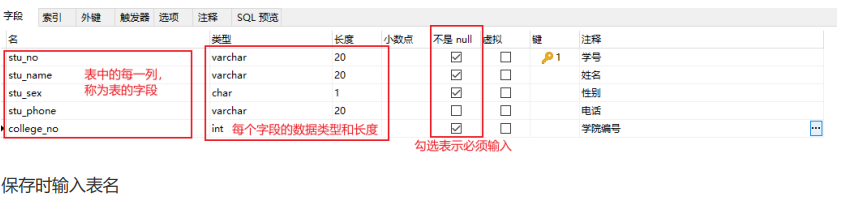
建表时注意
- 由于MySQL大小写不敏感,数据库名、表名、字段名全部使用小写字母,多个单词之间用下划线_隔开
- 数据类型和所占长度根据实际情况选择
- 如果某列数据必须要填写,将"不是null"勾选
- 如果某个字段有默认值,可以在设计表的时候设置
- 每张表通常会设置一个编号"id"列,将其设置为主键,目的是为了区分每条记录
- 主键列中的数据不能重复,通常还会将主键列设置为整型,自增
- 最好加上注释
数据完整性
数据完整性是指数据精确可靠,不能保存无意义或无效的数据
如不合理的年龄性别、全部为空的记录、重复记录等
为了保证保存在数据库中的数据是完整数据,在设计数据表的时候添加一些约束或字段特征来保证数据完整性
MySQL中常见的数据类型
整型
| 整型 | ||
|---|---|---|
| tinyint | 对应Java中的short | 短整型 |
| int | 对应Java中的int | 整型 |
| bigint | 对应Java中的long | 长整型 |
浮点型
| 浮点型 | ||
|---|---|---|
| float | 对应Java中的float | 单精度浮点型 |
| double | 对应Java中的double | 单精度浮点型 |
| decimal(宽度,精度) | 指定保留的小数位数和整体宽度 | 如decimal(4,2) 3.14159 --> 3.14 |
字符串
| 字符串 | ||
|---|---|---|
| char(数字) | 定长字符串 | 对应Java中的String char(10)表示就算实际保存4个字符,也占10个长度 |
| varchar(数字) | 可变字符串 | 对应Java中的String varchar(10)表示如果实际保存4个字符,占4个长度 |
| text | 文本 | 字符串长度过大时使用 |
日期
| 日期 | ||
|---|---|---|
| date | 日期 | yyyy-MM-dd |
| time | 时间 | HH:mm:ss |
| datetime | 日期时间 | yyyy-MM-dd HH:mm:ss |
| timestamp | 时间戳 | 保存日期的毫秒数 |
约束
| 基本约束 | 关键字 |
|---|---|
| 非空约束 | not null |
| 主键约束 | primary key |
| 唯一约束 | unique |
| 默认值约束 | default |
| 外键约束 | foreign key、references |
字段值自增:auto_increment
字段数据类型需为int
非空约束not null
关键字:null
- 不写或设置null表示允许为空
- not null表示不能为空
- 用于控制某个字段能否为null
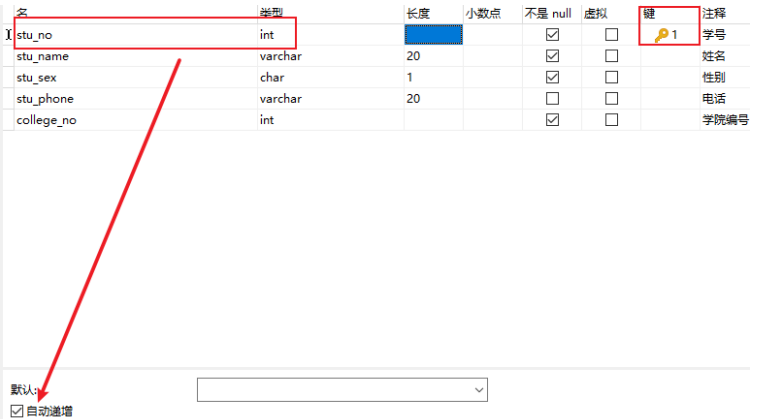
主键约束primary key
关键字:primary key
-
主键primary key:也称为主关键字、主码,用于区分表中的每条记录
若有现成字段可以区分每条记录时,将该字段设置为主键,如身份证号、学号等;
若没有现成的字段区分每条记录时,通常会额外添加一个id字段设置为主键
-
通常一张表中只选择一个字段作为主键
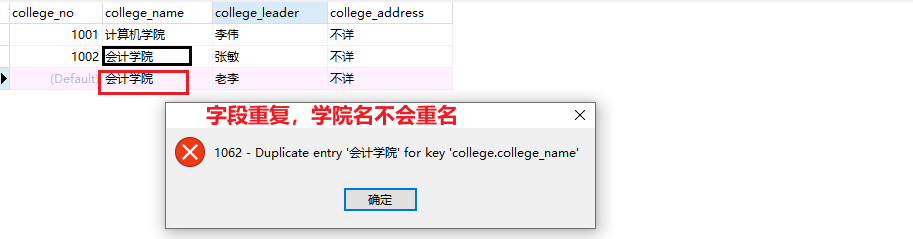
唯一约束unique
关键字:unique
- 用于控制该字段不能重复
- 可以在建表的时候设置唯一约束的字段

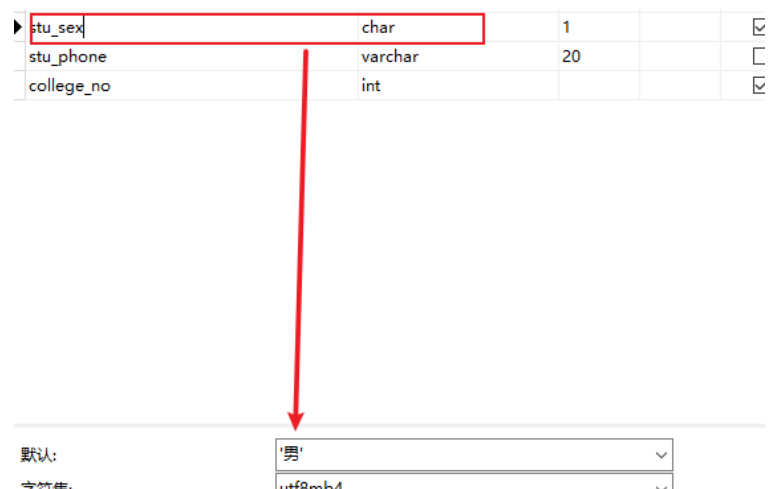
默认值约束defalut
关键字:defalut
- 用于添加记录时,可以自动填充一个默认值
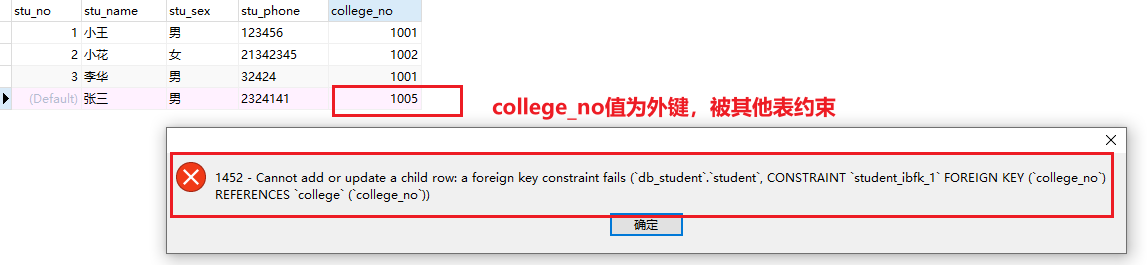
外键约束foreign key 、references
关键字:foreign key 、references
-
在主从关系的表中,给从表中的某个字段添加外键约束,引用主表中的某个字段,这样从表中的外键字段的值只能来自于主表中
如学院表为主表,学生表为从表,学生表中的学院编号只能来自于学院表中的学院编号

SQL
Structrued Query Language 结构化查询语言,用于操作关系型数据库的一门语言;可以用来创建、维护数据库和数据
操作数据库
| SQL语句 | 用法 |
|---|---|
| create database 数据库名; | 创建数据库 |
| use 数据库名; | 切换数据库 |
| drop database 数据库名; | 删除数据库 |
操作数据表
创建数据表
create table 表名(
字段名1 数据类型 [字段特征],
字段名2 数据类型 [字段特征],
...
字段名n 数据类型 [字段特征],
)
sql 语句中的注释:两个减号+一个空格
字段自增:auto_intcrement
字段添加备注:comment ‘注释内容’
use db_student;
create table sport_list(
-- 编号
id int not null primary key auto_increment comment '编号',
-- 姓名
name varchar(20) not null comment '姓名',
-- 性别
sex char(1) default '男' not null comment '性别',
-- 参加的项目
item varchar(20) not null comment '项目'
)
练习

-- 创建"游戏库" db_gane
create database db_game
-- 切换到db_game库中
use db_game
create table hero(
