






源代码下载链接(复制粘贴可通过头歌测试):链接
自上而下的语法分析器
语法分析在编译中是一个重要的环节,语法分析可以分为自上而下分析和自下而上分析两种方式。
自上而下分析法是从文法开始符号开始,不断进行推导,直到推导所得的符号串与输入串相同为止。简单来解释这句话:我们有一个既定的文法,和一个需要分析的符号串。接下来我们从文法的开始符号出发,反复地使用文法规定的一些产生式匹配符号串的每一个符号,直到所得的符号串和待分析的符号串相同,则为分析成功,反之匹配不成功。
下面我们举例来进行说明: 我们有文法G(E): E→aF F→b|c 以及待输入的字符 ab,从文法开始符号E出发,E→aF,a匹配成功后,指针指向F,找非终结符F的产生式合适的候选式 b匹配,于是匹配成功。
想要对一个文法进行自上而下的分析,要消除文法的二义性,消除左递归,提取左公共因子,计算FIRST集合和FOLLOW集合,判断文法是否为LL(1)型文法,一个文法经过这些步骤,并且是LL(1)文法,则可以用LL(1)分析法的具体实现去分析。我们在后续的实验步骤中会进行该过程的一一实验。
预测分析法
预测分析法是LL(1)分析法的一种实现方法,它通过一张表来关联非终结符和终结符,这张表就是预测分析表,预测分析表可以说是预测分析法的核心部分。我们在进行该方法时,首先要构建预测分析表。
首先介绍一下预测分析表的结构,简单来说他就是一张表,表的两个属性分别是非终结符和终结符(包括‘#’),形如:
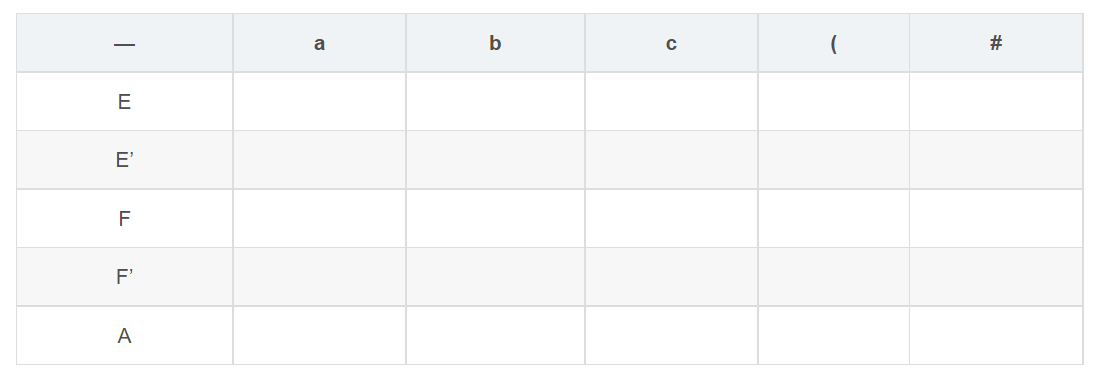
其中对应的内容是产生式的形式,若是没有产生式则可以写入标记来表示其匹配不到具体的产生式,进入报错处理程序。
在根据文法构造预测分析表时需要扫描全部产生式:
- 计算产生式的右部的FIRST集合,如果求出来的FIRST集合中包含终结符,那么就把这条产生式放入对应非终结符和终结符的格子中
- 如果ε在FIRST集合中,则计算该非终结符的FOLLOW集合,如果求出来的FOLLOW集合中包含终结符,那么就把这条产生式放入对应的非终结符和终结符的格子中
当预测分析表构造完成后,我们便可以运用预测分析法进行语法分析了。我们使用用一个栈来存放过程数据,主要步骤如下:
- 获取栈顶的元素A,获取输入串目前指针指向的元素a
- 若A = ‘#’ ,a = ‘#’ 则匹配成功
- 若A = a 但是A和a不为’#’,则pop栈顶元素,输入串指针+1
- 若A为非终结符,这查询预测分析表,把由A和a确定的产生式的右部从右往左依次压入到栈中,若右部是ε,那就不做操作
- 查找预测分析表得到预设的出错字符则调用error()
实验步骤
根据语法分析器的一般功能,我们的程序应具有如下的要求及实验步骤:
- 定义目标语言的语法规则;
- 求解预测分析方法需要的符号集和分析表;
- 依次读入测试用例,根据预测分析的方法进行语法分析,直到源程序结束;该部分具体见上。
- 对遇到的语法错误做出错误处理。
下面我们对步骤1,2进行说明。
目标语言的语法规则
该部分重点在于消除文法的二义性,消除左递归,提取左公共因子。想要让程序自动地消除左递归,具体的做法如下: 1.把文法的所有非终结符进行排序S = [‘A’,‘B’,…] 2.做一个嵌套循环: 其中S[k]为排在S[j]之后的非终结符,bunch_i为非终结符和终结符组成的串
for j in range(len(s)):for k in range(j):原产生式中:S[j]→S[k]bunch_1的S[k]用其对应的产生式代替S[k]→bunch_2|bunch_3|...推出:S[j]→bunch_2 bunch_1|bunch_3 bunch_1|...如此,做完循环后该文法若有间接左递归,就将其转换成直接左递归了消除直接左递归,具体做法见上文循环结束后删除无用产生式
求解预测分析方法需要的符号集和分析表
符号集主要是构造FIRST集和FOLLOW集,其主要目的是为了消除回溯,也就是选择候选式的时候能够更加准确,当然,这些集合在别的地方也有用处。
构造FIRST集: 扫描所有的产生式,对于每一个X,连续使用以下规则,直至每个集合的FIRST集合不再增大为止,每一遍扫描所有产生式如果有FIRST集合变化则重新扫描:
- 如果X是终结符,则FIRST(X) = {X}.
- 如果X是非终结符 ,且有产生式 X → a… 则把a加入到FIRST集合中. 若 X → ε也是其中一条产生式,则把ε也加入到FIRST集合中.
- 如果X是非终结符,且 X → Y… 是一条产生式,其中Y是非终结符,那么则把FIRST(Y) \ {ε}(即FIRST集合去除ε)加入到FIRST(X)中.
构造FOLLOW集: 扫描所有产生式.对于文法G的每一个非终结符A构造FOLLOW(A)可以连续使用以下规则,直至每一个FOLLOW集合不在增大为止:
- 对于文法的开始符号S,置 # 于FOLLOW(S)中.
- 若有产生式 A → αBβ,其中α和β是非终结符和终结符构成的串,B为非终结符,则把FIRST(β) \ {ε}加入到FOLLOW(B)中.
- 若有产生式 A → αB 或 A → αBβ ε∈FIRST(β) ,则把FOLLOW(A)加入到FOLLOW(B)中.
分析表的构成见上所述。
编程要求
根据提示,在右侧编辑器补充代码,运行程序,进行结果对比。
测试说明
测试输入的格式为:
E T F+ * ( ) iE->E+T|TT->T*F|FF->(E)|i(i)*i(i)*iii















 3967
3967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









