






头歌过关实验代码链接(粘贴可过关):链接
检查实验代码(过关代码):基于头歌实验修改。
http://generatelink.xam.ink/change/makeurl/changeurl/10660
任务描述
本关任务:加深对语法分析器工作过程的理解;加强对算符优先分析法实现语法分析程序的掌握;能够采用一种编程语言实现简单的语法分析程序;能够使用自己编写的分析程序对简单的程序段进行语法翻译。
相关知识
为了完成本关任务,你需要掌握:用算符优先法编制语法分析程序。
自下而上的语法分析器
语法分析在编译中是一个重要的环节,语法分析可以分为自上而下分析和自下而上分析两种方式。
自下而上分析法是一种“移进-归约”法。这种方法的大意是,用一个寄存符号的先进后出栈,把输入符号一个一个地移进到栈里,当栈顶形成某个产生式的一个候选式时,即把栈顶的这一部分替换成(归约为)该产生式的左部符号。
对于自下而上的分析法,边输入单词符号(移进符号栈),边归约。也就是在从左到右移进输入串的过程中,一旦发现栈顶呈现可归约串就立即进行归约。
在该类方法中有以下的几个处理:
-
移进:指把输入串的一个符号移进栈。
-
归约:指发现栈顶呈可归约串,并用适当的相应符号去替换这个串(这两个问题都还没有解决)。
-
接受:指宣布最终分析成功,这个操作可看作是“归约”的一种特殊形式。
-
出错处理:指发现栈顶的内容与输入串相悖,分析工作无法正常进行,此时需调用出错处理程序进行诊察和校正,并对栈顶的内容和输入符号进行调整。
算符优先法
算符优先分析法(Operator Precedence Parse)是一种移动归约分析方法,它是仿效四则运算的计算过程而构造的一种语法分析方法。算符优先分析法的关键是比较两个相继出现的终结符的优先级而决定应采取的动作。
算法优先关系构造的构造遵循以下的步骤:
首先对于优先关系进行如下定义:
a的优先级低于ba < b: 文法中有形如A→…aB…的产生式而B+b…或B+Cb…- a的优先级等于b
a = b: 文法中有形如A→…ab…或者A→…aBb…的产生式 - a的优先级高于b
a > b: 文法中有形如A…Bb…的产生式,而B+…a或B+…aC - 算符的优先关系是有序的
如果a > b,不能推出b < a
如果a > b,有可能b > a
如果a > b,b > c,不一定a > c
根据这个大小关系的定义,我们知道为了确定两个终止符的优先关系,我们需要知道它的在所有的产生式中和前后非终止符的关系,那么我们做一个如步骤二的预处理。
定义并构造FIRSTVT和LASTVT两个集合
FIRSTVT(P)={a∣P⇒+a⋯或P⇒+Qa⋯}
LASTVT(P)={a∣P⇒+⋯a0P⇒+…aQ}
- FIRSTVT(P)直接根据定义递归的构造即可:
- 若有产生式
P→a⋯或p→Qa⋯,则a∈FIRSTVT(P) - 若有产式
P→Q⋯,若a∈FIRSTVT(Q),则a∈FIRSTVT(P)
- LASTVT(P)直接根据定义递归的构造即可:
- 若有产生式
P→⋯ 或 p→⋯⋅a则a∈LASTVT(P) - 若有产式
P→⋯, 若a∈LASTVT(Q)则a∈LASTVT(P)
利用FIRSTVT和LASTVT集合构造算法优先关系表:
FOR 每个产生式 P->X1 X2 ……XnDO FOR i:=1 TO n-1 DOIF X[i]和X[i+1]均为终结符THEN 置 X[i]=X[i+1]IF X[i]和X[i+2]均为终结符,X[i+1]为非终结符,i≤n-2,THEN 置 X[i]=X[i+2]IF X[i]为终结符, 但X[i+1]为非终结符THEN FOR FIRSTVT(X[i+1])中的每个aDO 置 X[i]<aIF Xi为非终结符, 但X i+1 为终结符THEN FOR LASTVT(X i )中的每个aDO 置 a>X[i+1]
实验步骤
- 对语法规则有明确的定义;
该部分需要我们对输入文法进行构造,然后定义出算符之间的优先级,构造算符优先关系表,表的构造过程如上。 - 编写的分析程序能够对测试用例进行正确的语法分析;
该部分需要我们对于输入的字符串进行逐一判断,并给出相应的解析过程,该过程是一个移进,归约,接受及出错处理的操作过程。 - 对于遇到的语法错误,能够做出简单的错误处理,给出简单的错误提示,保证顺利完成语法分析过程;

- 测试数据及运行结果展示
- 成功案例:
- 输入文法:
- S->#E#
- E->E+T|T
- T->T*F|F
- F->(E)|i
- @
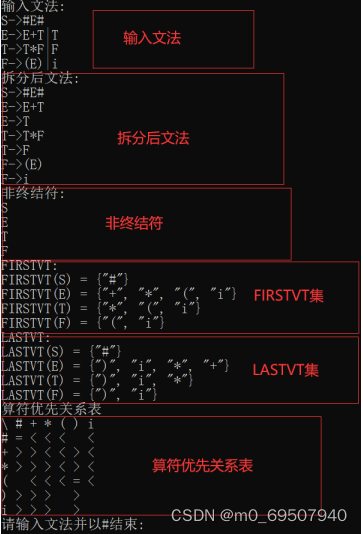
- 输入文法:
- 成功案例:
-
ii:输入要检测的字符串:i+i*(i+i)#
-
分析完成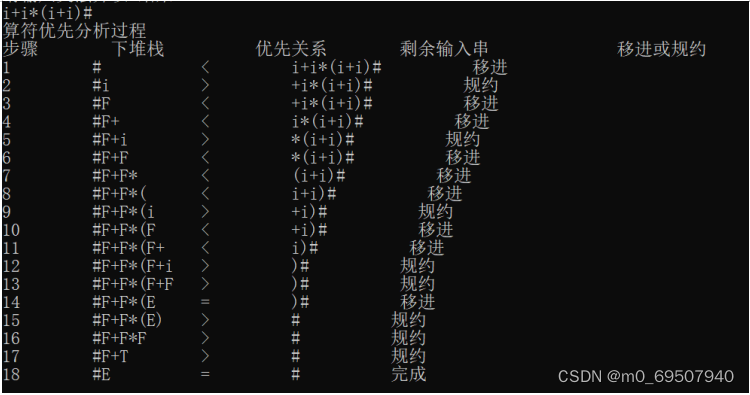
-
- 失败案例:
- 输入字符串:i+i*(+i)#

- 失败案例:
-
分析完成,不符合文法















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