-- 编号 非空
id int not null comment '编号',
-- 姓名 非空
name varchar(20) not null comment '姓名' ,
-- 性别 非空
sex char(1) not null comment '性别',
-- 定位
position varchar(20) comment '定位',
-- 价格
price double comment '价格'
)
修改表结构alter
| SQL语言 | 用法 |
|---|---|
| alter table 表名 rename to 新表名; | 数据表重命名 |
| alter table 表名 add column 字段名 数据类型 [字段特征]; | 添加字段 |
| alter table 表名 change 旧字段名 新字段名 数据类型 [字段特征]; | 修改字段 |
| alter table 表名 drop 字段名; | 删除字段 |
| truncate table 数据表名; | 在某个数据库,清空该数据表里所有数据 |
数据表重命名
alter table 表名 rename to 新表名;
-- 表名hero,重命名为hero_info
alter table hero rename to hero_info;
添加字段
alter table 表名 add column 字段名 数据类型 [字段特征];
-- hero_info表添加新字段 上架时间
alter table hero_info add column create_date date;
修改字段
alter table 表名 change 旧字段名 新字段名 数据类型 [字段特征];
-- 字段position重命名
alter table hero_info change position wags varchar(30);
删除字段
alter table 表名 drop 字段名;
alter table hero_info add column addr char(1);
-- 删除addr字段
alter table hero_info drop addr;
添加约束
| SQL语句 | 用法 |
|---|---|
| alter table 表名 add unique(字段名) | 添加唯一约束 |
| alter table 表名 add primary key(字段名) | 添加主键约束 |
| alter table 表名 alter 字段名 set default ‘默认值’; | 添加默认值约束 |
| alter table 从表表名 add foreign key(从表外键字段) references 主表表名(主表字段) | 添加外键约束 |
添加唯一约束
alter table 表名 add unique(字段名);
-- 字段name加唯一约束
alter table hero_info add unique(name);
添加主键约束
alter table 表名 add primary key(字段名);
-- 字段id加主键约束
alter table hero_info add primary key(id);
添加默认值约束
alter table 表名 alter 字段名 set default ‘默认值’;
-- 字段sex加默认约束
alter table hero_info alter sex set default '男';
添加外键约束
alter table 从表表名 add foreign key(从表外键字段) references 主表表名(主表字段)
-- 创建从表battle
create table battle(
-- 编号
id int not null,
-- 皮肤
skin varchar(20)
);
-- battle表id字段添加外键
alter table battle add foreign key(id) references hero_info(id);
删除数据表
drop table 表名
存在外键约束时,需删除从表,再删除主表

-- 存在外键约束,先删除从表,再删除主表
drop table battle;
drop table hero_info;
创建表的同时添加约束
在创建表时添加约束
use db_game;
CREATE TABLE hero(
-- 编号id,非空 主键 自增 注释
id INT not null PRIMARY key auto_increment COMMENT '编号',
-- 姓名 非空 唯一
name varchar(20) not null unique comment '姓名',
-- 性别 非空 默认值男
sex char(1) not null default '男' comment '性别',
-- 价格 非空
price double not null comment '价格',
-- 上架时间
create_date date comment '上架时间',
-- 定位
position varchar(20) comment '定位'
);
-- battle
CREATE TABLE battle(
-- 人物编号 非空 外键 引用hero表中的编号字段
indn int not null comment '人物编号',
-- 分路 非空
way VARCHAR(20) not null comment '分路',
-- 外键引入
foreign KEY(indn) references hero(id)
)
MySQL彻底删除干净
参考:
彻底卸载mysql的详细步骤_mysql卸载如何彻底删除_云边的快乐猫的博客-CSDN博客
MySQL的卸载、下载、安装详细讲解_mysql-5.7.20卸载_牛·云说的博客-CSDN博客
