







针对深度学习,要想训练好一个模型,首先要会建立并读懂数据集的加载,我也看了很多大佬发的讲解版本,接下来针对我的理解给大家解读一下我自己理解的数据集的建立的过程
如果你觉得我写得不错,不要忘记点个赞哦
首先大家要知道在pytorch中构建数据集的基本框架:
class Mydataset(object):
def __init__(self):
""""""""""
def __getitem__(self,index):
""""""""""
def __len__(self):
return(len())首先第一个init是对我们所用到的一些参数进行初始化,在这个阶段需要加载一些地址,比如图像分割中需要加载img和对应的label;第二个getitem函数,利用index遍历init当中储存的地址,并利用cv2.imshow()或PIL.Image.open()读入图像;第三个函数是len函数,它的作用是返回数据集的长度,这个三个函数构成了构建数据集的基本框架,缺一不可。
接下来我们就详细的展开说说:
一、读入数据
为了读入数据方便快捷,很多文章都是先将我们的图像数据的地址或名称存储在txt文件中,方便后续的读入,刚开始我也对着生成的txt文件的代码研究了好久,一行一行的解析功能,接下来带着大家一起看一下,其实还是很简单的。
首先,我在我的路径下建立了两个文件夹,images和labels,里面分别放有30张图片和对应的标签