MySQL8.x下载与安装
mysql官网MySQL
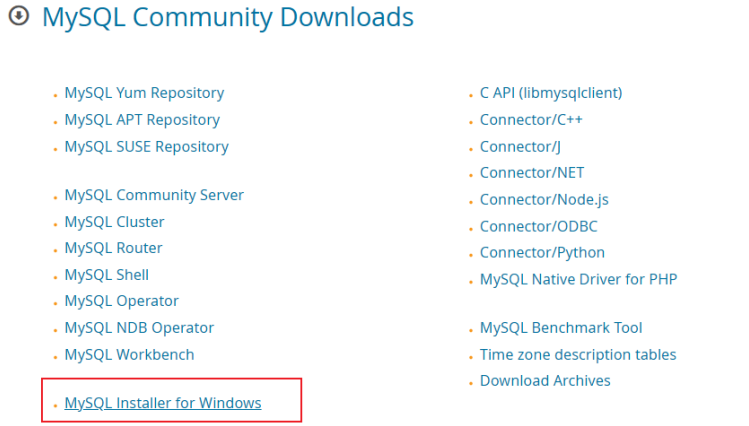
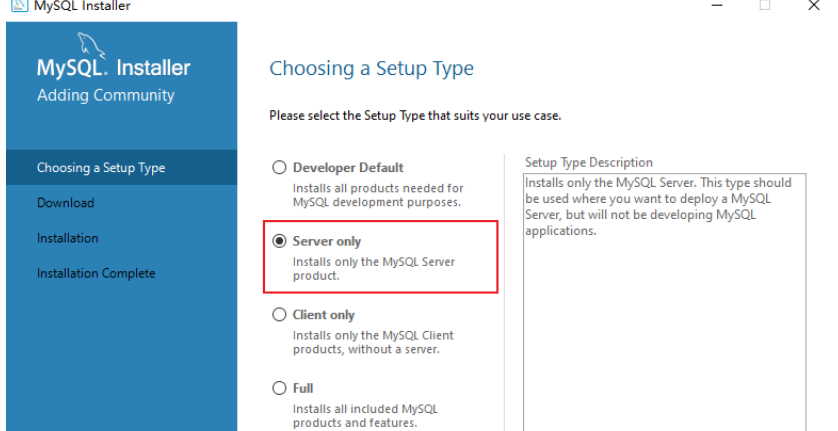
数据库8.0修改密码
在Windows系统中,以命令行方式,输入 mysql 后
提示错误:ERROR 1045 (28000): Access denied for user ‘ODBC’@‘localhost’ (using password: NO),即使用了错误的用户尝试登录MySQL

当不指定登录用户时,Windows 在连接 MySQL数据库的时候,就会使用 ODBC 用户去连接
查看版本:mysql --version[必须在终端配置其mysql环境]
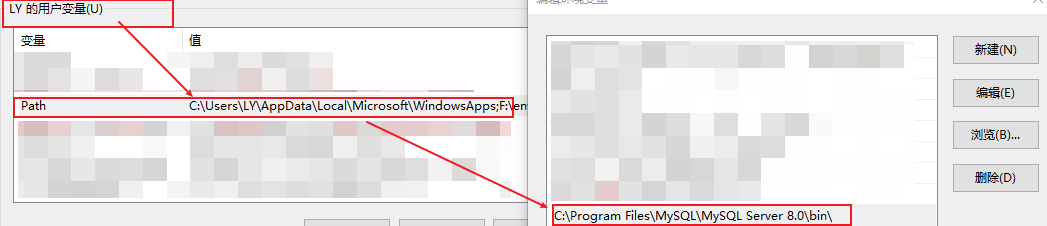

进入mysql环境的两种方式
在安装mysql路径下输入cmd
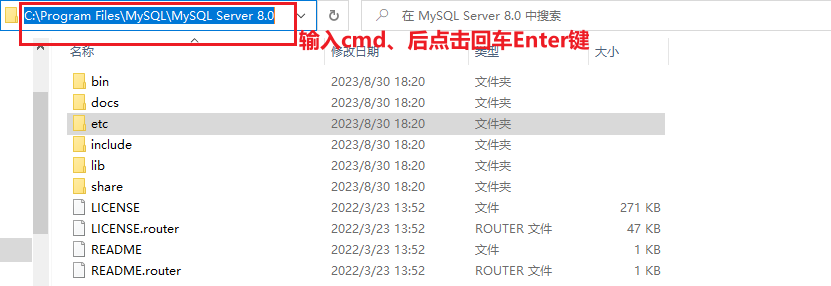
在配置环境变量后,以管理员方式进入终端
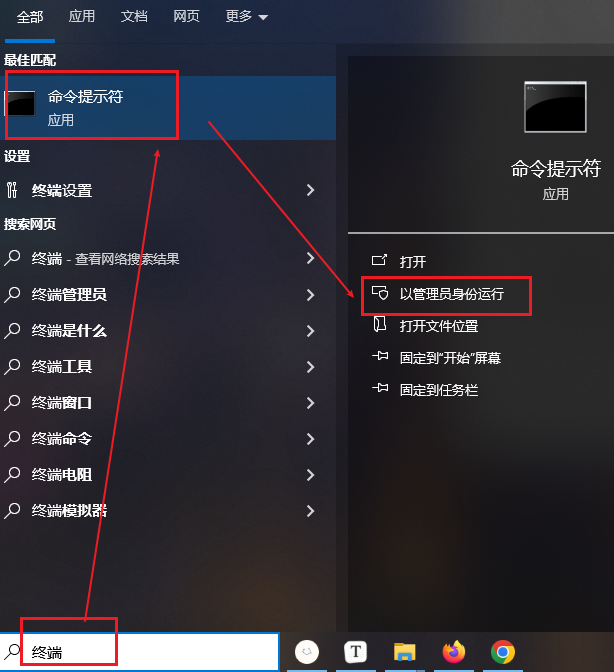
登录命令与修改密码
输入mysql -u root -p,敲敲回车Enter输入密码,进入mysql
mysql -u root -p
修改MySQL 密码命令:ALTER USER ‘用户’@‘localhost’ IDENTIFIED BY 新密码’;
用户一般为root
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
9.1
操作数据
数据的操作,即数据操纵语(Data Manipulation Language),简称DML
主要常用功能:增加insert,修改update,查询select,删除delete
| SQL语句 | 用法 |
|---|---|
| insert into 表名 values (‘值1’,‘值2’,‘值3’…),(‘值1’,‘值2’,‘值3’…)…; | 添加单行或多行数据 |
| update 表名 set 字段2=新值2,字段2=新值2… [where 条件]; | 修改某一或多字段的数据 |
| delete 表名 [where 条件] | 删除某个表或某行数据 |
| select * from 表名 [where 条件] | 查询在某个条件下的所有字段 |
| select 字段1,字段2,字段3… from 表名 [where 条件] | 根据条件修改 |
增加insert
数据添加时,都是整行添加,不能给一个字段添加数据
如果只是给某个字段添加数据,称为修改
给所有字段赋值
insert into 表名 values(‘值1’,‘值2’,‘值3’…); 需按表字段顺序添加
-- 添加一条记录到employee表中
insert into employee values('1005','张明','1389423452','2023-09-01','市场部','4000','23424@gfd')
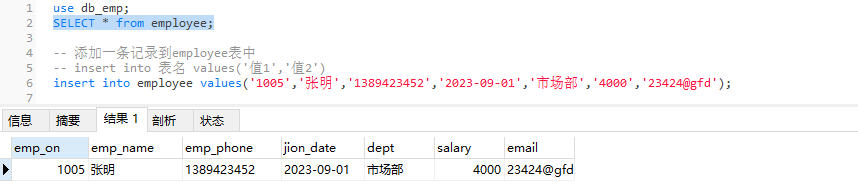
- 表名后无需添加字段名,添加时保证值的顺序和数量与表中的字段顺序和数量一致
- 遇到自增字段,不能省略不写,可以使用0、null或default让其填充自增值
- 遇到允许为空的字段,不能省略不写,使用null让其设置为空
- 遇到有默认值的字段,不能省略不写,使用default让其填充默认值
- 数据要满足数据类型和长度的要求,数值型的数据可以不用单引号,非数值必须要使用单引号
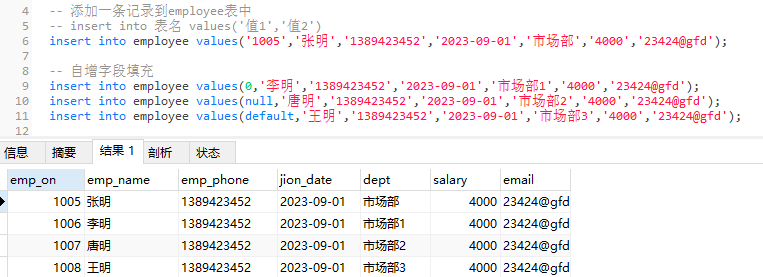
自增字段填充-‘0’、‘null’、‘default’
遇到自增字段不能省略写,可以用’0’、‘null’、‘default’,来填充自增值,建议使用’null’
-- 自增字段填充
insert into employee values(0,'李明','1389423452','2023-09-01','市场部1','4000','23424@gfd');
insert into employee values(null,'唐明','1389423452','2023-09-01','市场部2','4000','23424@gfd');
insert into employee values(default,'王明','1389423452','2023-09-01','市场部3','4000','23424@gfd');
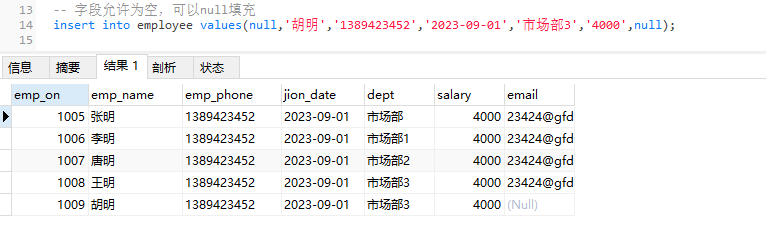
字段允许为空填充-‘null’
字段允许为空,则其值可以用’null’,来填充
insert into employee value(null,'胡明','1389423452','2023-09-01','市场部3','4000',null);
字段有默认值填充-‘defalut’
-
字段为数值型,可以省略’';非数值型不能省
-
字段有默认值约束,则其值可以用’defalut’,来填充
-- 字段为数值型,可以省略'';非数值型不能省
-- 字段有默认约束,可以default填充
alter table employee alter dept set default '研发部';
insert into employee values(null,'周明','1389423452','2023-09-01',default,4000,null);
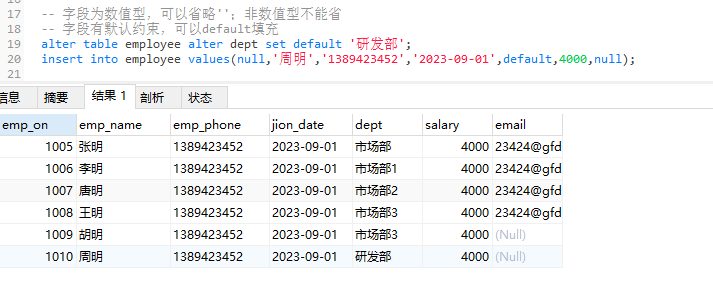
时间字段添加格式
-
纯数字——必须八位
-
存在切割符号,不要求必须八位
-- 时间
insert into employee values(null,'周明5','1389423452','20230901',default,4000,null);
insert into employee values(null,'周明6','1389423452','2023/9/1',default,4000,null);
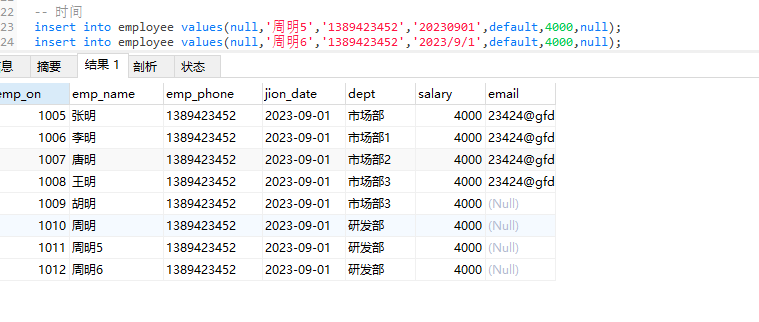
按指定的字段顺序赋值
insert into 表名(字段1,字段2…) values (‘值1’,‘值2’…)…;
- 一般要将所有非空字段写出来
- 可以不用写自增字段、有默认值的字段和允许为空的字段
- 值的顺序要和表名后的字段顺序一致
-- 自定义的字段和顺序赋值
insert into employee(emp_name,salary,emp_phone,jion_date) values('李往',3123,'12313414','20100701');
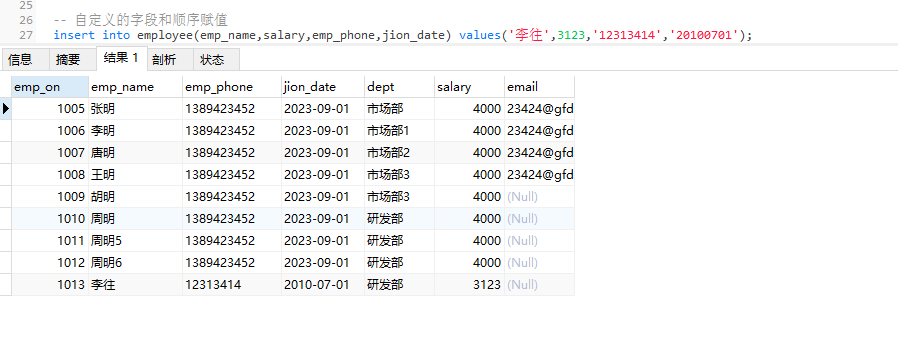
批量加载
可以用一个insert into语句添加多条记录
insert into 表名[(字段1,字段2…)] values (‘值1’,‘值2’…), (‘值1’,‘值2’…), … (‘值1’,‘值2’…);
insert into employee values
(null,'李往1','1389423452','20230901',default,4000,null),
(null,'李往2','1389423452','20230901',default,4000,null),
(null,'李往3','1389423452','20230901',default,4000,null),
(null,'李往4','1389423452','20230901',default,4000,null);
修改update
| SQL语句 | 用法 |
|---|---|
| update 表名 set 字段=‘值’; | 修改单个字段所有值 |
| update 表名 set 字段1 = ‘值’,字段2= ‘值’…; | 修改多个字段的所有值 |
| update 表名 set 字段1 = ‘值’,字段2= ‘值’… where 条件; | 根据条件修改 |
| update 表名 set 字段1 = ‘值’,字段2 = ‘值’… where 字段 = ‘值’; | 指定修改值 指定某个字段=某个 |
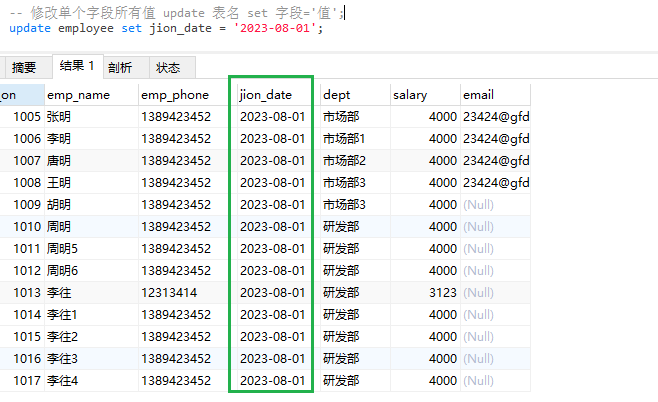
修改单个字段所有值,update 表名 set 字段=‘值’;
-- 修改单个字段所有值 update 表名 set 字段='值';
update employee set jion_date = '2023-08-01';
修改多个字段的所有值,update 表名 set 字段1=‘值1’,字段2=‘值2’…;
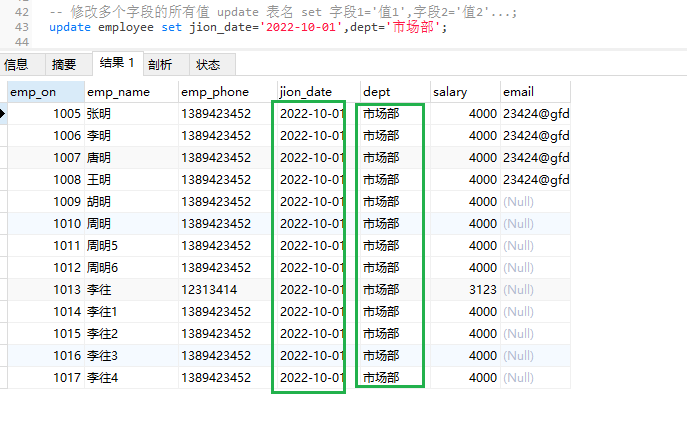
-- 修改多个字段的所有值 update 表名 set 字段1='值1',字段2='值2'...;
update employee set join_date='2022-10-01',dept='市场部';
根据条件修改
update 表名 set 字段1=‘值1’,字段2=‘值2’… where 条件;
| 条件 | 用法 |
|---|---|
| update 表名 set 字段1 = ‘值’,字段2 = ‘值’… where 字段 = ‘值’; | 指定值 |
| >、<、>=、<=、&&、||、and、or、between A and B、!、<> | 指定范围 |
| “字段 in (‘值1’,‘值2’…)”、“字段 not in (‘值1’,‘值2’…)” | 指定集合 |
| "字段 is null、 “字段 is not null” | 空值匹配 |
| %未知字符串、_一个字符 | 模糊查询 |
指定值
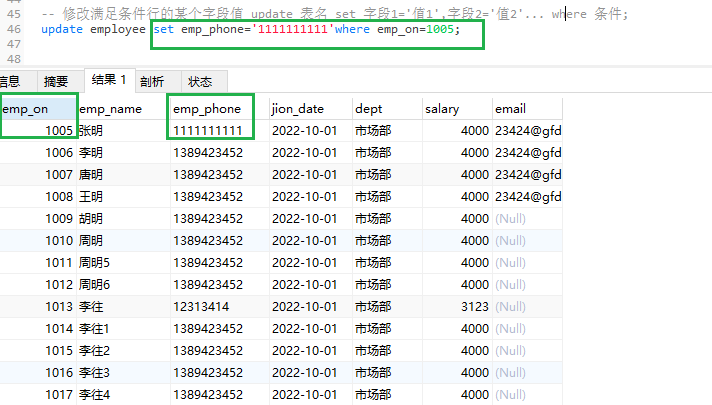
update 表名 set 字段1 = ‘值’,字段2 = ‘值’… where 字段 = ‘值’;
-- 修改编号为1005的,手机号为'1111111111'
update employee set emp_phone='1111111111'where emp_on=1005;
指定范围
- 使用>、<、>=、<=表示范围,使用&&、||、and、or将多个条件关联
- 使用"字段 between A and B"表示字段在[A,B]范围内
- 使用!=或<>表示不等于
-- 将工资小于4000的员工工资+2000
update employee set salary = salary +2000 where salary<4000;
-- 将工资在[4000,5000)的员工+200
update employee set salary = salary +200 where salary>=4000 and salary<5000;
-- 第二种写法
update employee set salary = salary +200 where salary>=4000 && salary<5000;
两端闭区间[n1,n2]:between n1 and n2
-- 两端闭区间[n1,n2]:between n1 and n2
-- 将工资在[5123,5200]的员工+200
update employee set salary = salary +200 where salary between 5123 and 5200;
!或<>,表示不等于
-- 将部门不是市场部的工资减100