之后我们建立一个名为utils的py文件,代码如下,我在里面逐句解释。
from torchvision import transforms
import os
path = './images/'##这个是储存image的相对路径,如果是生成label的txt
##需要将此处更改为对应label的相对路径
root = []##建立一个列表用于存储之后提取到的地址
def photo_text(path, name):##定义提取地址的函数
table = os.listdir(path)##os.listdir的作用是返回指定路径下所有文件和文件夹的名字,放于列表中
for i in table:
root.append(path + i)##在列表里存入每个图片的相对路径
try:
with open(path + name, 'w', encoding='utf-8') as f:##open函数用于建立一个名为name的
##txt文件
for j in root:##循环遍历得到的所有图片的相对路径
f.write(j + '\n')##将每个图片相对路径都写入txt文件中
except:
os.remove(path + name)##如果有txt文件与我们重名,则需要先删掉它,再建立
with open(path + name, 'w', encoding='utf-8') as f:
for j in root:
f.write(j + '\n')
if __name__ == '__main__':
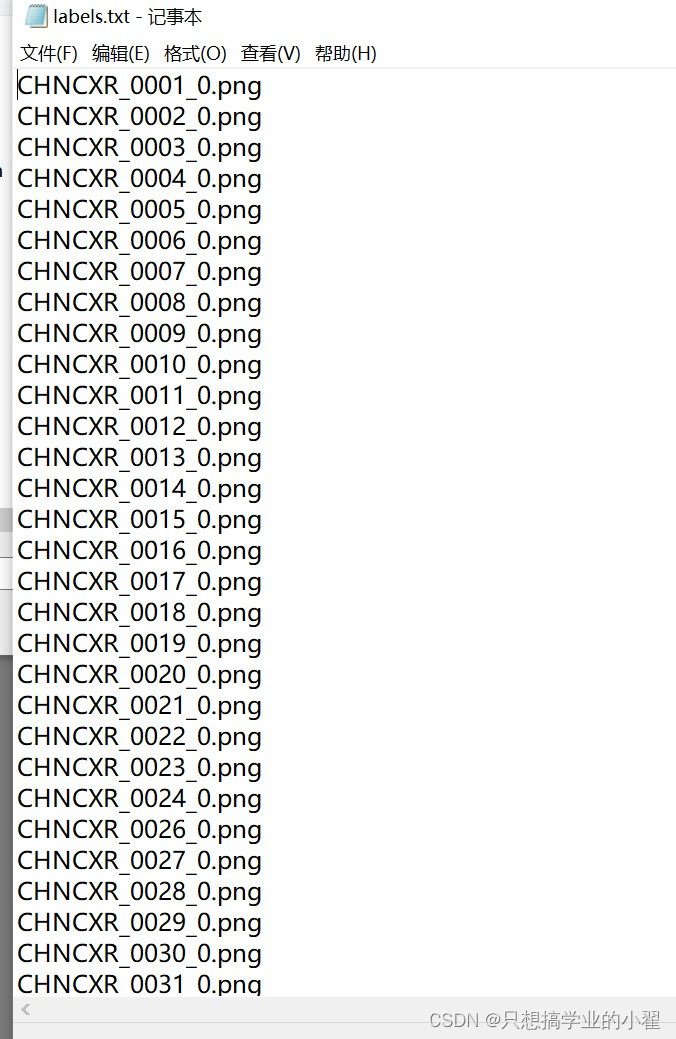
photo_text(path, 'images.txt')##这一步就是执行上面创立好的函数image和label都执行完后,在每个文件夹中会多一个txt,如下图所示
二、建立Dataset
接下来就到了我们正式建立的时候啦,直接放代码,老样子,每句我都会解释意义
from PIL import Image
from torch.utils.data import DataLoader
from torchvision import transforms
import torch
import numpy as np
import cv2
# 创建数据集
class MyDataset(torch.utils.data.Dataset): # 创建自己的类:MyDataset,这个类是继承的torch.utils.data.Dataset
def __init__(self, root_img, datatxt_img, root_label,datatxt_label,transform=None):
# 初始化一些需要传入的参数,如图像和label的相对路径
#root_img、root_label就是指相对路径
#datatxt_img、datatxt_label就是指相对路径下,刚刚生成的txt的文件名
#transform则是指需不需要将图片转换为tensor数据类型,一般情况都是需要的,因为cv2读入的
#图片格式是numpy,而PIL读入的格式是PIL,所以要将其转换为tensor数据类型以便之后操作,
#具体的transform在下面有声明,这里我们默认为没有此操作。
super(MyDataset, self).__init__()##这句是必须要写的,我也不太清楚是为什么
fh_img = open(root_img + datatxt_img, 'r', encoding='utf-8')
#打开image下的txt文件读入,这里的r是read的简写,代表文件只读
fh_label = open(root_label + datatxt_label, 'r', encoding='utf-8')
#与上同理
imgs = [] # 创建一个名为img的空列表,一会儿用来装image.txt文件中的每个图片的相对路径
labels=[] # 与上同理,创建一个名为labels的空列表
for line in fh_img: # 按行循环txt文本中的内容
line = line.rstrip() # 删除 本行string 字符串末尾的指定字符
words = line.split() # 通过指定分隔符对字符串进行切片,默认为所有的空字符,包括空
# 格、换行、制表符等
imgs.append((words[0])) # 把txt里的内容读入imgs列表保存,具体是words几要看txt内
# 容而定
for line in fh_label: #与上同理,一个是在image.txt操作,一个是在label.txt操作
line = line.rstrip()
words = line.split()
labels.append((words[0]))
self.imgs = imgs
self.label=labels
self.transform = transform
def __getitem__(self, index):
# 这个方法是必须要有的,用于按照索引读取每个元素的具体内容
img = self.imgs[index] # 利用index索引获得每一张图片的名字
label=self.label[index]# 同理获得每个label的名字
img = Image.open(img).convert('RGB') # 按照path读入图片from PIL import Image # 按
# 照路径读取图片
label= Image.open(label)
if self.transform is not None:##判断是个否进行tensor类型的转变,如果有则执行
img = self.transform(img) # 是否进行transform
label = self.transform(label) # 是否进行transform
return img, label # return很关键,返回我们读入的数据文件
def __len__(self): # 这个函数也必须要写,它返回的是数据集的长度
return len(self.imgs)
####开始运行#####
root_img = './images/'##写入image的相对路径
root_label = './labels/'
# 数据预处理。transforms.ToTensor()将图片转换成PyTorch中处理的对象Tensor
data_tf = transforms.Compose(
[transforms.ToTensor()])
# 个人数据装载
train_data = MyDataset(root_img, 'images.txt', root_label,'labels.txt',transform=data_tf)如果想验证是否读入成功,可以运行以下代码
img,label=train_data[1]##加载其中一个数据,因为我们在getitem设置的返回值是img和label
##所以要用两个变量接收
a2 = transforms.ToPILImage()##由于接收到的是tensor类型,如果想用PIL显示要进行数据转化
img_tensor = img.float() # 满足类型需求,将数据改为浮点型
img_PIL = a2(img_tensor)
img_PIL.show()##最后展示即可,如果能出现图像,则证明是加载成功有些小伙伴想用opencv的方法读取数据,也是可以的,代码期待我下篇的笔记哦~~,如果你觉得还不错,点个赞给我,下一篇我将继续讲解建立dataset后如何使用Dataloader以及可视化,还会帮助大家区分cv2和PIL读入图像类型的转化。















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