update employee set salary =salary-100 where dept !='市场部';
指定集合
- 某个字段的值在某个集合中时,使用"字段 in (‘值1’,‘值2’…)"
- 某个字段的值不在某个集合中时,使用"字段 not in (‘值1’,‘值2’…)"
-- 为部门为'后勤部','营销部'的员工工资加200
update employee set salary =salary+200 where dept in('后勤部','营销部');
空值匹配
- 某个字段的值为空时,使用 “字段 is null”
- 某个字段的值不为空时,使用 “字段 is not null”
-- 将邮箱为空的员工,设置为'未设置'
update employee set email='未设置' where email is null;
模糊查询
- %表示未知长度的字符串,长度为[0,n)
- _表示一个字符
like ‘字符%’,以该字符开头
like ‘%字符’,以该字符结尾
-- 将姓王的员工入职时间改为2022-10-09
update employee set jion_date='2022-10-09' where emp_name like '王%';
-- 将姓王的员工入职时间改为2022-10-09
update employee set email='211112@dsghqaqwd' where emp_phone like '123%';
_:表示一个字符
-- 将姓周的两个字的员工工资减去-100
update employee set salary =salary-100 where emp_name like '周_';
%字符%,字符串中包含该字符
-- 将姓名中包含'明'字的员工工资减去-100
update employee set salary =salary-100 where emp_name like '%明%';
-- 带有指定字符 “鑫”
字段 like '%鑫%'
-- 姓"张"
字段 like '张%'
-- 以'的'结尾
字段 like '%的'
-- 两个字
字段 like '__'
-- 倒数第二个字为'好'
字段 like '%好_'
删除delete
物理删除
真实删除数据,删除数据是删除一条或多条记录
删除所有
delete from 表名; 与 truncate table 表名;
-- 删除所有
delete from employee;
-- 或
truncate table employee;
- delete会保留自增列删除前的值,删除后再添加时,自动从上次前的值开始自增
- truncate会重置自增列的值,删除所有数据时效率更高
- 删除主从关系设置的外键表中的数据,若从表中有数据,不能直接删除主表中相关联的数据, 需要先删除从表数据,再删除主表数据
条件删除
delete from 表名 where 条件
-- 条件删除
-- 删除入职时间为'2022-10-09'的员工记录
delete from employee where jion_date='2022-10-09';
时间数据类型,可比大小
-- 删除入职时间在'2022-10-01'之后员工记录
delete from employee where jion_date>'2022-10-01';
删除时的条件和修改时的用法相同
逻辑删除
不删除数据,只是不显示数据
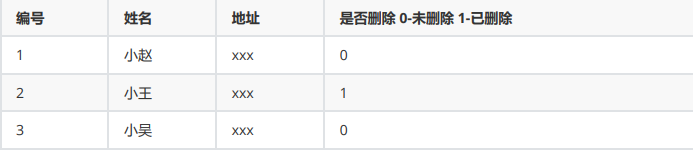
查询所有未删除的数据
select * from 表 where 是否删除=0
删除编号为2的信息。实际是将是否删除的值修改为1
update 表 set 是否删除=1 where id=2
查询select
| SQL语句 | 用法 |
|---|---|
| select * from 表名; | 查询所有字段 |
| select 字段1,字段2… from 表名; | 查询指定字段 |
| select 字段1 as ‘重命名’,字段2 ‘重命名’,字段3 重命名… from 表名 | 字段重命名 |
| limit N; limit N,M; | 从头查询到指定长N 从指定索引N查询到指定长度M |
| distinct 字段、 group by 字段 | 查询去重 |
| select * from 表 where 条件; | 条件查询 |
| select * from 表名 where 条件 order by 排序字段 排序规则,排序字段 排序规则… | 排序 |
| select 分组字段,统计函数 from 表名 group by 分组字段 | 分组 |
| group_concat()函数 | 分组后的数据拼接 |
查询所有字段、指定字段
查询所有字段:select * from 表名;
查询指定字段:select 字段1,字段2… from 表名;
建议使用指定字段查询,效率高于*
-- 查询所有字段
select * from hero;
-- 查询每一个人物的姓名和定位
select name,position from hero;
查询字段重命名
三种写法:
- 字段 as ‘重命名’
- 字段 ‘重命名’
- 字段 重命名
-- 查询每一个人的姓名和定位 对其重命名为中文
-- 写法一
select name as '姓名',position '定位' from hero;
-- 写法二
select name '姓名',position '定位' from hero;
-- 写法三
select name 姓名,position 定位 from hero;
查询指定条数limit
select *from 表名 limit n[数字]; ——表示前n条记录
-- 查询前3条记录 limit 数字
select *from hero limit 3;
select *from 表名 limit n[数字],m[数字];——从索引n开始,查询m条记录
-- 查询第1-4条记录
select *from hero limit 0,4;
-- 查询第5-8条记录
select *from hero limit 4,4;
翻页原理
每页显示size条记录,查询第page页的数据:page=(page-1)*size
select *from hero limit (page-1)*size,size;
查询去重
select distinct 字段 from 表名;
select 字段 from 表名 group by 字段;
-- 查询所有位置且去重
-- 方法一
select position from hero where position is not null group by position;
-- 方法二
select distinct position from hero where position is not null;
条件查询where
-- 查询价格小于4000的人物信息
select * from hero where price<4000;
-- 查询所有的男战士
select * from hero where sex='男' and position='战士';
-- 查询所有带有"琳"字的人物
select * from hero where name like '%琳%';
-- 查询在2023-9-1日之前治安的女性人物
select * from hero where create_date<'2023-9-1' and sex='女';
-- 查询姓名为4个字的人物的姓名与定位 重命名为中文
select name as '姓名',position '定位' from hero where name like '____' ;
排序
select * from 表名 where 条件 order by 排序字段1 排序规则1,排序字段2 排序规则2…
- 排序规则
- ase:升序
- dese:降序
- 排序时如果有条件,排序写在条件之后
- 多字段排序时,在order by之后写多个字段及排序规则,用逗号隔开,按顺序排序
-- 根据id降序显示 desc表降序
select * from hero order by id desc;
-- 根据价格升序显示 asc表升序,默认升序可省略
select * from hero order by price asc;
-- 根据女性角色价格升序显示
select * from hero where sex='女' order by price asc;
-- 将所有人物按价格升序,再按id降序
select * from hero order by price asc,id desc;
函数
select 函数(值);
select 函数(字段名) from 表;
数学函数
| 函数名 | 作用 |
|---|---|
| abs() | 绝对值 |
| pow() | 次幂 |
| sqrt() | 开平方 |
| round() | 四舍五入 |
| ceil() | 向上取整 |
| floor() | 向下取整 |
-- 数学相关
select abs(-11)
select pow(2,4)
字符串相关函数
| 函数名 | 作业 |
|---|---|
| length() | 得到字符串长度 |
| trim()/ltrim()/rtrim() | 去首尾/首/尾空格 |
| substr(字符串,start) | 从位置start开始截取字符串到末尾 |
| substr(字符串,start,len) | 从位置start开始截取len个字符 |
| left(字符串,len)/right(字符串,len) | 从首/尾开始截取len个字符 |
| lcase()/ucase() | 转换为小写/大写 |
| reverse() | 反转字符串 |
| concat(字符串1,字符串2…) | 按顺序拼接字符串 |
| replace(字符串,旧字符串,新字符串) | 将字符串中的旧字符串替换为新字符串 |
length(),长度
-- 数学相关
select abs(-11)
select pow(2,4)
trim()/ltrim()/rtrim(),去除空格
select trim(" hello world ")-- 'hello world'
select ltrim(" hello world ")-- 'hello world '
select rtrim(" hello world ")-- ' hello world'
substr(字符串,start),从start开始截取字符串到末尾,start指第几个
substr(字符串,start,len),从start开始截取len个字符串,start指第几个
left(字符串,len)/right(字符串,len),从头/尾截取len个字符串
-- 假设每个人第一个字是姓,其余均是名,取出人物的名
select substr(name,2) from hero;
-- 得到每个人物姓名的前两个字
-- 方法一
select substr(name,1,2) from hero;
-- 方法二
select substr(left,2) from hero;
concat(拼接1,拼接2,拼接3…) 字符串拼接,常用于模糊查询
-- 输出每个人物的定位和姓名 输出格式为:法师-张飞
select concat(position,'-',name) from hero where position is not null;
模糊查询,查询key:select * from hero where name like concat(‘%’,key,‘%’);
-- 根据动态变化的姓名关键字进行模糊查询
select * from hero where name like concat('%','琳','%');
replace(字符串,子字符,替换子字符)
-- 将姓名除了姓以外的文字用*代替
select replace(name,substr(name,2),'*') from hero;
时间相关函数
| 函数名 | 作业 |
|---|---|
| now() | 得到当前日期时间 |
| current_date/curdate() | 得到当前日期 |
| current_time()/curtime() | 得到当前时间 |
| year()/month()/day() | 得到年/月/日 |
| datediff(时间1,时间2) | 得到时间1与时间2相隔的天数 大的在前,小的在后 |
| timediff(时间1,时间2) | 得到时间1与时间2相隔的时分秒,有上限 |
| timestampdiff(时间单位,时间1,时间2) | 得到时间1与时间2相隔的时间单位 小的在前,大的在后 |
-- 日期时间
select now();
-- 日期
select current_date();
select curdate();
-- 时间
select current_time();
select curtime();
-- year()/month()/day()
select year(now())-- 年
select month(now())-- 月
select day(now()) -- 日
select hour(now()) -- 小时
-- 输出每个人物已创建了多少年
select name,year(now())-year(create_date) age from hero;
练习
-- 模拟身份证'500123199906252154' 输出年龄’
-- substr('500123199906252154',7,4)取出1999
select year(now()) - substr('500123199906252154',7,4);
两个之间相隔的天数,datediff(时间1,时间2) ,时间1-时间2
两个之间相隔的时间,timediff(now(),时间2),时间1-时间2
两个之间相隔的时间单位,timestampdiff(时间单位,时间1,时间2),时间2-时间1
-- 两个之间相隔的天数datediff()
select name,datediff(now(),create_date) day from hero;
-- 两个之间相隔的时间timediff() 存在上限
select timediff(now(),'2023-08-31 00:00:00') time;
-- timestampdiff(时间单位,时间1,时间2)
select TIMESTAMPDIFF(YEAR,'2003-08-31 00:00:00',now())
select TIMESTAMPDIFF(HOUR,'2003-08-31 00:00:00',now())
统计函数(聚合函数)
| 函数名 | 作用 |
|---|---|
| sum() | 求和 |
| avg() | 平均值 |
| count() | 计数 |
| max() | 最大 |
| min() | 最小 |
-- 输出所有人物的平均价格
select avg(price) from hero;
-- 输出女性人物数量
select count(id) 数量 from hero where sex='女';
-- 输出法师的最高价格
select max(price) from hero where position='法师';
-- 输出战士与辅助的价格之后
select sum(price) from hero where position in ('战士','辅助');
分组
select 分组字段,统计函数 from 表名 group by 分组字段
-- 查询不同性别的人物数量
select sex,count(id) from hero group by sex;
-- 查询不同定位的人物平均价格
select position,round(avg(price)) 平均值 from hero where position is not null group by position;
- 按指定的字段进行分组,会将该字段值相同的数据归纳到同一组中
- 分组通常配合统计函数使用
- 若统计函数作为条件,不能使用where,而要将条件写在having之后,且having子句写在最后
having子句,统计函数作为条件时
-- 按定位分组,输出组员人员大于2的名称和人数
select position,count(id) from hero where position is not null group by position having count(id)>2;
-- 按性别分组,输出组员人数大于五的组的性别和人数
select sex 性别,count(id) 人数 from hero group by sex having count(id)>5;
group_concat() ,将分组后的字段进行拼接
组内元素与元素之间,默认以逗号(,)分割
-- 对分组后的字段进行拼接
select position,group_concat(name) from hero group by position;
select position,group_concat(name,'-',sex) from hero group by position;

练习
select * from employee;
-- 查询所有员工的姓名、入职年数
select emp_name 姓名,TIMESTAMPDIFF(year,jion_date,now()) 入职年数 from employee;
-- 按部分分组、查询每组的人数、平均工资
-- 分组GROUP BY
select dept,count(emp_on) 人数,avg(salary) 平均工资 from employee GROUP BY dept;
-- 查询所有员工的平均工资、最高工资、最低工资
SELECT AVG(salary) 平均工资,max(salary) 最高工资,min(salary) 最低工资 from employee;
-- 查询每个员工的姓名、电话、将电话的中间四位用*
SELECT emp_name,REPLACE(emp_phone,substr(emp_phone,4,4),'*') 电话 from employee;
-- 查询所有员工的姓、工资、按工资降序
-- substr(emp_name,1,1) left(emp_name,1)
SELECT CONCAT(left(emp_name,1),'老师') 姓,salary from employee ORDER BY salary DESC;
-- 输出"实习员工"的所有信息,入职月份小于3个月为实习
-- TIMESTAMPDIFF(MONTH,jion_date,now())
SELECT * from employee where TIMESTAMPDIFF(MONTH,jion_date,now())<3;
SELECT * from employee where DATEDIFF(now(),jion_date)<90;
-- 查询人数大于3的部门和人数
SELECT dept,count(emp_on) from employee GROUP BY dept HAVING count(emp_on)>3;
SQL注入
利用sql语句拼接后,导致原本sql失去本意的漏洞
-- 使用姓名和手机登录 如果能查询出结果则进入系统
-- 如果有一个条件不满足,查询结果为空
select * from employee where emp_name='aw' and emp_phone='123'
-- 王茂鑫 18523473566
select * from employee where emp_name='王茂鑫' and emp_phone='18523473566'
-- "' or 1=1 -- "
select * from employee where emp_name='' or 1=1 -- ' and emp_phone=''
’ or 1=1 – 若将这个字符串作为用户名输入时,会导致sql语句异常,查询出全部数据
转存中…(img-CAnSfmz7-1694240163214)]
练习
select * from employee;
-- 查询所有员工的姓名、入职年数
select emp_name 姓名,TIMESTAMPDIFF(year,jion_date,now()) 入职年数 from employee;
-- 按部分分组、查询每组的人数、平均工资
-- 分组GROUP BY
select dept,count(emp_on) 人数,avg(salary) 平均工资 from employee GROUP BY dept;
-- 查询所有员工的平均工资、最高工资、最低工资
SELECT AVG(salary) 平均工资,max(salary) 最高工资,min(salary) 最低工资 from employee;
-- 查询每个员工的姓名、电话、将电话的中间四位用*
SELECT emp_name,REPLACE(emp_phone,substr(emp_phone,4,4),'*') 电话 from employee;
-- 查询所有员工的姓、工资、按工资降序
-- substr(emp_name,1,1) left(emp_name,1)
SELECT CONCAT(left(emp_name,1),'老师') 姓,salary from employee ORDER BY salary DESC;
-- 输出"实习员工"的所有信息,入职月份小于3个月为实习
-- TIMESTAMPDIFF(MONTH,jion_date,now())
SELECT * from employee where TIMESTAMPDIFF(MONTH,jion_date,now())<3;
SELECT * from employee where DATEDIFF(now(),jion_date)<90;
-- 查询人数大于3的部门和人数
SELECT dept,count(emp_on) from employee GROUP BY dept HAVING count(emp_on)>3;
SQL注入
利用sql语句拼接后,导致原本sql失去本意的漏洞
-- 使用姓名和手机登录 如果能查询出结果则进入系统
-- 如果有一个条件不满足,查询结果为空
select * from employee where emp_name='aw' and emp_phone='123'
-- 王茂鑫 18523473566
select * from employee where emp_name='王茂鑫' and emp_phone='18523473566'
-- "' or 1=1 -- "
select * from employee where emp_name='' or 1=1 -- ' and emp_phone=''
’ or 1=1 – 若将这个字符串作为用户名输入时,会导致sql语句异常,查询出全部数据















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









